实验报告¶
上机实践名称:散列表
上机实践编号:No.7
上机实践日期:2023年4月13日
目的¶
1熟悉散列表的基本思想。
2掌握各种散列表的实现方法。
内容与设计思想¶
- 设计一个数据生成器,输入参数为 N;可以生成N个不重复的随机键或键值对。设计一个操作生成器,输入参数为N’,method;可以生成N’组操作method。操作包括插入和查询。
- 基于开放寻址法实现哈希表及其插入和查询操作,选择合适的数据规模,计算在不同表的大小和不同已占用数量下的所需时间。
- 以顺序访问的方式实现插入和查询。选择合适的数据规模,计算在不同表的大小和不同已占用数量下的所需的时间。
- 对比散列表(哈希表)和顺序访问。
- (思考题)探究不同散列函数对散列表性能的影响。
使用环境¶
推荐使用C/C++集成编译环境。
实验过程¶
1. 写出数据生成器和两种算法的源代码。
2. 以合适的图表来表示你的实验数据。
首先来看算法导论上面关于开放寻址法的描述:




然后各种各样的散列函数我就不在此赘述了,在课本上都有较详细的描述。
在本次实验过程中,我通过调整数据规模的大小,发现了基于开放寻址法的哈希方法和直接以顺序形式访问的差异,具体如下图所示:
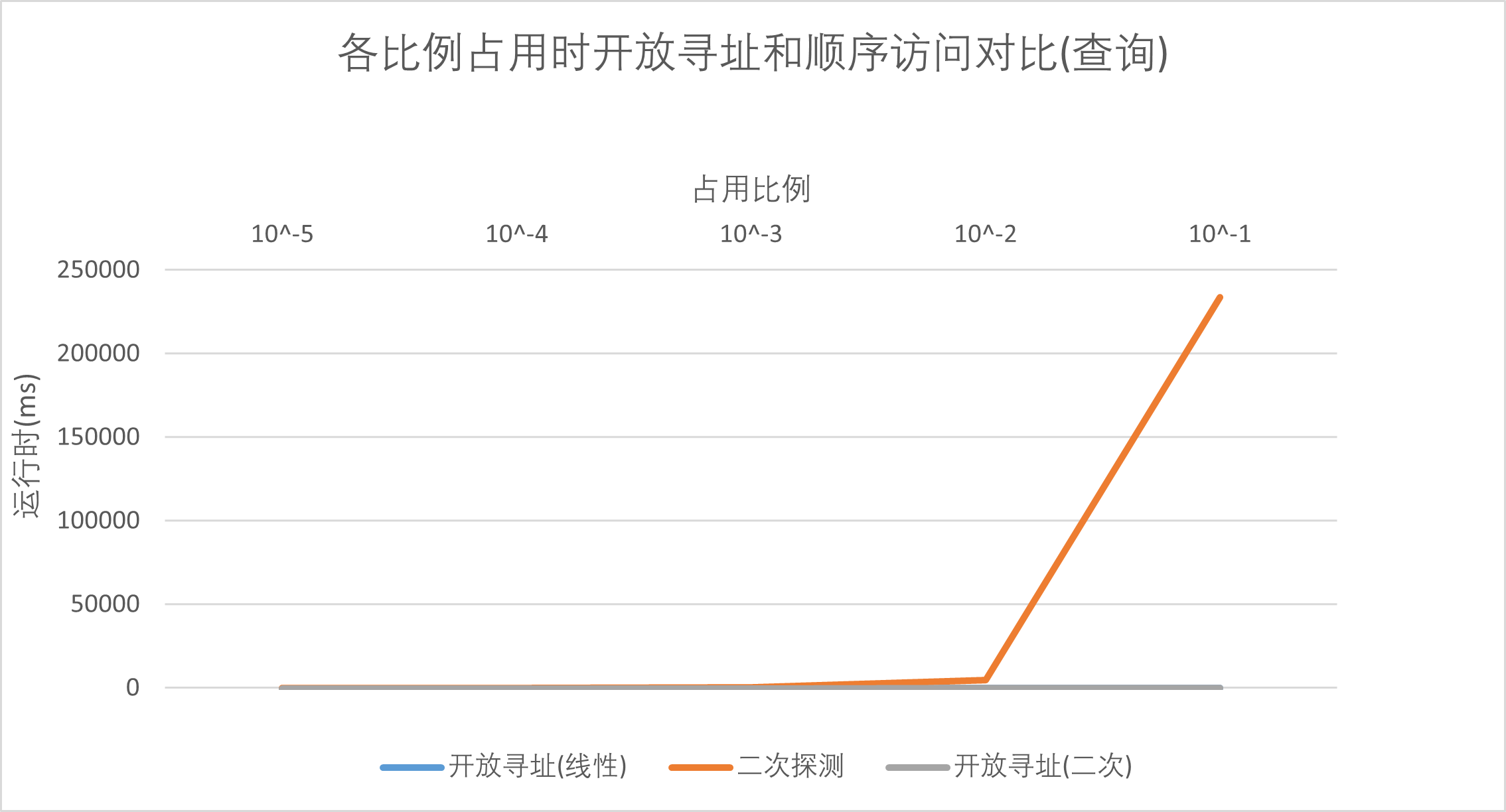
首先我锁定了表的最大容量,然后以这个最大容量为基数不断地扩大比例,实现了动态调整数据规模的目的。(这里可能有小小的歧义,但是之后我还会说不同占用比例时的情况)。
