第3组-Flink¶
实验8¶
上机实践名称: Flink部署
上机实践日期:2024年6月4日
问题1:配置flink-1.12.1/conf/flink-conf.yaml之后start-cluster出现问题
经过一段时间的检查,我发现自己忽略了实验指导文档中的一句话:

按照格式要求重新修改flink-conf.yaml之后,我再去start-cluster就好了。
问题2:下载Flink时候报错Error 404:Not Found
本来我还以为是网络问题,但检查一番后我发现自己的路径打错了,正确的应该是sudo wget https:/archive.apache.org/dist/flink/flink-1.12.1/flink-1.12.1-bin-scala_2.11.tgz 但是我输入的确是:sudo wget https:/archive.apache.org/dist/flink/flink-1.12.1/flink-1.12.1-bin.scala_2.11.tgz 就一个小小的符号打错了就路径错误了。
问题3:attached方式最初结果不对
结果不对:
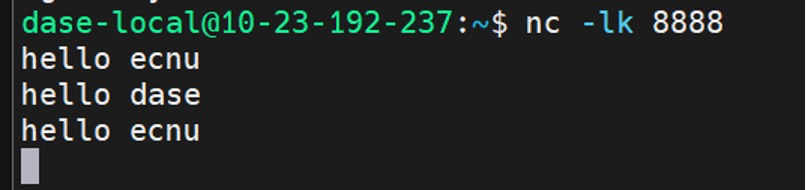

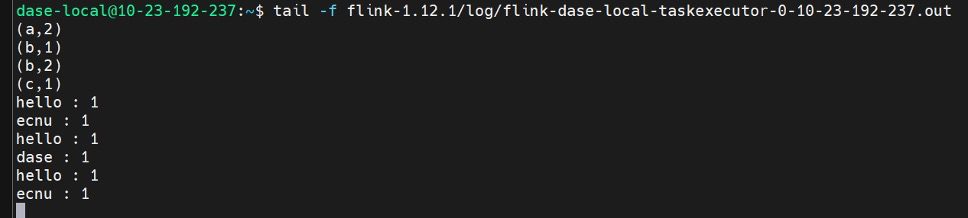
正确的应该是这样:
我都重启了一下,包括第一个终端的监听输入,第二个终端中的job就好了:


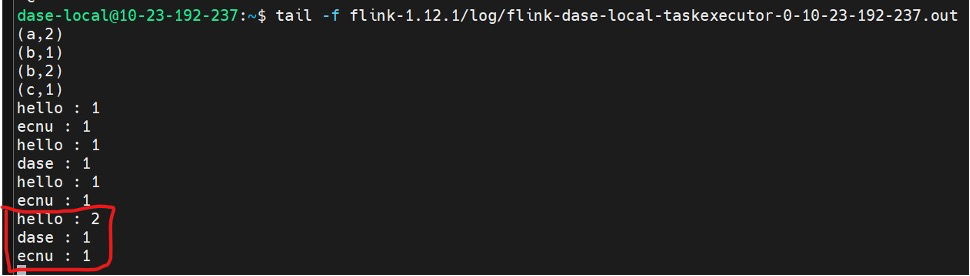
问题4:提交jar包之后报错并终止运行

无论是attached还是detached模式,都要先启动netcat之后才能提交jar包,否则就是报错
问题5:输出结果和输入的速度紧密相关,可能会导致和实验文档中的预期结果存在差异
输出结果和输入的速度紧密相关,如果不紧不慢地慢慢输hi dase hi ecnu flink flink,输出就是全1。但如果已经写好了要输入的内容,复制粘贴到netcat中,就输出2 2 1 1
为了避免这一细节带来的影响,我后来输入数据都是讲内容写好,然后直接复制粘贴到netcat中。
实验9¶
上机实践名称: Flink编程
上机实践日期:2024年6月11日
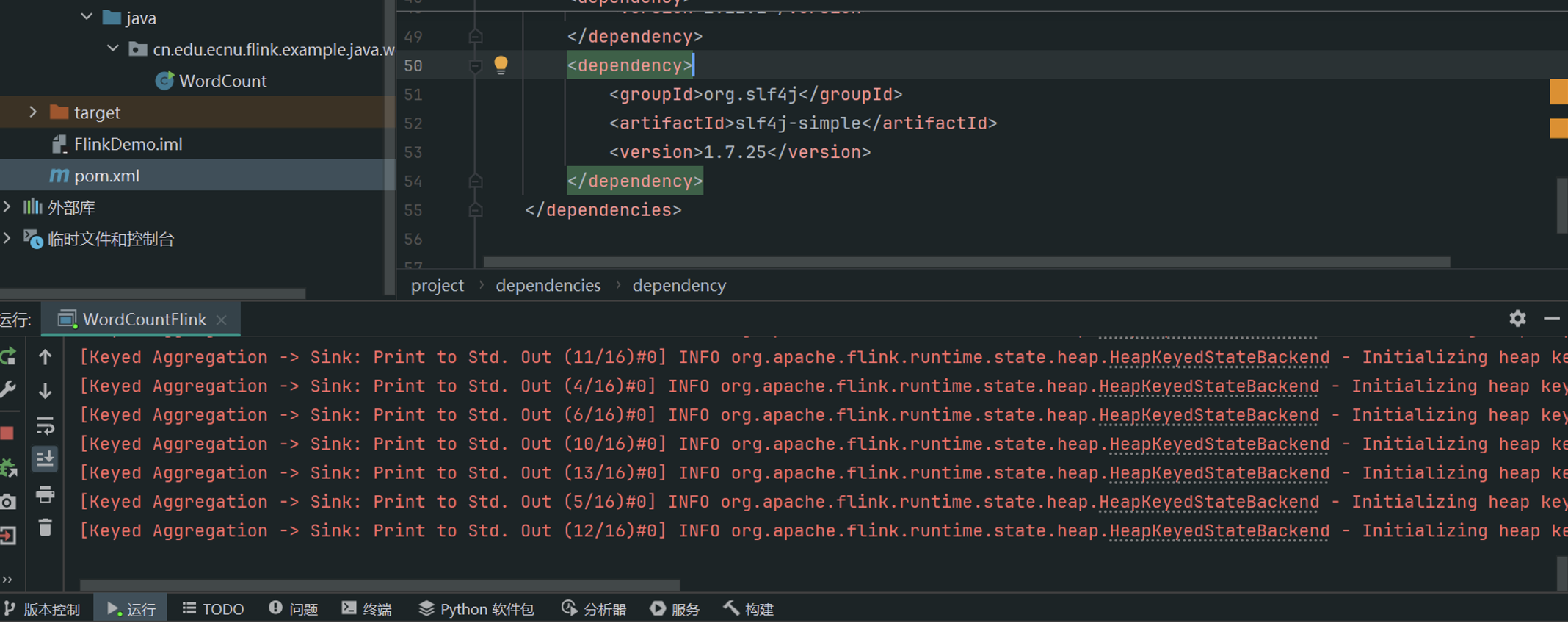
问题1:IDEA里面去运行程序时报错SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".

