2022-2023-1期末试卷¶
课程名称: 统计方法与机器学习
课程性质: 专业必修课
一、(本题共20分)
表1是一个不完整的双因素方差分析表。
表1 不完整的双因素方差分析表
| 来源 | 自由度 | 平方和 | 均方 | F统计量 | p值 |
|---|---|---|---|---|---|
| 因素 A | / | / | 0.0833 | 0.05 | 0.952 |
| 因素 B | / | 96.333 | 96.333 | 57.80 | <0.001 |
| 交互效应 AB | 2 | 12.167 | 6.0833 | 3.65 | / |
| 误差 | 6 | 10 | / | ||
| 汇总 | 11 | 118.667 |
请根据表1回答以下问题:
- (2分) 因素A的平方和\(SS_{A}\)是【】。
- (2分) 因素A的自由度为【】。
- (2分) 在实验中,因素B的水平数为【】。
- (2分) 均方误差为【】。
- (2分) 在这个实验中,每种组合的重复次数为【】。
- (5分) 如何计算交互效应的p值?并给定显著性水平 \(\alpha=0.05\),简述如何判断交互效应的显著性。
- (5分) 证明:在双因素方差分析中, \(SS_{T}=SS_{A}+SS_{B}+SS_{AB}+SS_{E}\)。
二、(本题共20分)
现有一个数据集,其中包含400条观测,每条观测有1个因变量 \(y\) 以及20个中心化后的特征 \(x_1, x_2, \dots, x_{20}\)。前5行数据如图1所示。
图1 前 5 条数据的示意图

取显著性水平 \(\alpha=0.05\),现回答以下问题:
- (5分) 同学A想构建利用 \(X_1\) 来预测 \(y\),从而构建了一个一元线性回归模型。请根据图2中Python运行的结果,写出一元线性回归模型,并从一个角度阐述该模型是否显著。
图2 Python 的运行结果(一个特征)
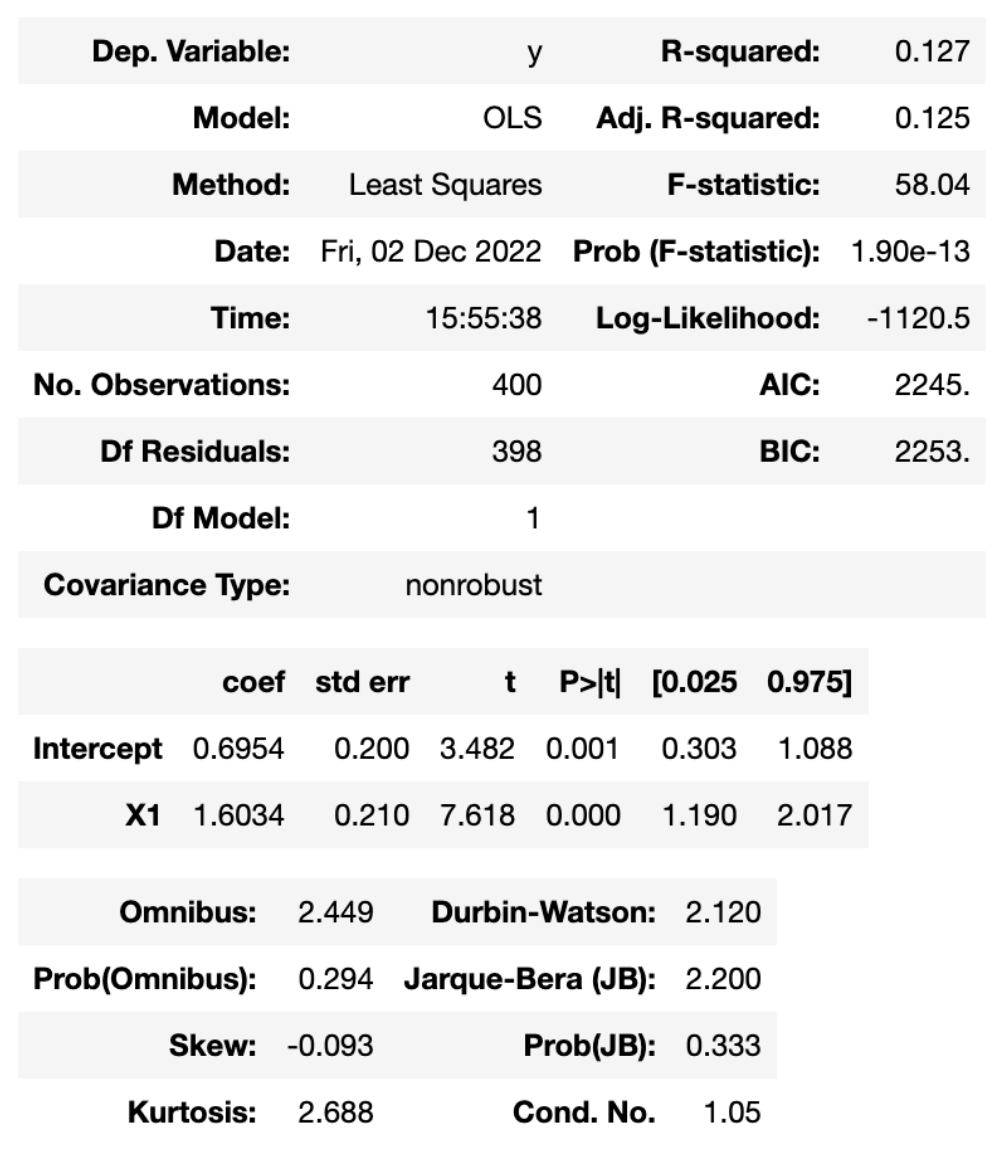
- (5分) 根据图2中Python运行的结果,请给出当 \(X\) 的取值为0.5时, \(y\) 的点预测。同时,阐述如何计算其 \(1-\alpha\) 的预测区间。
