稿子¶
Memtable 中的 mem 意思是memory,MemTable是一个内存数据结构,他保存了落盘到SST文件前的数据。它是一个内存中的有序 map 结构,它的底层实现是一个跳表。在进行写入时,总是首先写入memtable。
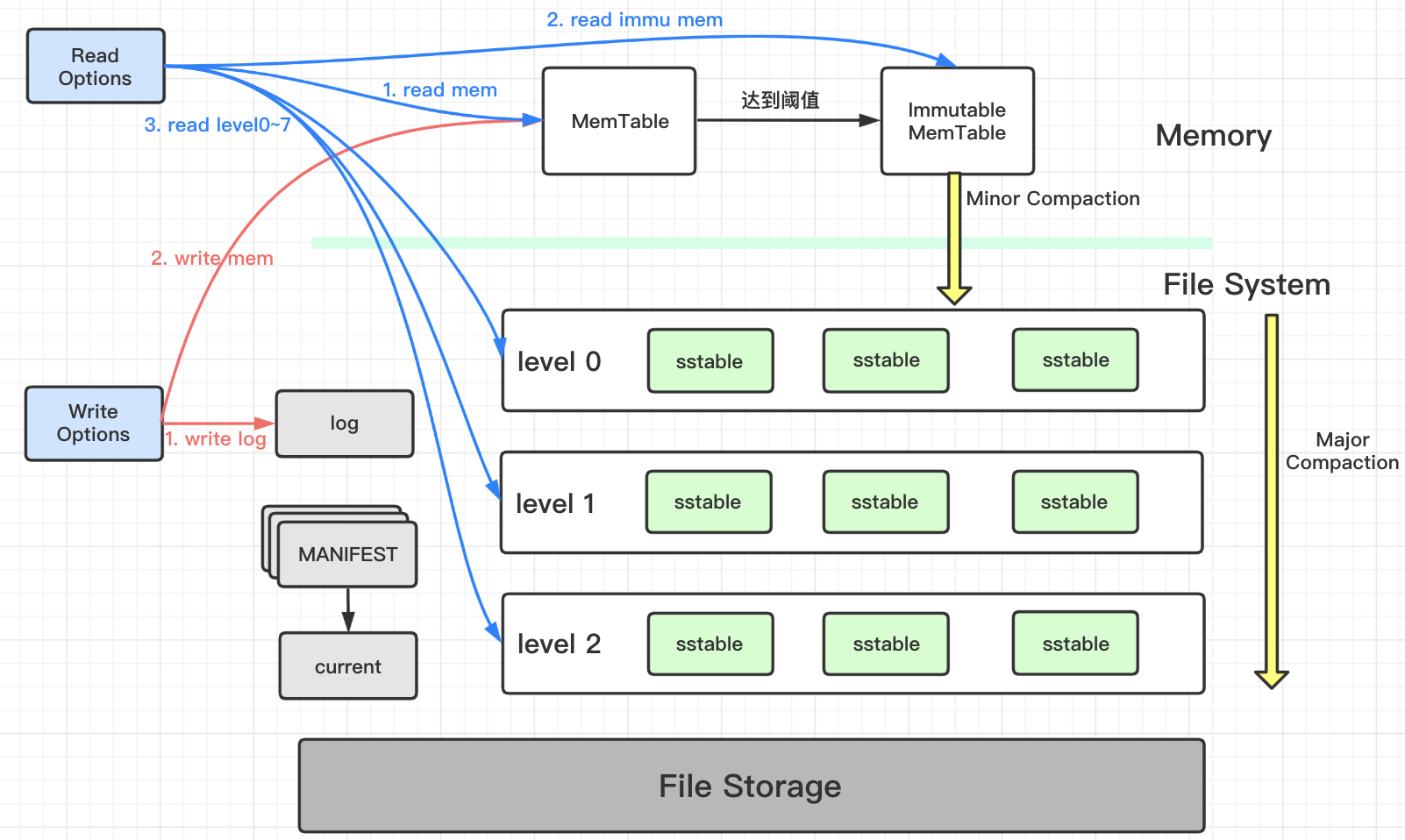
这里放一张LevelDB的架构图,可以看到Memtable同时服务于读和写,新的写入总是将数据插入到memtable,而读取在查询SST文件前总是要查询memtable,因为memtable里面的数据总是更新的。
那Memtable有啥用呢?还是对着架构图来说,它的主要用处包括下面几条:
- 加速写操作:写入的数据首先存储在 MemTable 中,而不是直接写入磁盘文件(如 SSTable)。这避免了频繁的磁盘 I/O,提升了写入性能,这与LevelDB的设计目标也是契合的。
- 批量写入磁盘:MemTable 会在达到一定大小时被“冻结”(标记为Immutable MemTable),并通过后台线程批量写入到磁盘,减少随机写操作的开销,这样做加快了MinorCompaction的速度。
