2020-2021-1 期末试卷B和答案¶
院系:_ 年级:_ 专业:__
姓名:_ 学号:_ 成绩:__
(B)卷共页 考试形式闭卷
一、填空题 (24分)¶
- 正确率(Precision)是返回结果文档中【正确】的比例。如返回100篇文档,其中20篇相关,正确率【 \(1/5\)】;召回率(Recall)是全部【相关】文档中被返回的比例。如返回150篇文档,其中20篇相关,但是总的相关文档是100篇,召回率【 \(1/5\)】;(8分)
- 信息检索系统的目标是【较少】消耗情况下【尽快】、【全面】返回准确的结果。(6分)
- 概率检索模型是通过【概率】的方法将查询和文档联系起来。(2分)
- 两个字符串编辑距离是指从一个转换成另一个所需要的【最短的基本操作】数目。(2分)
- 查询似然模型把相关度看成是每篇文档对应的语言下【生成】该查询的【可能性】。(2分)
- 文档的模型(风格)实际上是某种总体分布,文档和查询都是该总体分布下的一个【抽样样本实例】,根据文档,估计【文档的模型】,即求出该总体分布。(4分)
二、计算题 (22分)¶
1. 对于如下文档集
doc1: Mary is going to the park.
doc2: John plays basketball in the park
doc3: Mary and John are from NewYork.
doc4: NewYork is a big city.
1.1 请写出构建倒排索引的详细过程 (5分)
1.2. 请写出 Mary AND John的查询过程 (2分)
1.3. 请写出 park OR city 的查询过程 (2分)
解题思路:
- 步骤:1) 词条序列化;2) 排序;3) 合并;4) 得到词典和倒排记录表
- 请写出 Mary AND city 的查询过程:
- 取出 Mary 的倒排记录表
- 取出 city 的倒排记录表
- 求交集
- 请写出 basketball OR city 的查询过程:
- 和上面类似
2. 给定训练文档集和测试文档集,请利用朴素贝叶斯方法对文档进行分类。(8分)
| 数据集 | docID | words in document | in c = China? |
|---|---|---|---|
| training set | 1 | Chinese Beijing Chinese | yes |
| 2 | Chinese Chinese Shanghai | yes | |
| 3 | Chinese Macao | yes | |