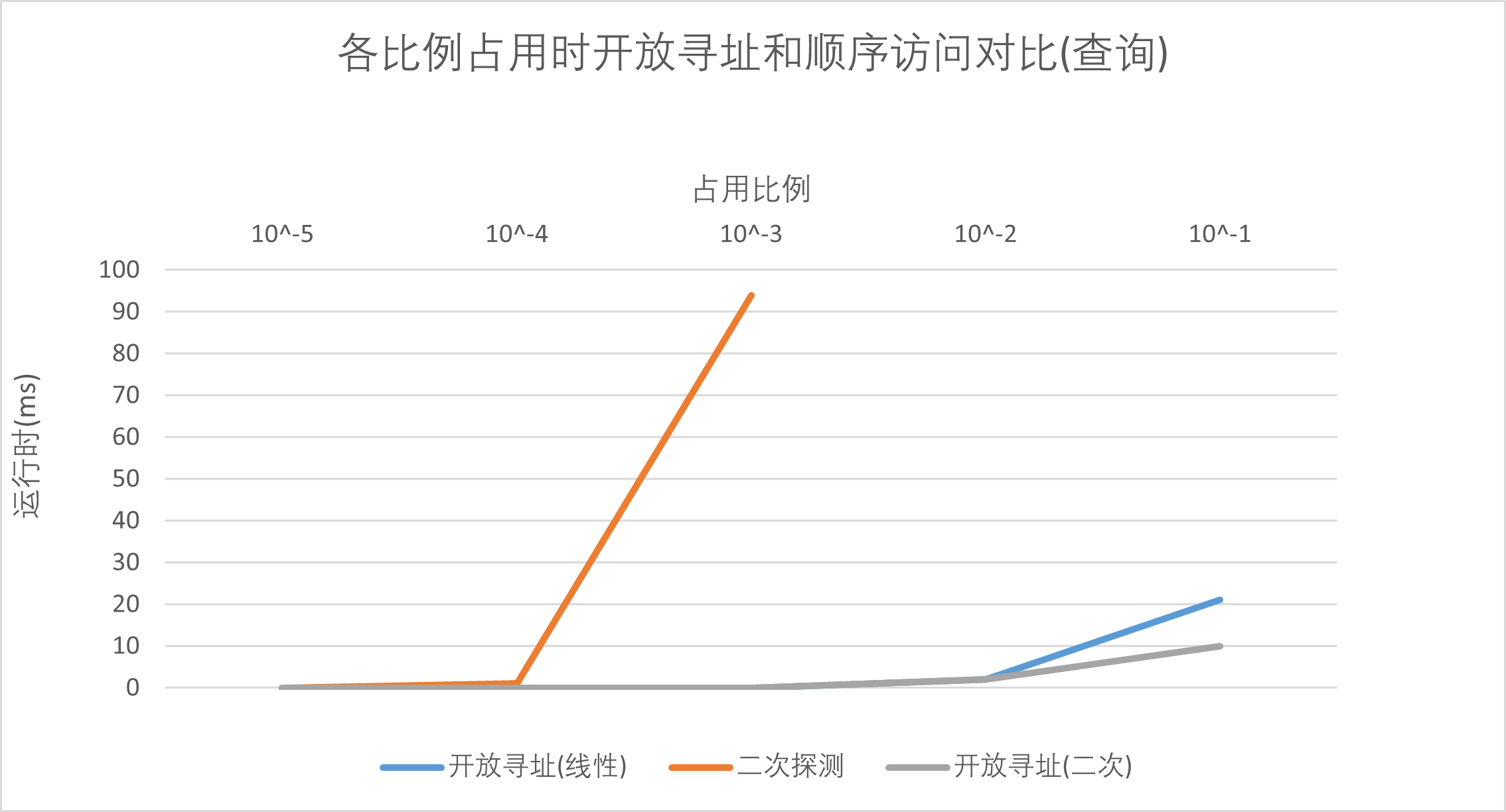
可以发现在查询时,开放寻址法的效率近乎是线性的,而且在细节处对比可以发现利用二次的探查函数效率是要比用线性的探查函数高的。
然而采用顺序访问的方法在查询时的效率就显得不可接受了,随着数据量的增大,查询的时间飙升——面对一个需要查询的数,顺序访问的方法需要一个接着一个地往后找,直到找到对应的,这显然是极其低效的。
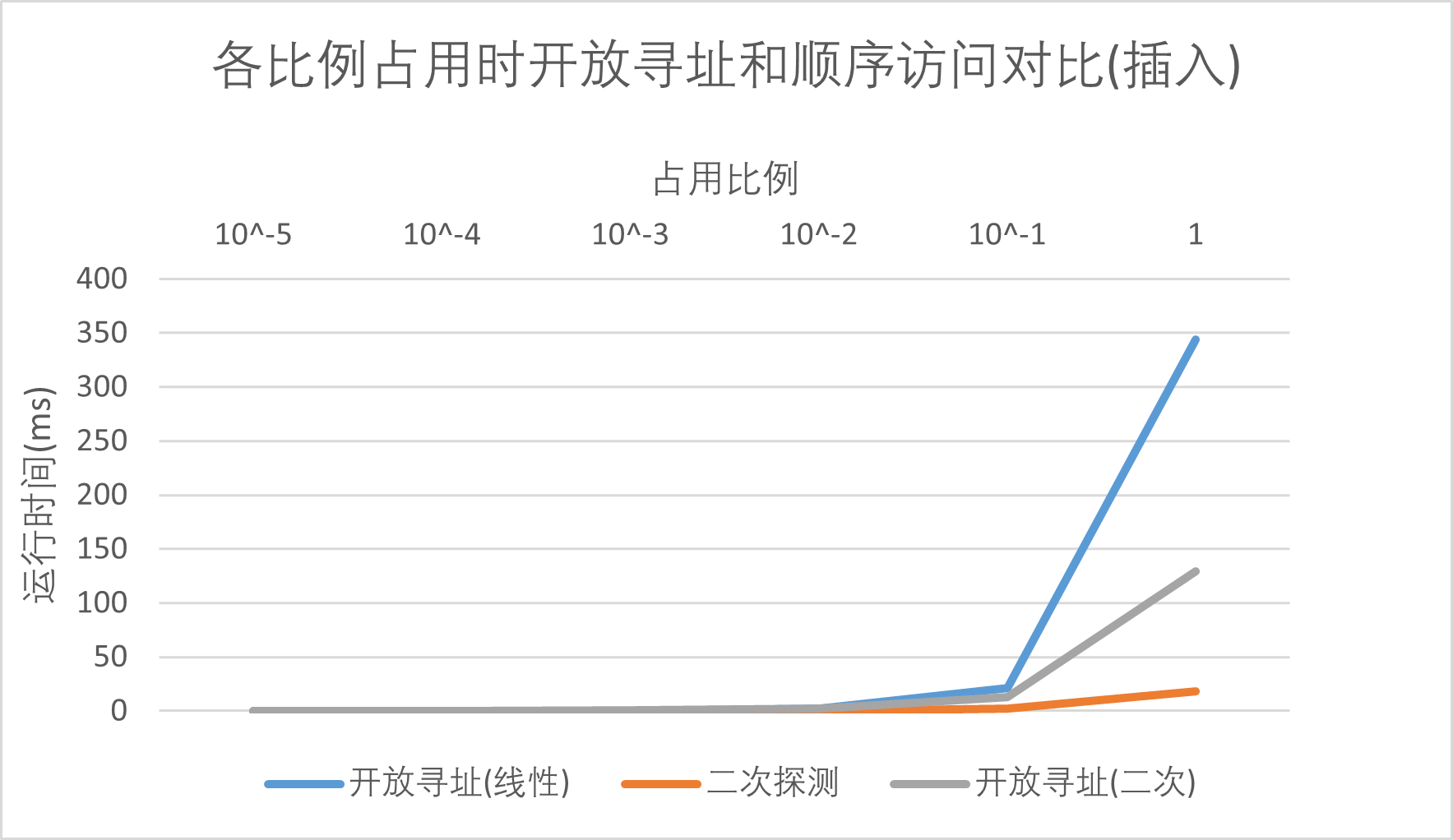
