2024-2025-1 期中理论测试¶
学号 _ 姓名 _
| 选择题 | 简答题1 | 简答题2 | 简答题3 | 简答题4 | 简答题5 | 总分 |
|---|---|---|---|---|---|---|
一、单项选择题(共30题,每题2分,共60分)¶
- 如右图所示,属于以下哪项计算机视觉任务()
A. 语义分割
B. 目标检测
C. 图像分类
D. 图像描述

- 在计算机视觉领域,和传统算法相比,基于深度学习的算法具有什么优点()
A. 健壮性和可扩展性强
B. 速度快、资源需求低
C. 可解释性强
D. 不容易过拟合
- 以下哪个计算机视觉 benchmark 数据集专用于手写数字识别任务()
A. ImageNet
B. MNIST
C. COCO
D. CIFAR-100
- KNN 算法可以实现最简单的图像分类器,但同时KNN 分类器有很多缺点,其中不包括以下哪条()
A. 泛化能力很差
B. 像素距离不能反映图像语义信息差异
C. 对训练集的数据分布要求高
D. 训练时间复杂度高
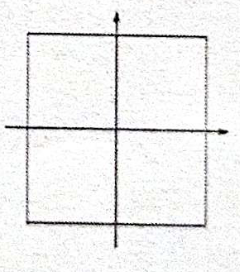
- 基于 KNN 算法进行图像分类,需要选择图片距离方程,来计算两个图像之间的像素距离。下面哪个是二维空间中的L1距离图像()
A.
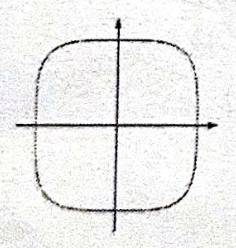
B.
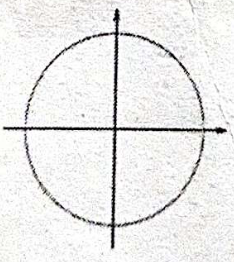
C.
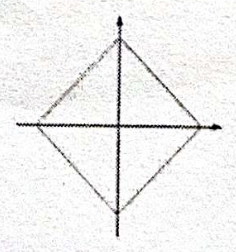
D.
- 在模型训练过程中,验证集数据(validation data)的作用是()
A. 训练模型的权重参数
B. 测试模型的性能表现
C. 选择模型的最优超参数
D. 对已训练好模型进行参数微调
- 使用 Softmax 损失函数训练线性分类模型,共 \(c\) 个类别。假设模型输出某个图片的所有类别分数 \(\{s_{i}, i=1,2,...,c\}\) ,其中 \(s_k\) 为真实类别的分数。则该图片的损失(loss)为()
A. \(\log(e^{s_{k}}/\sum_{i}e^{s_{i}})\)
B. \(-\log(e^{s_{k}}/\sum_{i}e^{s_{i}})\)
C. \(\log(e^{s_{k}}/\sum_{i\ne k}e^{s_{i}})\)
D. \(-\log(e^{s_{k}}/\sum_{i\ne k}e^{s_{i}})\)