- 提供快速查询:由于 MemTable中存放的是最新的数据,同时它也是内存中的数据结构,查询操作可以非常快速地从 MemTable 中获取数据,而不需要直接访问磁盘。
总而言之,Memtable在LevelDB中所起到的作用是在内存层面提供了一个随机写的容器,对skiplist、arena、comparator进行组合和管理,相当于一层LevelDB对外的屏障屏蔽了底层操作。
实际上Memtable和Immutable Memtable的结构完全相同,只不过前者是可读可写,后者只是可读的而已。那么为什么要有Immutable Memtable呢?
考虑一下没有它的情况。memtable满了之后,后台线程需要将memtable立即flush到新SSTable中,这个过程中难道新的数据还能写入吗?不能!只能在那干等着。新写入的数据处于阻塞状态。
但是如果有它,后台线程并不着急flush,不至于出现阻塞。它的作用便是防止写入时的阻塞。
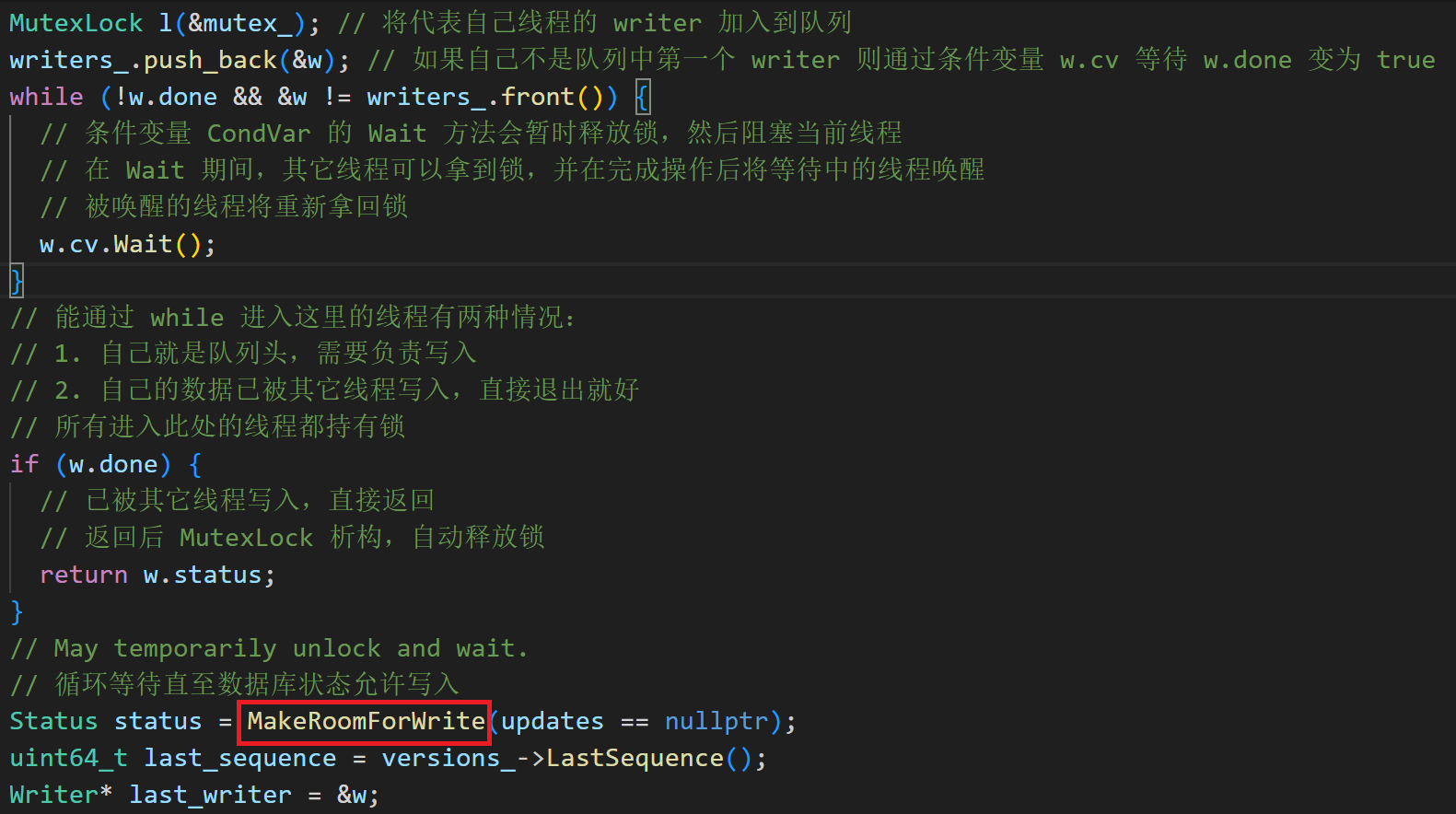