然后来看数据的插入时间对比,由于不用关心表项是否被占这个问题,通过顺序访问构建的表只需要把需要插入的元素放到表的下一个空闲位就行了;与之相对比,采用开放寻址法,在插入一个数据时,需要不断地通过hash函数探查一个空余的表项来存放数据,这个预处理的过程消耗了一定的时间。我们能明显看到,随着数据量的上升,采用顺序访问的表插入时间缓慢地上升,但是此时开放寻址法所消耗的时间也并未增长很多,保持一个线性的趋势,还是可以接受的。钻研细节,我们还可以发现在插入情况下,采用二次的探查函数在较大数据量时效率也是明显优于采用线性的探查函数的。
然后接下来我会探讨不同占用比例情况下三种方式的插入和查询时间。
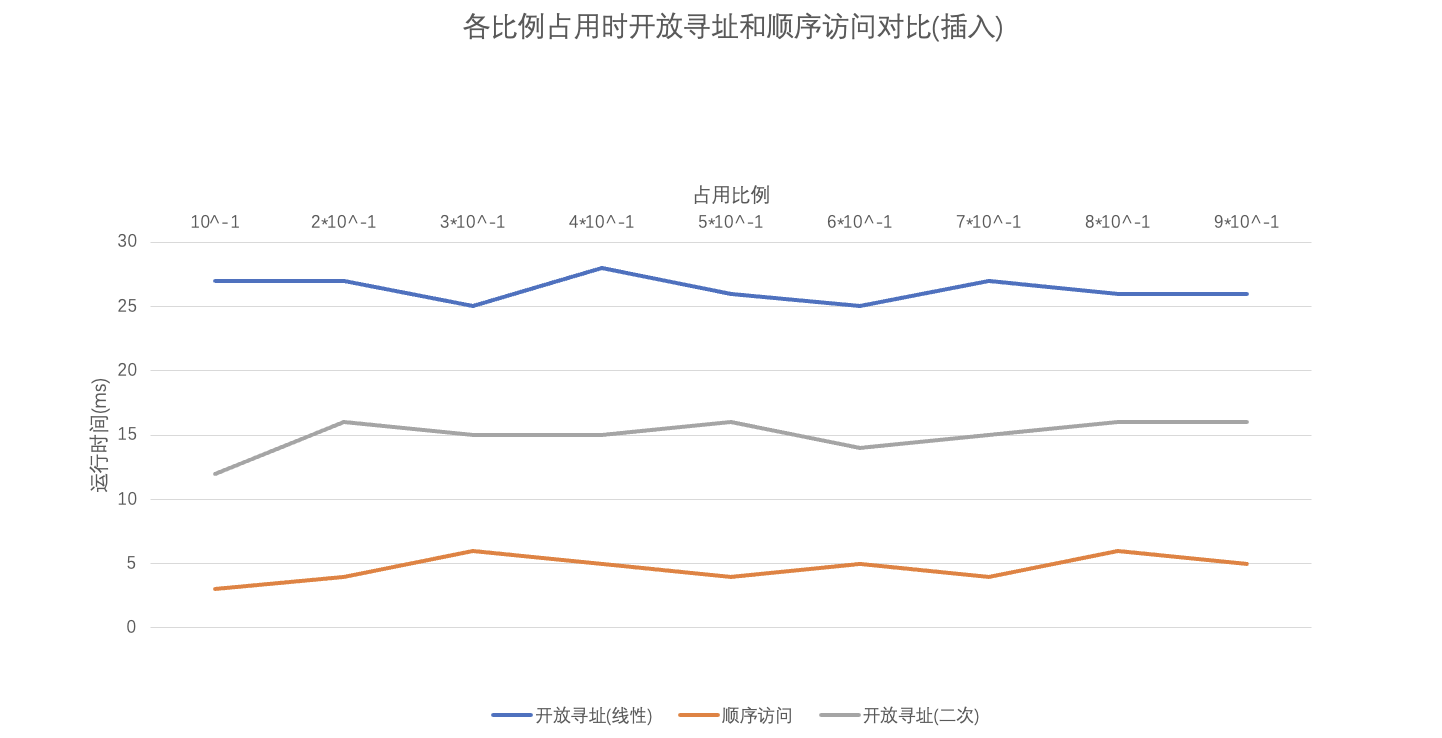