- 假设使用 multiclass SVM loss 和 Softmax 分别训练线性分类器,包含 \(C\) 个类别。当初始化参数无限接近0时,那么训练未开始时,两个分类器在单个图像上的损失值分别约等于()
A. SVM分类器为 \(C\) ,Softmax 分类器为 \(\log(C-1)\)
B. SVM 分类器为 \(C-1\) , Softmax 分类器为 \(\log(C-1)\)
C. SVM 分类器为 \(C\) ,Softmax 分类器为 \(\log C\)
D. SVM分类器为 \(C-1\) , Softmax 分类器为 \(\log C\)
- 假设 \(X=4\) , \(Y=3\) ,则以下关于计算图中梯度计算的说法,正确的是()
A. 假设计算步骤 \(X \times Y=Z\) 中 \(Z\) 的梯度为5,那么 \(X\) 和 \(Y\) 对应的梯度分别为20和15
B. 假设计算步骤 \(X+Y=Z\) 中 \(Z\) 的梯度为5,那么 \(X\) 和 \(Y\) 对应的梯度分别为5和5
C. 假设计算步骤 \(Z=\max(X,Y)\) 中 \(Z\) 的梯度为5,那么 \(X\) 和 \(Y\) 对应的梯度分别为5和5
D. 假设计算步骤 \(Z=\text{Sigmoid}(X)=0.982\) 中 \(Z\) 梯度为5,那么 \(X\) 对应的梯度约为0.491
-
相比于全连接神经网络,卷积神经网络在处理图像时具有优势,但不包括以下哪项()
A. 通过参数共享进行神经元计算,可以减少参数量
B. 局部空间感知能力强
C. 采用池化操作,保留图像语义的同时,降低参数规模
D. 采用 dropout 操作,缓解过拟合
-
下面关于卷积计算的说法,正确的是()
A. 不同卷积核之间进行参数共享
B. 假设卷积层输入的深度通道数为 \(D\) ,则该层卷积核数量同样为 \(D\)
C. 在通过激活函数之前,卷积核仅进行线性的点积运算
D. 卷积核持续在输入特征图像上进行平移时,卷积区域不会出现重叠
-
下面关于卷积神经网络的说法,正确的是()
A. 进行 \(2\times2\) 的最大池化(max pooling)操作,池化层的参数个数为 \(2\times2\)
B. 使用 \(3\times3\) 的卷积核并且设置 stride=1、padding=1时,输入和输出的 activation map 具有一样的大小(不考虑通道数)
