2022-2023-2-编程作业2¶
2020级,Spark
Word Count¶
待完成:¶
- 请在 DSPPCode.spark.warm_up.impl 中创建 WordCountImpl, 继承 WordCount, 实现抽象方法
题目描述:¶
-
现存在一份英文文本文件,要求统计文本中每个单次出现的次数,并将计数结果输出到文本中。
-
输入格式:
apple pen applepen pineapple pineapplepen boy cat dog boy cat
dog cat dog dog
- 输出格式:
(pen,1)
(pineapple,1)
(dog,4)
(pineapplepen,1)
(apple,1)
(applepen,1)
(boy,2)
(cat,3)
代码略
蒙特卡洛模拟方法求定积分¶
难易度:*易¶
待完成¶
- 请在 DSPPCode.spark.definite_integral.impl 中创建 DefiniteIntegralSimulatorImpl, 继承 DefiniteIntegralSimulator, 实现抽象方法
问题描述¶
蒙特卡洛模拟方法,是一种基于”随机数“的计算方法,其数学基础是大数定律与中心极限定理。它的一个重要应用就是求解定积分。其思想如下:定积分的实质是一个面积,我们设其值为\(I\),对于一个包含定积分面积为\(S\)的区域我们随机产生一些随机数,其总量为\(N\),我们再统计积分区域内的随机数,其数量为\(i\),则产生在积分区域内的随机数的概率为\(\frac{i}{N}\),这于积分区域与总区域的比值\(\frac{I}{S}\),近似相等,则我们可以求得\(I=\frac{i}{N}S\)。
例如对于下图所示的函数\(f(x)\),如果想用上述方法求\(I=\int^{a}_bf(x)dx\)。

我们可以在图中虚线围成的矩阵区域\((a,0),(b,0),(a,c),(b,c)\)随机生成若干个点\(N\),生成在积分区域中的点(红色点)数量为\(i\),对于矩阵区域其面积为\(S=(b-a)(c-0)\),则我们可以求得定积分值\(I=\int^{a}_bf(x)dx=\frac{i}{N}S\)。
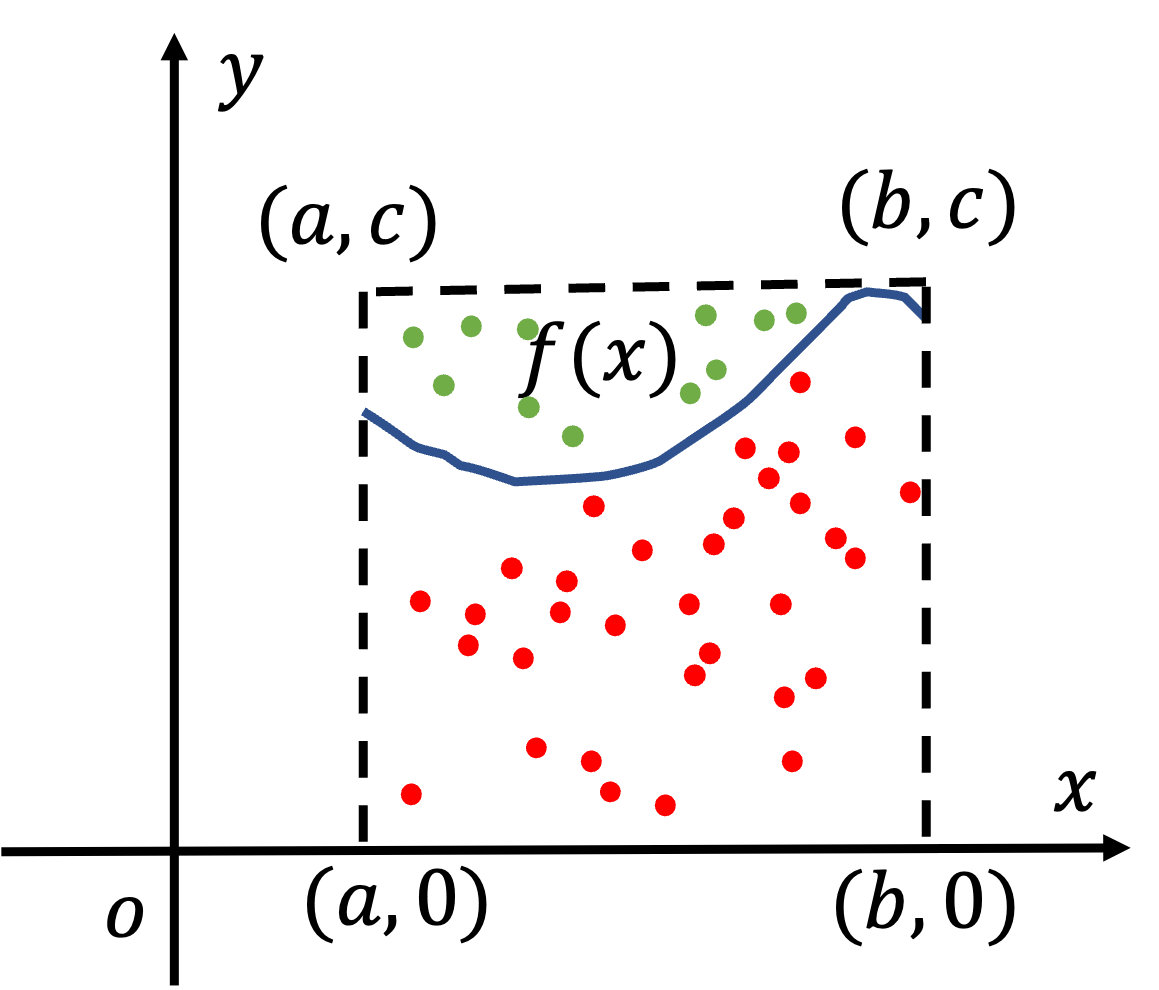
请基于上述思想,基于Spark实现使用蒙特卡洛方法求解定积分。
DefiniteIntegralSimulatorImpl¶
package DSPPCode.spark.definite_integral.impl;
import DSPPCode.spark.definite_integral.question.DefiniteIntegralSimulator;
import DSPPCode.spark.definite_integral.question.utils.FunctionCaller;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.Function;
public class DefiniteIntegralSimulatorImpl extends DefiniteIntegralSimulator {
public JavaRDD<Integer> sampledPoint(JavaRDD<Integer> parallelInput, final FunctionCaller functionCaller, final double[] range) {
JavaRDD<Integer> count = parallelInput.map(new Function<Integer, Integer>() {
public Integer call(Integer o) throws Exception {
double x = Math.random() * (range[1] - range[0]) + range[0];
double y = Math.random() * range[2];
return functionCaller.getVal(x) > y ? 1 : 0;
}
});
return count;
}
}
Friendship¶
难易程度: **中¶
待完成¶
- 请在 DSPPCode.spark.friendship.impl 中创建 FriendshipImpl, 继承 Friendship, 实现抽象方法
题目描述:¶
-
根据输入文本中的用户关系,找出任意两个用户之间的共同好友。
-
输入格式:输入文本中每行表示一个用户关系,一个用户关系由多个列组成。其中,第一列为用户名,其余列为该用户的好友的用户名,用户名之间用空格分隔。例如,下面第一行表示用户A有B、C、D、E、F五位好友。
A B C D E F B A C D E C A B E D A B E E A B C D F A -
输出格式: 输出文本的每行表示两个用户的用户名及其所有共同好友的用户名,其中两个用户的用户名按升序字典序进行拼接,所有共同好友的用户名之间以逗号和空格分隔。 例如, 下面第一行表示用户A和C的两个用户的所有共同好友为B、E。
(AC,[B, E])
(BC,[A, E])
(CE,[A, B])
(AB,[C, D, E])
(AE,[B, C, D])
(CD,[A, B, E])
(DF,[A])
(CF,[A])
(AD,[B, E])
(DE,[A, B])
(BE,[A, C, D])
(BF,[A])
(EF,[A])
(BD,[A, E])
注意:请先完成orderedPairs函数
FriendshipImpl¶
package DSPPCode.spark.friendship.impl;
import DSPPCode.spark.friendship.question.Friendship;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import scala.Tuple2;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
public class FriendshipImpl extends Friendship {
@Override