- (5分) 同学B将特征 \(X_1\) 和 \(X_2\) 同时纳入线性回归模型,并利用Python得到结果,如图3所示。将图2和图3进行比较,发现在线性回归模型中 \(R^2\) 从0.127提升到了0.320,即结果为 \(R_{mod_1}^2 = 0.127 \le R_{mod_2}^2 = 0.320\)。请问这个结论是否普遍存在?如果是,请证明它;如果不是,请举出反例。
图3 Python 的运行结果(两个特征)
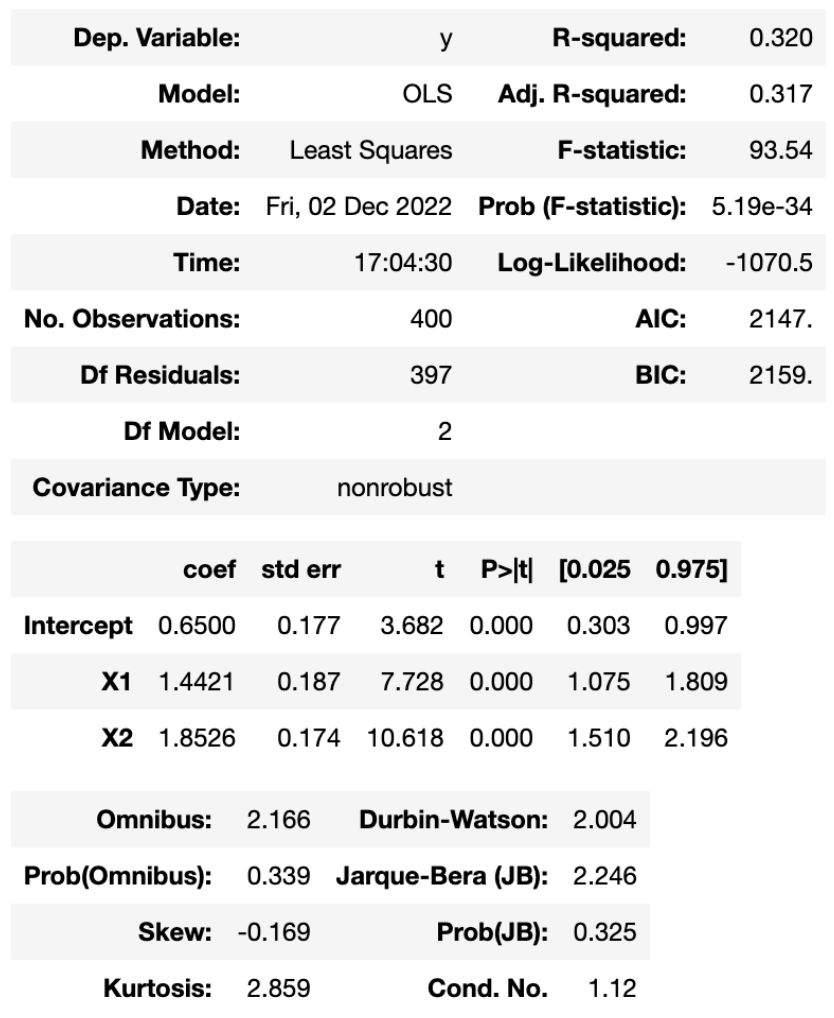
- (5分) 经验所知, \(R^2\) 越大表明特征的拟合效果越好。于是,同学C逐一将特征放入线性回归模型中。具体方案是,第一个模型的特征是 \(X_1\);第二个模型的特征是 \(X_1\) 和 \(X_2\);第三个模型的特征是 \(X_1, X_2\) 和 \(X_3\),以此类推。结果发现 \(R^2\) 的数值如表2所示。
表2 20个模型中不同特征维度下的 \(R^2\) 值
| 维度 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| \(R^2\) | 0.127 | 0.320 | 0.495 | 0.568 | 0.637 | 0.707 | 0.779 | 0.841 | 0.902 | 0.948 |
| 维度 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| \(R^2\) | 0.949 | 0.950 | 0.950 | 0.950 | 0.950 | 0.950 | 0.950 | 0.950 | 0.950 | 0.952 |
请问, \(R^2\) 是否适合作为模型选择的指标?并请说明理由。如果不是,请给出一个改进方案。
三、(本题共10分)
请阐述一下,如何诊断出数据中存在多重共线性?(提示:只需要提供一种完整的方案)。
四、(本题共15分)
比较感知机和线性SVM的损失函数。
五、(本题共10分)
- (5分) 解释生成式模型和判别式模型,并分析二者的不同点;
- (5分) 列出三种判别式模型(3分)和两种生成式模型(2分)。
六、(本题共25分)
考虑利用线性支持向量机对如下两类可分数据进行分类:
+1: (1,1), (2,2), (2,0)
-1: (0,0), (1,0), (0,1)
- (8分) 在图中做出这6个训练点,构造具有最优超平面和最优间隔的权重向量;
- (4分) 哪些是支撑向量?
- (13分) 通过寻找拉格朗日乘子来构造在对偶空间的解,并将它与第一小问中的结果比较。