C. 假设单个卷积层的感受野为 \(3\times3\) ,堆叠3层卷积层的感受野扩大到 \(9\times9\)
D. 每个卷积层之后,需要加入一个池化层进行下采样
-
在构建神经网络时,使用sigmoid作为激活函数,不会造成()
A. 输出非零均值
B. 负区间饱和输出
C. 正区间饱和输出
D. 数据幅度不断增大
-
使用 ReLU 作为神经网络的激活函数,以下哪种参数初始化方法更适合保持深层网络的激活值分布稳定()
A. 零均值,标准差小于0.01的正态分布随机初始化
B. 零均值,标准差大于0.05的正态分布随机初始化
C. Kaiming 初始化
D. Xavier 初始化
-
关于 Batch Normalization 的说法,错误的是()
A. BN层的输出有可能和输入完全相同
B. BN 层会保存 training 阶段的均值和方差值,直接用于 test 阶段
C. 卷积层之后的BN层有 \(2C\) 个参数,其中 \(C\) 为卷积层的通道数
D. FC层之后的BN层须计算 \(N\) 个平均值和 \(N\) 个方差值,其中 \(N\) 为 batch size
-
下面关于 SGD+Momentum 优化器的说法,正确的是()
A. 当前梯度 \(dx\) 更大的参数,其动量值更大
B. 动量 momentum 的计算可以看作是梯度的滑动平均
C. 在同一次更新中,不同的模型参数使用不同的学习率
D. 在同一次更新中,不同的模型参数具有相同的动量值
-
以下哪个方法不能增强模型的泛化能力()
A. 使用 dropout
B. 使用 batch normalization
C. 使用不断衰减的学习率
D. 使用 data augmentation
-
下面关于 dropout 的说法,错误的是()
A. 有助于形成不同神经元的随机组合,缓解过拟合
B. 能够提升单个神经元的特征学习能力
C. 测试阶段保持与训练阶段相同的 drop 概率
D. 可通过对训练阶段的特征进行等价缩放,以保持测试过程简洁
-
对比深度学习框架中动态计算图和静态计算图的优劣,错误的是()
A. 使用动态计算图的运行效率更高
B. 使用动态计算图的代码更方便调试
C. 使用静态计算图的代码更方便跨语言调用
D. 使用静态计算图的代码更容易被编译器优化
-
GoogleNet 模型相对于 AlexNet 做出了许多优化,其中不包括()
A. 减少了全连接层,参数量降低
B. 并行地使用多个不同尺寸的卷积核,形成Inception 模块