接下来我们以Write为例子介绍memtable的实现,这个函数实现了一个 WriteBatch的写入。作为前置知识,上一个Topic的同学已经较好地讲解了Write的工作原理,让我们先来再看一下它。概括来说,它的流程主要是三步:
- 1每个写线程会将代表的自己的 writer 加入队列
- 2当上一个写线程执行完成时会唤醒队列中第一个 writer 线程, 被唤醒的线程会将队列中所有等待写入的数据写进数据库
- 3然后将已写入的 writer 的 done 置为 true 并唤醒对应的线程,被其它线程完成了写入的 writer 会立即返回
这是一个将多线程写转为单线程写的流程,这样就不用考虑memTable的写并发情况处理。
如图所示,能通过阻塞的线程只有两种情况:要么自己就是队列头需要写入了,要么自己的数据已经被写入了需要退出了。我们重点考虑前者就行,对它来说,我们能从队列中取出的第一个writer线程,在数据库状态为允许写入时,写入之前我们要干什么?数据库允许写了,但是空间不够就尴尬了,我们要先check一下。使用MakeRoomForWrite来确保有足够的空间来进行新的写入操作。
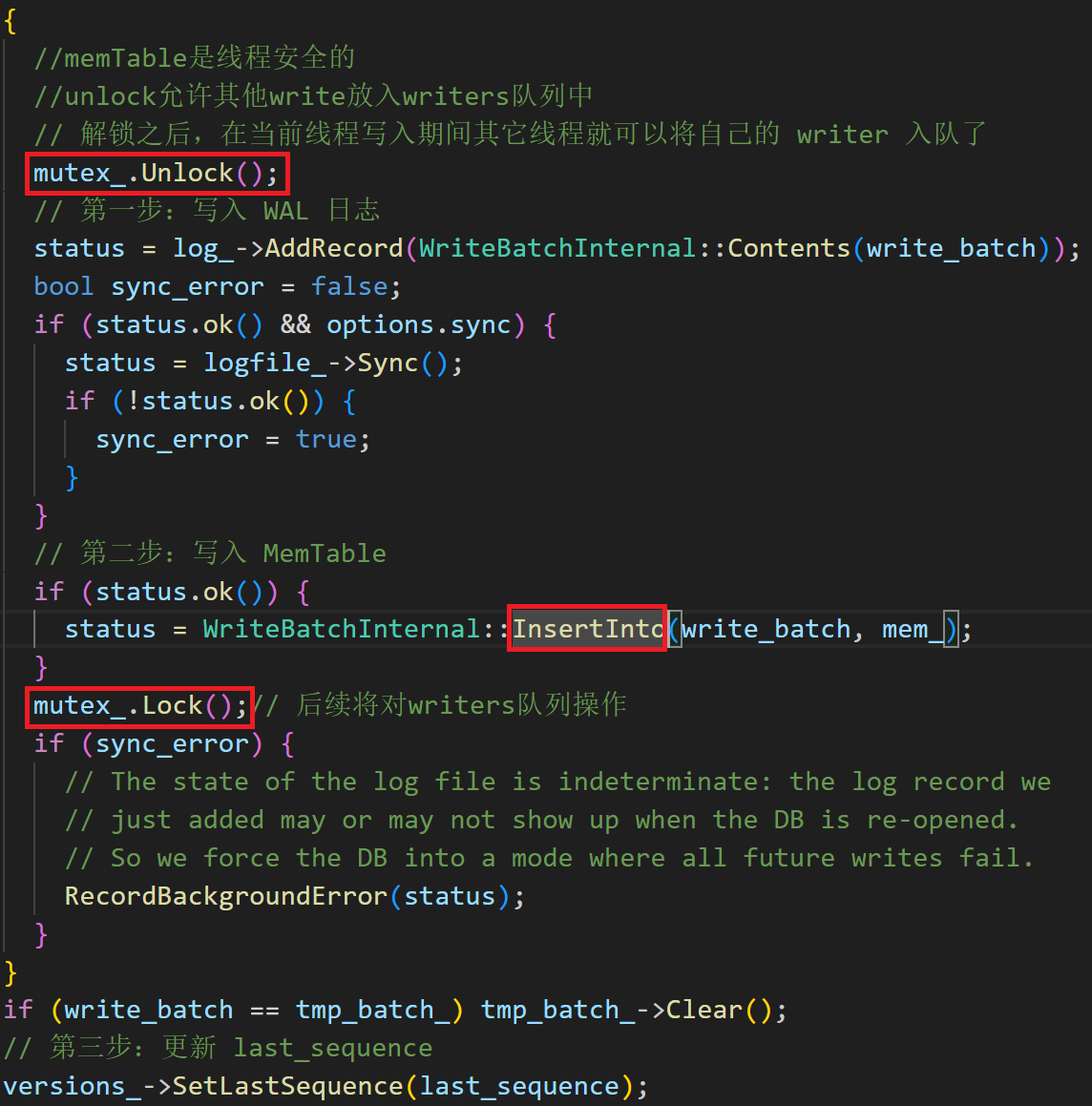
对于具体的写入流程,也分为三步骤:写入 WAL 日志,写入MemTable,更新last_sequence,具体的写入Memtable使用的是InsertInto这个函数。
如图,可以看到线程写入Memtable的过程中是无锁的,这样可以让当前线程写入期间其他线程将自己的Writer入队。从这里我们能看到写入的顺序是先追加到日志,再写入内存数据库。首先我们知道写入分两步:数据写入内存和数据写入日志,我觉得这里在数据插入内存之前就写入日志是因为内存是易失的,先写日志可以方便恢复。
接下来我讲一下MakeRoomForWrite这个函数(核心代码在db/db_impl.cc)
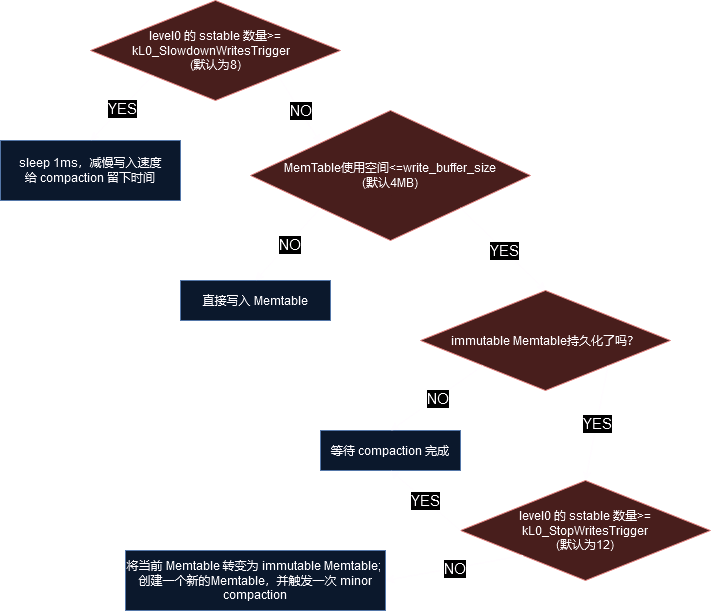
这个函数进入写入前检查,若当前数据库状态不适合写入则会循环等待,直到适合写入,比如说后台 compaction 完成。他的代码还是有点长的,我通过一张流程图来给大家介绍一下检查的项目吧。