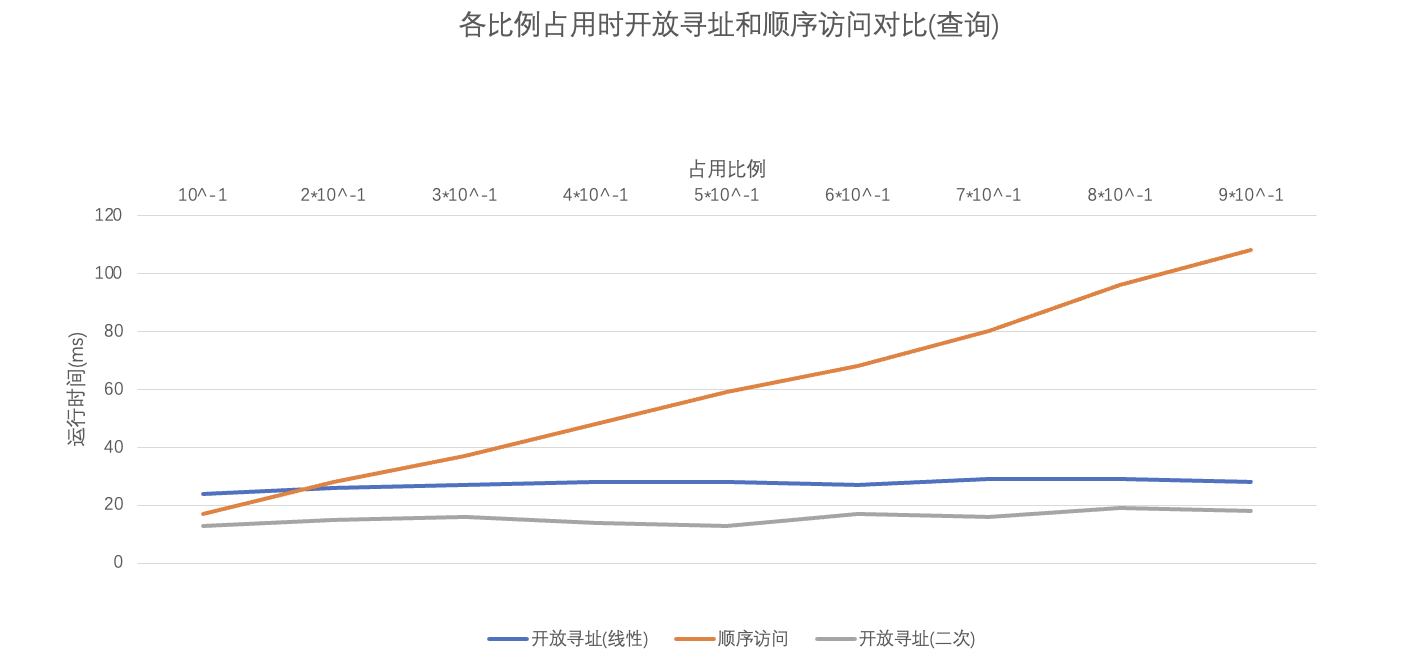
我们可以很明确的看到,在表的最大大小确定时,随着表的占用比例的增长,采用开放寻址法的哈希表和顺序访问的表在插入时运行时间维持了相对稳定的趋势,这个根据它们各自的原理也是容易理解的。然而,在查询时情况就有了很大的不同,顺序访问的时间呈现一个很明显的上升趋势(但是近似于线性)而采用开放寻址法的哈希表却依旧维持了一个稳定的趋势。当然这个可能主要还是因为自己的数据规模不算大,然后占用比例也没有设置的很极端,避免装载因子的极端情况(装载因子过大,会使得哈希碰撞的概率大大增大,进而大大降低了效率)。