C. 采用 skip connection,形成梯度回传的快速通道
D. 采用多段分类器,优化低层模型参数学习能力。
-
关于循环神经网络的说法,以下哪个说法是错误的()
A. RNN 每个时刻的输入为前一时刻的隐向量和当前时刻的输入
B. RNN的损失函数为各个时刻输出的损失函数的累加
C. LSTM 使用了门结构优化了RNN的梯度流,缓解了梯度消失问题
D. LSTM 的 forget gate 和 output gate 用于更新 cell state vector
-
利用 self-attention 进行序列化特征聚合,输入 \(N\) 个维度为 \(D\) 的向量,整合为 \(x\in R^{N \times D}\) ,以下哪个流程出现了错误? ()
A. 特征变换得到Key、Query、Value 向量: \(k=xW_{k}, q=xW_{q}, v=xW_{v}\)
B. 基于 Key 向量和Query 向量计算注意力分数: \(a_{i,j}=\text{softmax}(q_{j}\cdot k_{i})\)
C. 基于注意力分数对Value 向量加权求和: \(\{y_{j}=\sum_{i}a_{i,j}v_{i}, j=1....N\}\)
D. 以上皆对
-
在语义分割任务中,以下哪个概念最准确地描述了“语义分割”的定义()
A. 将图像中的每个像素分类为一个特定的类别
B. 识别图像中的物体并为每个物体提供边界框
C. 将图像分割成多个区域,以便进行特征提取
D. 识别和追踪视频中的移动物体
-
在R-CNN 系列模型中,Faster R-CNN 相较于Fast R-CNN的主要改进是()
A. 使用了更深的卷积神经网络作为特征提取器
B. 引入了区域建议网络(RPN) 来生成候选区域
C. 采用了多尺度特征图来提高检测精度
D. 在训练过程中使用了更大的数据集
-
SAM (Segment Anything Model)模型支持哪些类型的提示(prompt) ()
A. 点和框
B. 文本和图像
C. 点、框和 mask
D. 视频和音频
-
在视频分类任务中,3D CNN相较于2D CNN的主要优势是什么()
A. 处理更高分辨率的图像
B. 捕捉时间信息和空间特征
C. 更少的计算资源需求
D. 更简单的模型架构
-
在自监督学习的对比表征学习中,以下哪个描述是正确的()
A. 对比表征学习需要大量的标注数据来训练模型