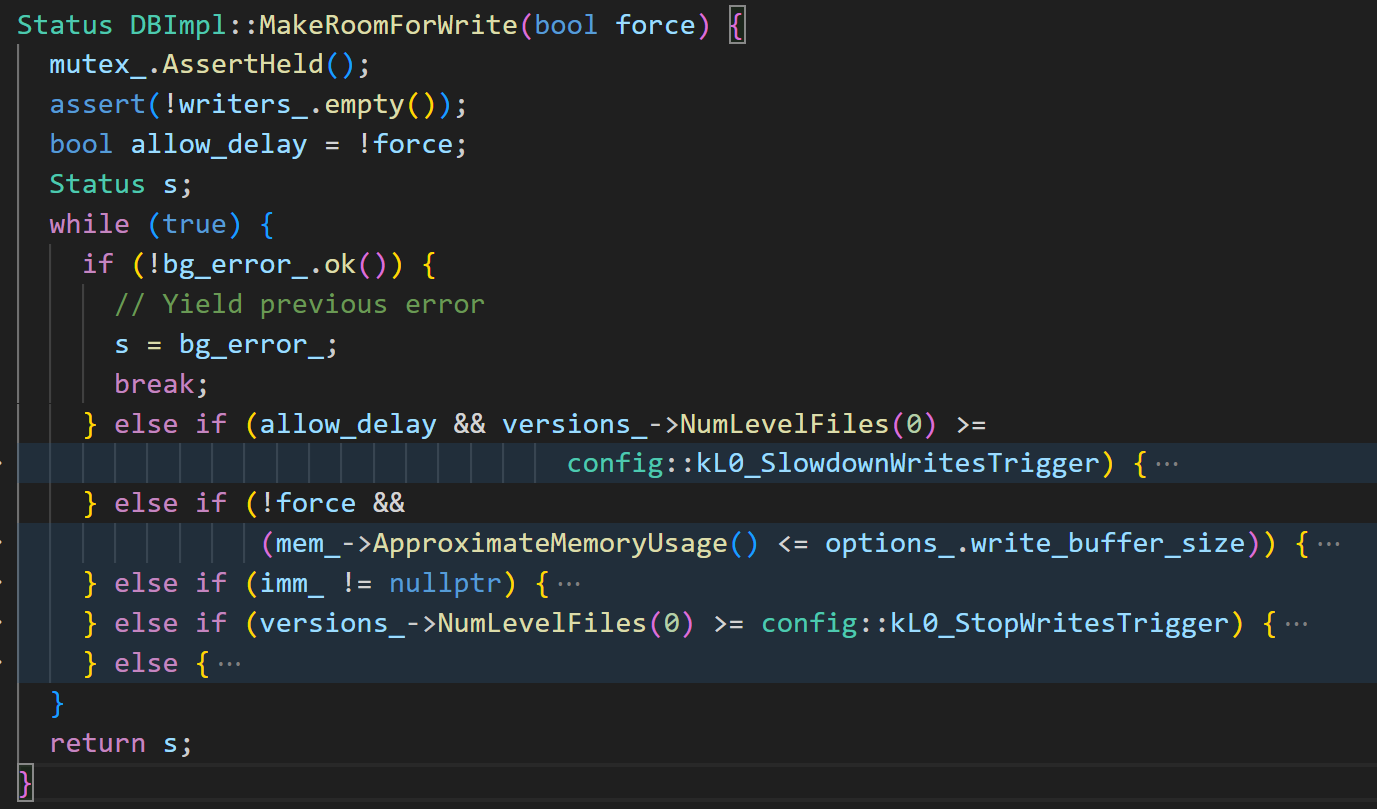
检查的内容包括:
-
检查 level0 的 sstable 数量是否达到了 kL0_SlowdownWritesTrigger (默认为8), 如果是则 sleep 1ms 以减慢写入速度,给 compaction 留下时间
-
检查 mutable MemTable 是否达到了最大值 (write_buffer_size,默认4MB), 如果未达到直接写入 Memtable
-
若 Memtable 已经达到最大值,且 immutable Memtable 尚未持久化,则等待 compaction 完成
-
检查 level0 的 sstable 数量是否达到了 kL0_StopWritesTrigger (默认为12), 如果是则等待 compaction 完成
-
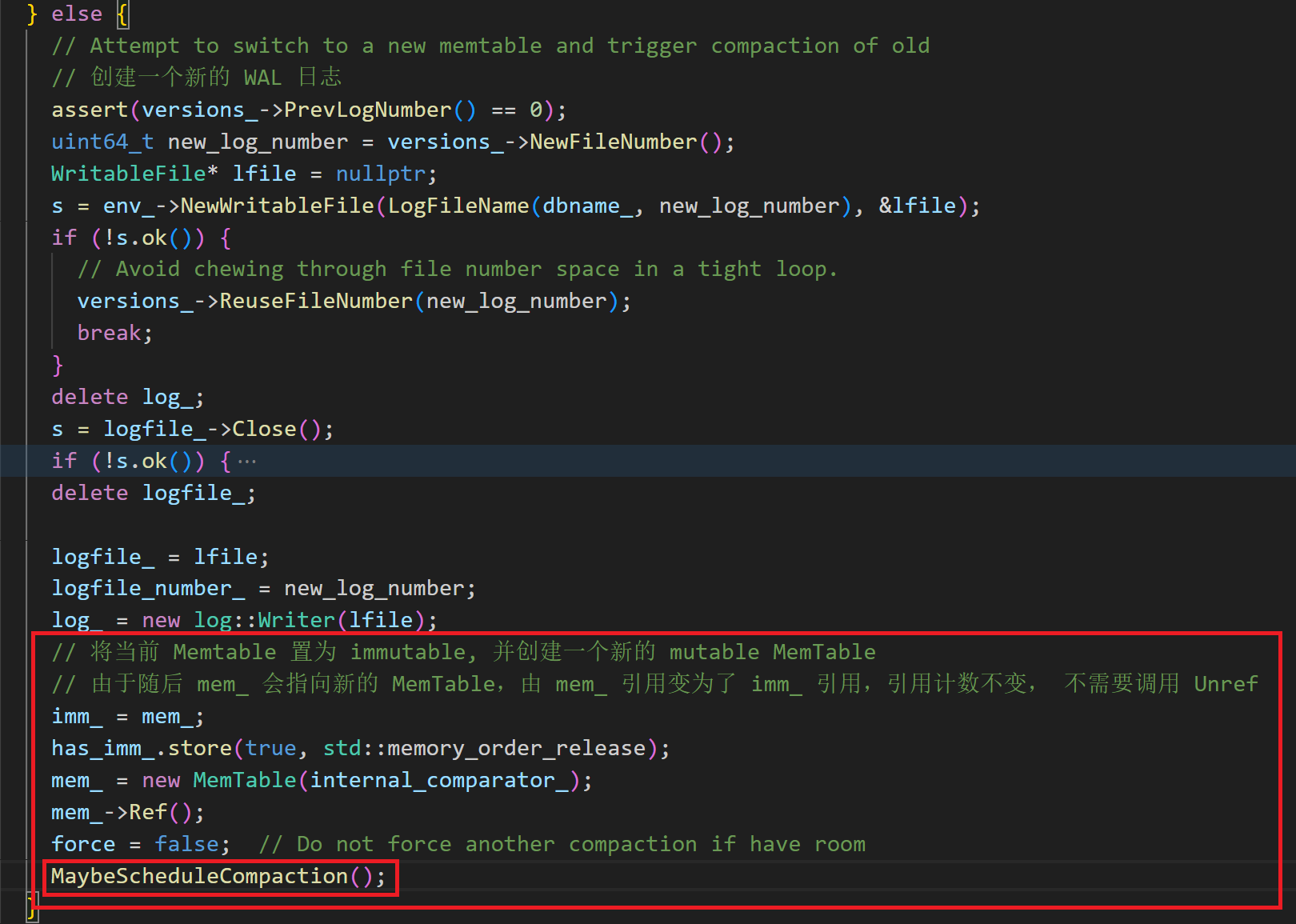