public JavaPairRDD<String, Iterable<String>> findFriendShip(JavaRDD<String> lines) {
// 将每一行分割成用户和好友列表
JavaPairRDD<String, String> userAndFriends = lines.mapToPair(line -> {
String[] parts = line.split("\t");
return new Tuple2<>(parts[0], parts[1]);
});
// 将好友列表进一步分割,得到每个用户和其每个好友的配对
JavaPairRDD<String, String> userAndFriend = userAndFriends.flatMapToPair(pair -> {
String user = pair._1;
String[] friends = pair._2.split(",");
List<Tuple2<String, String>> pairs = new ArrayList<>();
for (String friend : friends) {
pairs.add(new Tuple2<>(user, friend));
}
return pairs.iterator();
});
// 对每个用户和好友的配对进行分组,得到每个用户的所有好友
JavaPairRDD<String, Iterable<String>> userAndAllFriends = userAndFriend.groupByKey();
// 对每个用户的所有好友进行两两配对,得到可能的用户对和其共同好友
JavaPairRDD<String, String> possiblePairsAndCommonFriend = userAndAllFriends.flatMapToPair(pair -> {
String user = pair._1;
Iterable<String> friends = pair._2;
List<Tuple2<String, String>> pairs = new ArrayList<>();
for (String friend1 : friends) {
for (String friend2 : friends) {
if (!friend1.equals(friend2)) {
String pairKey = friend1.compareTo(friend2) < 0 ? friend1 + "," + friend2 : friend2 + "," + friend1;
pairs.add(new Tuple2<>(pairKey, user));
}
}
}
return pairs.iterator();
});
// 对可能的用户对和共同好友进行分组,得到每个用户对的所有共同好友
JavaPairRDD<String, Iterable<String>> pairsAndCommonFriends = possiblePairsAndCommonFriend.groupByKey();
return pairsAndCommonFriends;
}
private String getSortedPair(String friend1, String friend2) {
List<String> pair = Arrays.asList(friend1, friend2);
Collections.sort(pair);
return pair.get(0) + "," + pair.get(1);
}
@Override
public List<String> orderedPairs(String[] strs) {
List<String> result = new ArrayList<>();
for (int i = 0; i < strs.length; i++) {
for (int j = i + 1; j < strs.length; j++) {
result.add(strs[i] + strs[j]);
}
}
return result;
}
}
Revised Kmeans¶
RevisedKmeansImpl¶
package DSPPCode.spark.revised_kmeans.impl;
import DSPPCode.spark.revised_kmeans.question.RevisedKmeans;
import java.util.ArrayList;
import java.util.List;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.broadcast.Broadcast;
import scala.Tuple2;
public class RevisedKmeansImpl extends RevisedKmeans {
public Integer closestPoint(List<Integer> p, Broadcast<List<List<Double>>> kPoints) {
Integer bestIndex = 0;
Double closest = Double.MAX_VALUE;
List<List<Double>> kPointsValue = (List)kPoints.value();
for(int i = 0; i < kPointsValue.size(); ++i) {
Double dist = this.distanceSquared(p, (List)kPointsValue.get(i));
if (dist < closest) {
closest = dist;
bestIndex = i;
}
}
return bestIndex;
}
public Broadcast<List<List<Double>>> createBroadcastVariable(JavaSparkContext sc, List<List<Double>> localVariable) {
Broadcast<List<List<Double>>> broadcastKPoints = sc.broadcast(localVariable);
return broadcastKPoints;