B. 对比表征学习通过最大化正负样本之间的距离来学习表征
C. 对比表征学习利用数据本身的结构信息作为监督信号
D. 对比表征学习不关心样本之间的相似度或差异性
-
在SimCLR 的对比学习框架中,数据增强方法包括()
A. 随机裁剪、调整大小、色彩失真和高斯模糊
B. 图像旋转、图像平移、色彩失真和边缘检测
C. 随机裁剪、图像缩放、灰度化和噪声添加
D. 图像平移、随机裁剪、高斯模糊和梯度增强
-
在 MoCo (Momentum Contrast)框架中,以下哪项描述是正确的()
A. MoCo 不使用对比损失函数,而是通过重建输入像素来训练编码器
B. MoCo 通过维护一个动态字典,用于无监督学习
C. MoCo的字典大小与 mini-batch 大小直接相关,无法独立设置
D. MoCo 不使用动量编码器,而是直接复制查询编码器的参数作为键编码器
-
以下关于 CLIP(Contrastive Language-Image Pre-training)的描述中正确的是()
A. CLIP 是一个只能处理图像输入的模型,无法与文本信息结合使用
B. CLIP 通过对比学习训练,能够实现图像与文本之间的关联性学习
C. CLIP 的主要应用是图像分类,不能用于其他视觉任务
D. CLIP 不需要大量的标注数据,因为它利用自然语言监督进行预训练
二、简答题(共5题,40分)¶
第一题:随机梯度下降 SGD的参数更新过程为 \(x_{t+1}=x_{t}-\alpha\nabla f(x_{t})\) 其中 \(x_{t}\) 表示t时刻的模型参数, \(\alpha\) 为学习率。请参考SGD,完成以下优化器的参数更新过程。(5分)¶
(1) 请写出 SGD + Momentum 的参数更新过程, \(v_{t}\) 表示t时刻的累积参数梯度(动量), \(\rho\) 为衰减因子(2分)
\(v_{t+1} = (\) \()\)
\(x_{t+1} = (\) \()\)
(2) 请写出 RMSProp 的参数更新过程, \(g_{t+1}\) 对梯度值的平方进行累计估计, \(\beta\) 为衰减率(2分)
\(g_{t+1} = (\) \()\)
\(x_{t+1} = (\) \()\)
(3) 请结合(1)中 \(v_{t+1}\) 和 (2) 中 \(g_{t+1}\) ,写出 Adam 的参数更新过程(忽略 Momentum 和Adam 中计算 \(v_{t+1}\) 的差异,且省略 bias correction 步骤)(1分)