| 4 | Tokyo Japan Chinese | no | |
| test set | 5 | Chinese Chinese Chinese Tokyo Japan | ? |
解题思路:
采用加一平滑: \(\hat{P}(t|c)=\frac{T_{ct}+1}{\sum_{t^{\prime}\in V}(T_{ct^{\prime}}+1)}=\frac{T_{ct}+1}{(\sum_{t^{\prime}\in V}T_{ct^{\prime}})+B}\)
Priors: \(\hat{P}(c)=3/4\) and \(\hat{P}(\overline{c})=1/4\)
Conditional probabilities:
\(\hat{P}(CHINESE|c)=(5+1)/(8+6)=6/14=3/7\)
\(\hat{P}(TOKYO|c)=\hat{P}(JAPAN|c)=(0+1)/(8+6)=1/14\)
\(\hat{P}(CHINESE|\overline{c})=(1+1)/(3+6)=2/9\)
\(\hat{P}(TOKYO|\overline{c})=\hat{P}(JAPAN|\overline{c})=(1+1)/(3+6)=2/9\)
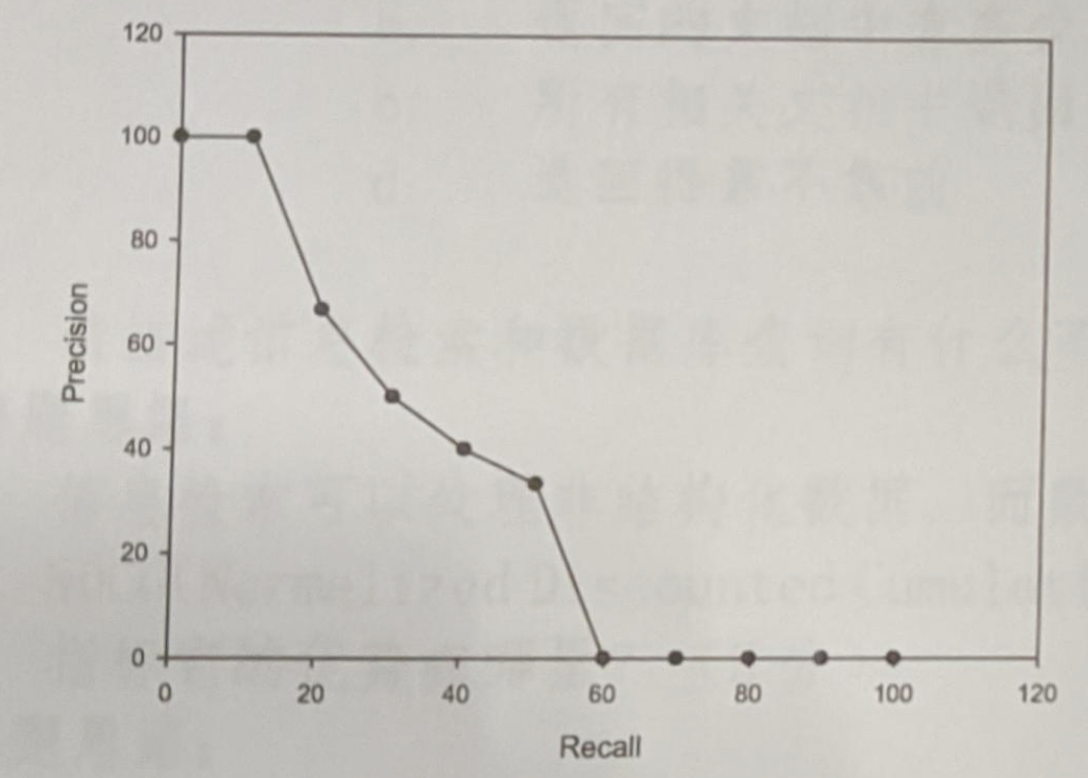
3. 某个查询q的标准答案集合为: \(Rq=\{d3,d5,d9,d25,d39,d44,d56,d71,d89,d123\}\)
某个IR系统对q的检索结果如下,请计算相关P和R值,画出插值 P-R 曲线。(6分)
| 1. d123 | 6. d9 | 11. d38 |
|---|---|---|
| 2. d84 | 7. d511 | 12. d48 |
| 3. d56 | 8. d129 | 13. d250 |
| 4. d6 | 9. d187 | 14. d113 |
| 5. d8 | 10. d25 | 15. d3 |
解题思路
| 1. d123 (\(R=0.1, P=1\)) | 6. d9 (\(R=0.3, P=0.5\)) | 11. d38 |
|---|---|---|
| 2. d84 | 7. d511 | 12. d48 |
| 3. d56 | 8. d129 | 13. d250 |
| 4. d6 | 9. d187 | 14. d113 |