这个的主要原因还是在于它们原理的差异,查询某个值是否在哈希表中是常数时间,影响哈希表时间的决定性因素还是数据的规模;但是随着表中已有项的增多,采用顺序访问的方式要一个个地找到需要的值,这个无疑是增大了很多时间,随着数据规模地扩大,这个递增的趋势还会更加惊人。
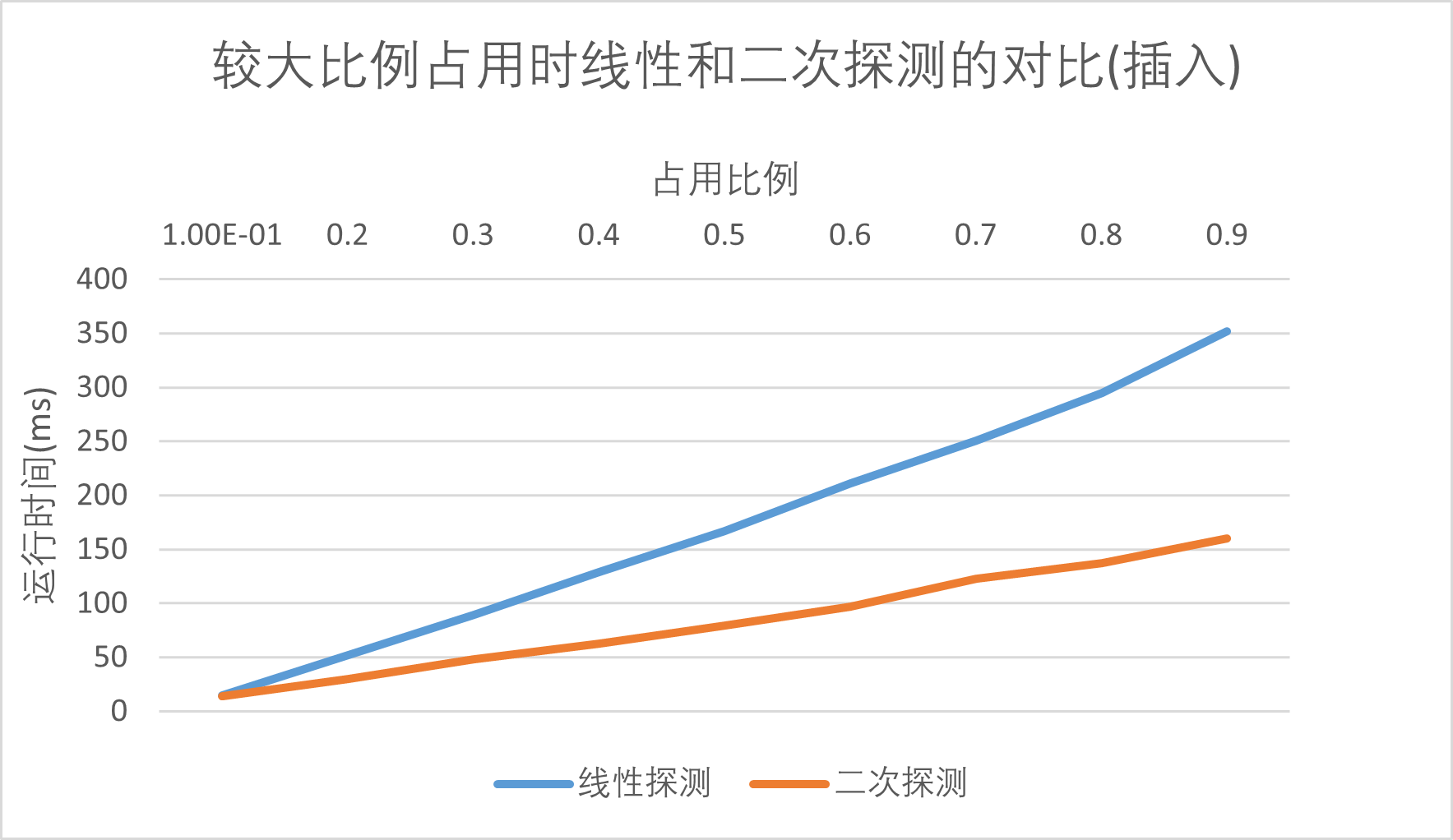
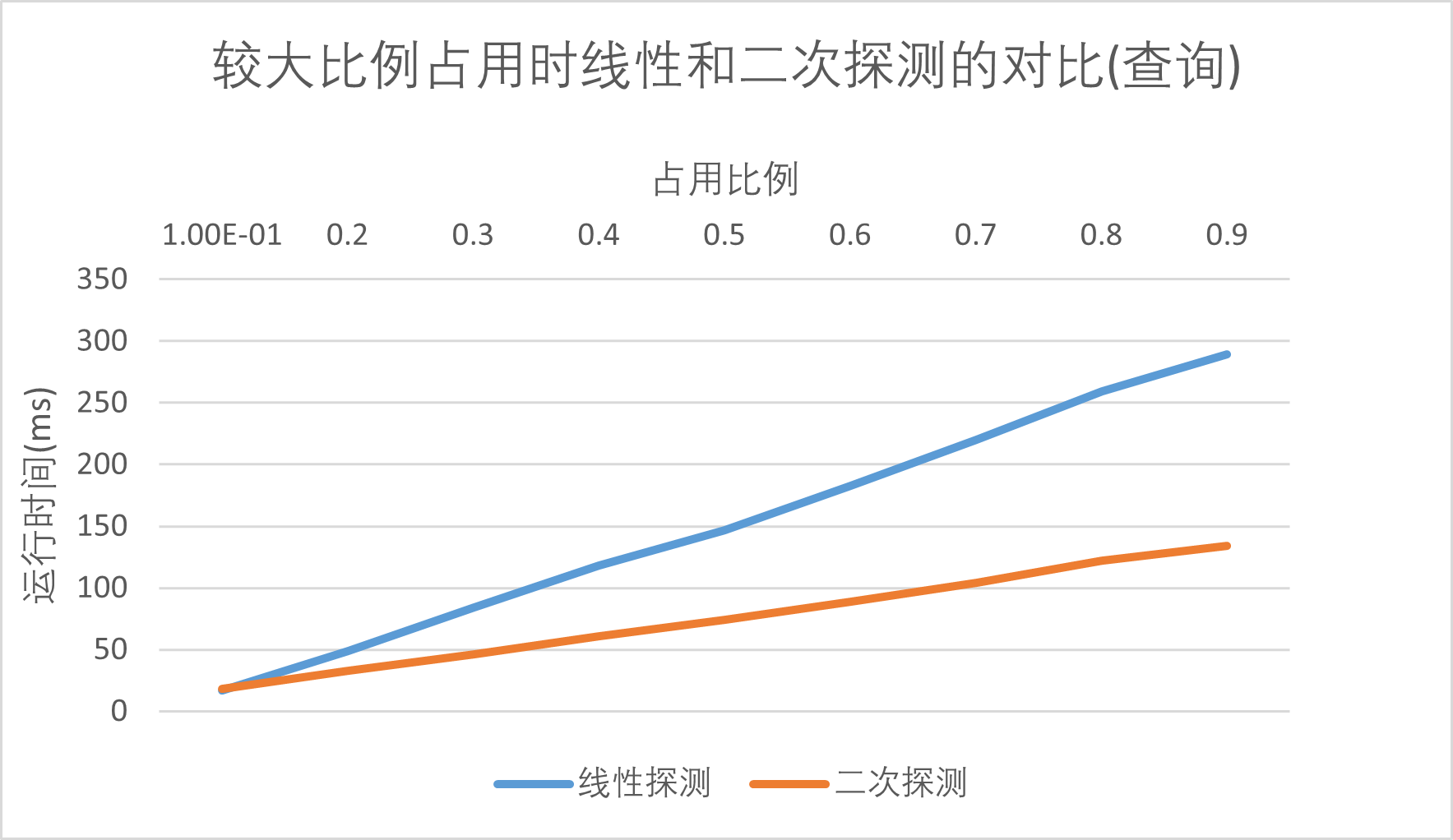
较大比例占用时线性和二次探测的对比(插入 和 查询)
(问题)探究不同散列函数对散列表性能的影响
在上述实验中,无论是什么情况下,都可以发现采用二次函数作为探查函数相对来说是比采用线性函数更优的,我就在此先小小地对比一下几种常见的方法吧:
- 采用二次函数作为探查函数,冲突概率相对较低,均匀分布合理,能够有效减少哈希冲突。这个较为适合我们事先不知道关键字的分布情况,在实际应用中也有较高的安全性;
- 采用线性定址法,该散列函数取关键字的某个线性函数值作为散列值。这个较为适用于数据较为连续地分布情况下。但是一般情况下线性函数作为探查函数产生的序列不太均匀,虽然发生冲突的概率较大,但是简单易操作,对于小规模的数据有很强的利用价值。
- 简单余数散列函数。算法十分简单,但是十分容易产生冲突,散列值地分布也不均匀。
- 随机数散列函数。产生的哈希值分布较为均匀,可有效避免哈希冲突;但是散列函数在单次创建和查询时的时间开销过大
在实际的应用中,还可以采用局部敏感哈希(LSH)等有效的方法,在此就不赘述了。
要论提高散列表的性能,其实主要可以从三个大方向来考虑。首先,就是要保证散列值较为均匀地分散在地址空间中,遇到冲突毕竟是一件消耗时间的事情;其次,就是要控制整个散列表的装载银子,不能过大(增大碰撞概率,影响效率)也不能过小(空间浪费);最后就是选择合适的哈希函数,在保证散列表固有特性的同时,尽可能使得哈希函数简洁高效,不会徒增运算的时间。
总结¶
对上机实践结果进行分析,问题回答,上机的心得体会及改进意见。
这次实验的整体难度不算大,但是我却受益匪浅。哈希算法在我们日常生活中有着广泛而深刻的应用,掌握哈希函数的具体流程之后,通过详细的对比,我见识了哈希算法的高效性,也希望以此为基础在日后的学习中能最大化它的价值。