\(x_{t+1} = (\) \()\)
第二题:全连接网络(10分):¶
构造基于两层全连接神经网络的三分类模型,假设在某次前向计算中,输入 \(N=3\) 张图像的 minibatch \(X\) ,每张图像用 \(D=2\) 维特征表示。两层NN的权重分别为 \(W_{1}\) 和 \(W_{2}\) ,具体如下:
第一层网络 \((W_{1})\) 使用ReLU激活,输出层 \(W_{2}\) 不使用激活。
A) 请写出前向计算中,以下两层网络的计算结果,并给出分类结果(4分)
- \(H = \text{ReLU}(X \times W_{1})\)
- \(Y = H \times W_{2}\) 及分类结果
B) 只考虑上述 minibatch 中第一张图像 \(X_{1} = \begin{bmatrix} 2 & 3 \end{bmatrix}\) ,假设上游梯度为 \(\frac{\partial L}{\partial Y_{1}} = \begin{bmatrix} 1, -1, 1 \end{bmatrix}\) ( L为loss ),请依次写出反向传播中,以下三步的计算结果(6分)。
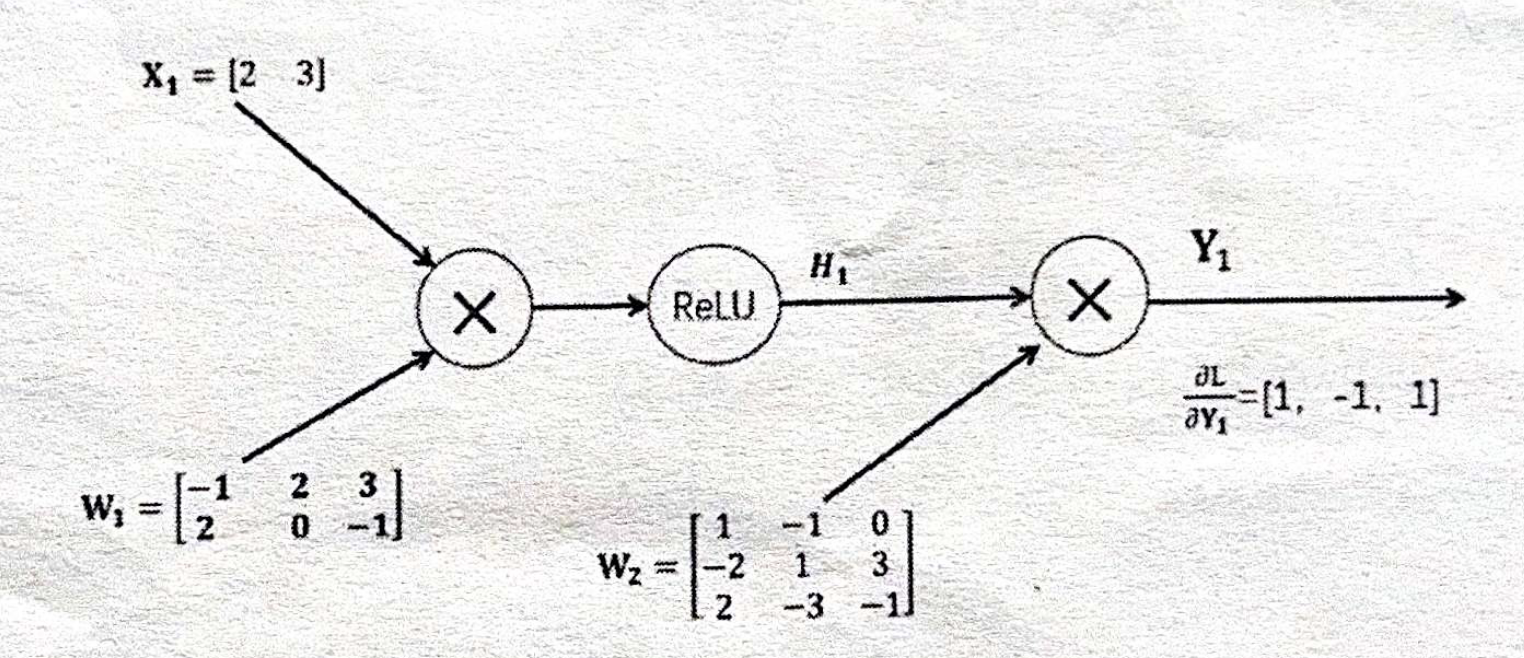
- \(\frac{\partial L}{\partial W_{2}}\)
- \(\frac{\partial L}{\partial H_{1}}\)
- \(\frac{\partial L}{\partial W_{1}}\)
第三题:CNN模型(10分):¶
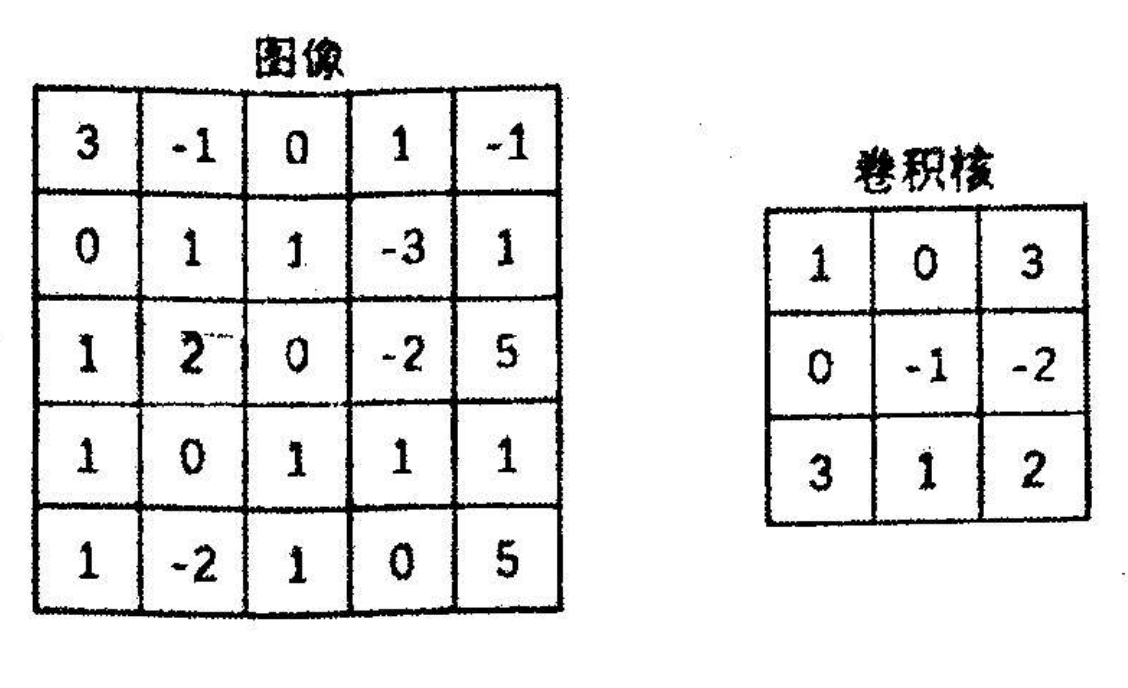
A) 给定如下的图像,以及一个 \(3\times3\) 的卷积核,请分别写出(1) \(stride=1\) ,无 padding ; (2) \(stride=2\) , zero-padding \(=1\) ,两种卷积计算的结果(不使用激活)。(3分)
B) 给定如下卷积神经网络结构以及每一层的大小。假设所有层均不使用 padding,卷积层 \(stride=1\) ,池化层使用无重叠池化(non-overlapping pooling)。请推断出每一层参数(权重)的形状、个数(或步长)(3分)
INPUT: \(32\times32\times3\) \([H\times W\times D]\)