| 5. d8 | 10. d25 (\(R=0.4, P=0.4\)) | 15. d3(\(R=0.5, P=0.33\)) |
三、简答题 (54分)¶
1. 信息检索的应用领域举例5种应用并简要说明。(5分)
解题思路: 搜索、推荐、舆情分析、国防情报、内容安全。
2. 怎么支持短语查询。(6分)
解题思路:
- 双词(Biword)索引;扩展双词将词项进行组块,每个组块包含名词(N)和冠词/介词(X),称具有NX*N形式的词项序列为扩展双词(extended biword)
- 带位置信息索引。
3. 布尔检索模型的缺点。(5分)
解题思路: 布尔查询构建复杂,不适合普通用户。构建不当,检索结果过多或者过少。
- 没有充分利用词项的频率信息。
- 不能对检索结果进行排序。
4. 大规模文档集中相关文档很难获得,因此影响召回率计算。例举一种能获得相关文档集的方法。(5分)
解题思路: pooling 的方法。
5. 搜索引擎会不会采用相关反馈,为什么?(5分)
解题思路: 不会。
- 相关反馈开销很大。
- 相关反馈生成的新查询往往很长。
- 长查询的处理开销很大。
- 用户不愿意提供显式的相关反馈。
- 很难理解,为什么会返回(应用相关反馈之后)某篇特定文档。
6. 信息检索评价体系里面的效率和效果分别是什么?(6分)
解题思路:
- 效率 (Efficiency) — 可以采用通常的评价方法:
a. 时间开销
b. 空间开销
c. 响应速度
- 效果 (Effectiveness):
a. 返回的文档中有多少相关文档
b. 所有相关文档中返回了多少
c. 返回得靠不靠前
7. 请描述信息检索和数据库查询有什么不同?(5分)
解题思路: 信息检索可以处理非结构化数据,而数据库查询则主要处理结构化数据。
8. NDCG (Normalized Discounted Cumulative Gain) 评价指标相比于 Precision-Recall 指标它的优势在哪里?(5分)
解题思路: 每个文档不仅仅只有相关和不相关两种情况,而是有相关度级别,比如0,1,2,3。我们可以假设,对于返回结果:
a. 相关度级别越高的结果越多越好
b. 相关度级别越高的结果越靠前越好
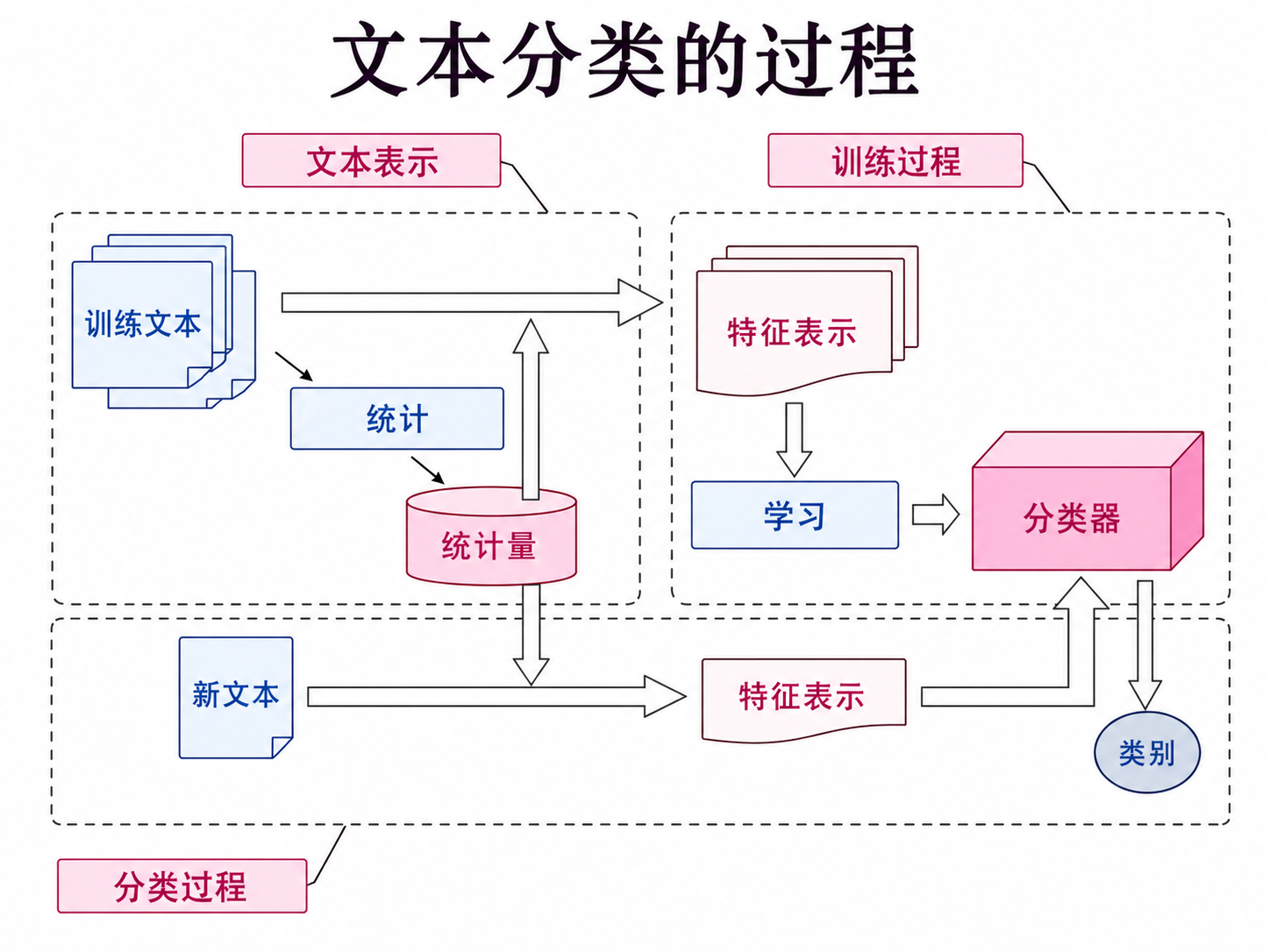
9. 描述实现文本分类的过程,并解释所涉及到的可能的模块。(12分)
解题思路:
- 构建每个类别的特征向量
- 计算新文本与类别之间的关联关系
- 选择关联度最大的设置类别
- 模块:分词,词性标注,Stem,Stopword去除,归一化,相似度计算,类别建模等等。