参考这里的思路(https://blog.csdn.net/wang465745776/article/details/80384210)pom.xml加上这句话就好了:
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.25</version>
</dependency>
问题2:本地运行scala版本时,报错java.lang.ClassNotFoundException
经过一段时间的排查,我发现程序运行时找不到org.apache.flink.client.program,然后进一步检查发现IDEA中的报错:No Scala SDK in module
在把Scala SDK引入后,问题并没有解决。然后我又检查了一下,发现自己的Flink版本是错误的,在pom.xml中修改成如下的样子就好了:
<dependency>
<groupId>org.apache</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.12.1</version>
</dependency>
实验10¶
上机实践名称: Flink+Yarn
上机实践日期:2024年6月18日
问题1:hadoop: command not found
在进行单机伪分布式部署实验时,我修改了 bashrc 文件以使其生效,但不巧的是我创建云主机时镜像选错了,这台主机之前并没有安装 Hadoop。因此,我安装了 Hadoop,并确保 bashrc 文件生效。
但是随后我发现启动 HDFS 后缺少了 Namenode 进程。经过一系列的检查,我发现自己配置文件中有多处错误,并且忘记初始化 Namenode。最终,我修正了 Hadoop 的依赖文件,并成功初始化了 Namenode,顺利运行了 wordcount 程序。
问题2 提交JAR包的机器错误
在进行在进行分布式部署实验时,我提交了 JAR 包,发现跑不起来。最后,我发现我是在主节点 ecnu01 上监听了 8888 端口并提交了 JAR 包,而不是客户端 ecnu04。我重新打开了两个连接到 ecnu04 上的 shell,在上面重新监听了 8888 端口并提交了 JAR 包,最终成功运行了程序。
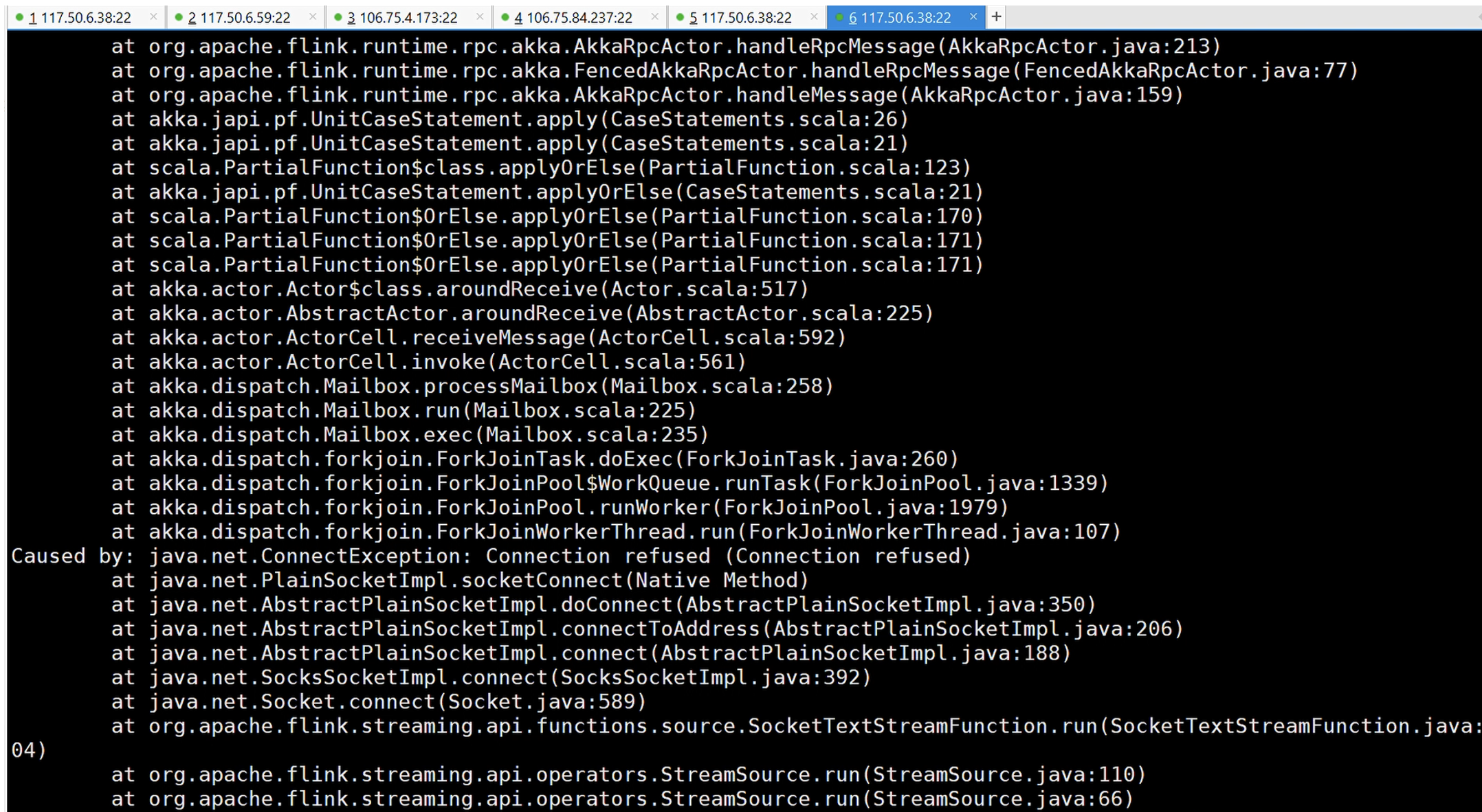
问题3 分布式实验时报错org.apache.flink.client.program.ProgramInvocationException: The main method caused an error: No Executor found. Please make sure to export the HADOOP_CLASSPATH
之所以出现这样的报错是因为我缺少执行器(Executor),换言之就是环境变量没有设置HADOOP_CLASSPATH 或没有将 Hadoop 添加到类路径。我最终的程序是在ecnu04上运行的,所以需要在这上面像最开始ecnu01那样去配置.bashrc并使之生效。当然我也去在ecnu02和ecnu03上面配置.bashrc并source ~/.bashrc,最终就没有报错了。