CONV1: \(28\times28\times6\) 卷积核的形状、个数:( )
POOL1: \(14\times14\times6\) 池化核形状、步长:( )
CONV2: \(8\times8\times12\) 卷积核的形状、个数:( )
POOL2: \(4\times4\times12\) 池化核形状、步长:( )
FC: \(32\times1\) 参数权重形状:( )
OUTPUT: \(16\times1\) 参数权重形状:( )
C) 请分别简要描述, VGGNet, GoogLeNet 和 ResNet 模型的主要特点(4分)
第四题:RNN 模型及图像描述(10分):¶
- Vanilla RNN:分别用 \(x\) 和 \(h\) 表示输入和隐向量,请补充RNN在 \(t\) 时刻的隐向量更新和结果预测的计算公式(需体现出参数)(2分)
\(h_{t} = \tanh(\) \()\)
\(y_{t} = (\) \()\)
- LSTM:请补充完整LSTM在t时刻的计算公式,并简述 \(i, f, o, g\) 的作用(4分)
\(\begin{pmatrix} i \\ f \\ o \\ g \end{pmatrix} = \begin{pmatrix} \cdot \\ \cdot \\ \cdot \\ \cdot \end{pmatrix} W \begin{pmatrix} \cdot \space \cdot \end{pmatrix}\)
\(c_{t} = (\) \() c_{t-1} + (\) \() \odot (\) \()\)
\(h_{t} = (\) \() \odot \tanh(c_{t})\)
- 图像描述:请结合下图,给出 \(h_{1}\) 的计算公式,并阐述基于RNN的图像描述任务的基本过程(4分)
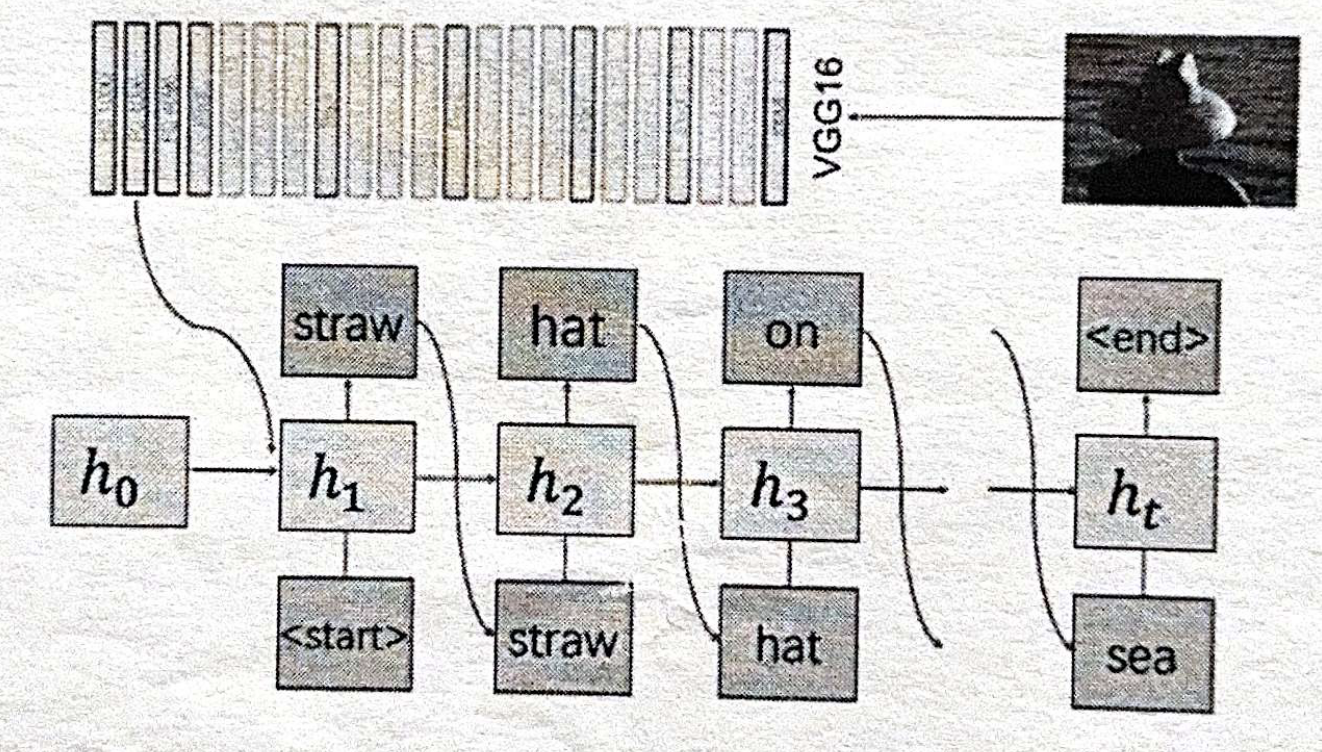
第五题:自注意力机制(5分)¶
- 下图所示为输入向量序列 \(x_{1}, x_{2}, x_{3}\) ,输出向量序列 \(y_{1}, y_{2}, y_{3}\) 的自注意力层,请补全空缺操作,并补全数据流连接(3分)
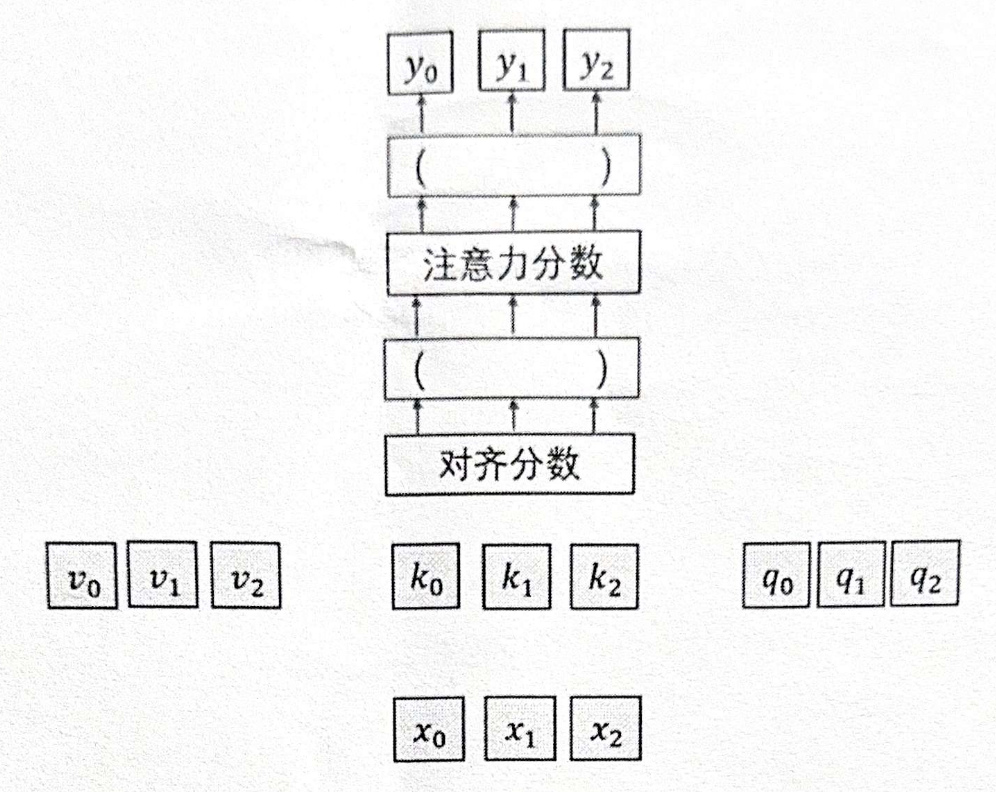
- 请分别说明 masked self-attention 和 multi-head self-attention与常规的 self-attention 有什么不同? (2分)