}
public List<List<Double>> iterationStep(JavaRDD<List<Integer>> points, Broadcast<List<List<Double>>> broadcastKPoints) {
int counter = 0;
List<List<Double>> kPoints = (List)broadcastKPoints.value();
JavaPairRDD<Integer, Tuple2<List<Integer>, Integer>> closest = this.getClosestPoint(points, broadcastKPoints);
List<List<Double>> newPoints = this.getNewPoints(closest);
List<List<Double>> emptyPoints = new ArrayList();
for(int ii = 0; ii < newPoints.size(); ++ii) {
double sum = (double)0.0F;
for(int j = 0; j < ((List)kPoints.get(ii)).size(); ++j) {
sum += Math.pow((Double)((List)kPoints.get(ii)).get(j) - (Double)((List)newPoints.get(ii)).get(j), (double)2.0F);
}
if (Math.pow(sum, (double)0.5F) <= 1.0E-6) {
++counter;
}
}
if (counter == newPoints.size()) {
return emptyPoints;
} else {
return newPoints;
}
}
}
linear regression¶
IterationStepImpl¶
package DSPPCode.spark.linear_regression.impl;
import DSPPCode.spark.linear_regression.question.Data;
import DSPPCode.spark.linear_regression.question.IterationStep;
import org.apache.spark.api.java.JavaRDD;
public class IterationStepImpl extends IterationStep {
public double[] runStep(JavaRDD<Data> data, double[] weight, long count) {
double[] weight_old = weight;
double[] weight_new = new double[weight.length];
double[] optimum = new double[weight.length];
for(int i = 0; i < optimum.length; ++i) {
optimum[i] = (double)0.0F;
}
for(long i = 0L; i < count; ++i) {
Data dt = (Data)data.collect().get((int)i);
double y = dt.getY();
double[] x = dt.getX();
double h_at_x = (double)0.0F;
for(int j = 1; j < weight_old.length; ++j) {
h_at_x += weight_old[j] * x[j - 1];
}
h_at_x += weight_old[0];
optimum[0] += 0.1 / (double)count * (h_at_x - y);
for(int j = 1; j < optimum.length; ++j) {
optimum[j] += 0.1 / (double)count * (h_at_x - y) * x[j - 1];
}
}
for(int i = 0; i < weight_new.length; ++i) {
weight_new[i] = weight_old[i] - optimum[i];
}
return weight_new;
}
public double[] iteration(JavaRDD<Data> data, int dimension, int epoch, double threshold) {
double[] w_beginning = new double[((Data)data.collect().get(0)).getX().length + 1];
for(int i = 0; i < w_beginning.length; ++i) {
w_beginning[i] = (double)0.0F;
}
for(int I = 0; I < epoch; ++I) {
double euciDist = (double)0.0F;
double[] w_new = this.runStep(data, w_beginning, data.count());
for(int i = 0; i < w_beginning.length; ++i) {
euciDist += Math.pow(w_beginning[i] - w_new[i], (double)2.0F);
}
euciDist = Math.pow(euciDist, (double)0.5F);
if (euciDist <= threshold) {
System.out.println("YEAH");
w_beginning = w_new;
break;
}
w_beginning = w_new;
}
for(int i = 0; i < w_beginning.length; ++i) {
String str = String.format("%.2f", w_beginning[i]);
w_beginning[i] = Double.parseDouble(str);
}
return w_beginning;
}
}