若 Memtable 已经达到最大值,且没有 immutable Memtable 则将当前 Memtable 转变为 immutable, 创建一个新的 mutable Memtable,并触发一次 minor compaction
至于如何把旧的memtable冻结,我刚刚在讲MakeRoomForWrite函数流程时也有所提及。Memtable达到最大值且没有 immutable Memtable时候,则将当前 Memtable 转变为 immutable Memtable, 创建一个新的Memtable,并触发一次 minor compaction。冻结的 MemTable 不再接收新的写入操作,它会被后台线程逐步刷盘到 SSTable 文件。当前情况下的MaybeScheduleCompaction函数尝试做的事情是把immutable memtable压到L0,包括我们熟知的minor compaction。
还有个问题就是写暂停如何产生的,这个问题还是要基于我的那张流程图,如果当前0级文件数量大于等于kL0_StopWritesTrigger:说明0级文件太多,需要暂停写入等待compation完成,直到被唤醒,阻塞线程将进入wait状态。当然还有一种情况会引发写暂停就是Immutable memtable还未持久化:

在我刚刚讲Write的工作原理时,提到了具体的写入Memtable使用的是InsertInto这个函数:

如果要单开它的代码,你可能会觉得比较简单,InsertInto函数构造了MemTableInserter对象,填充sequence和Memtable对象指针。然后调用WriteBatch的Iterate把当前batch的更新记录插入到memtable中。但是实际情况这个并没有这么简单,我们需要一步一步来拆解开细谈。
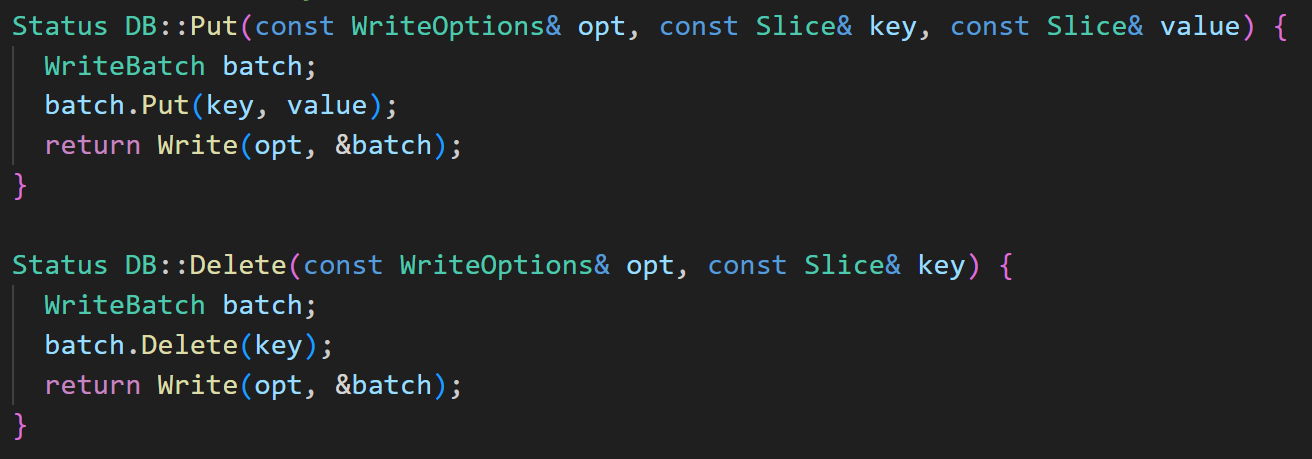
在db_impl.cc中,有写入和删除的入口函数DB::Put(options, key, value)和DB::Delete(options, key)。可以看到这两个方法都首先被打包成一个 WriteBatch,然后再调用Write函数,Write函数的实现上个Topic已经很好地讲解了,我们刚刚也有提及,就不再赘述了,我们重点关注WriteBatch
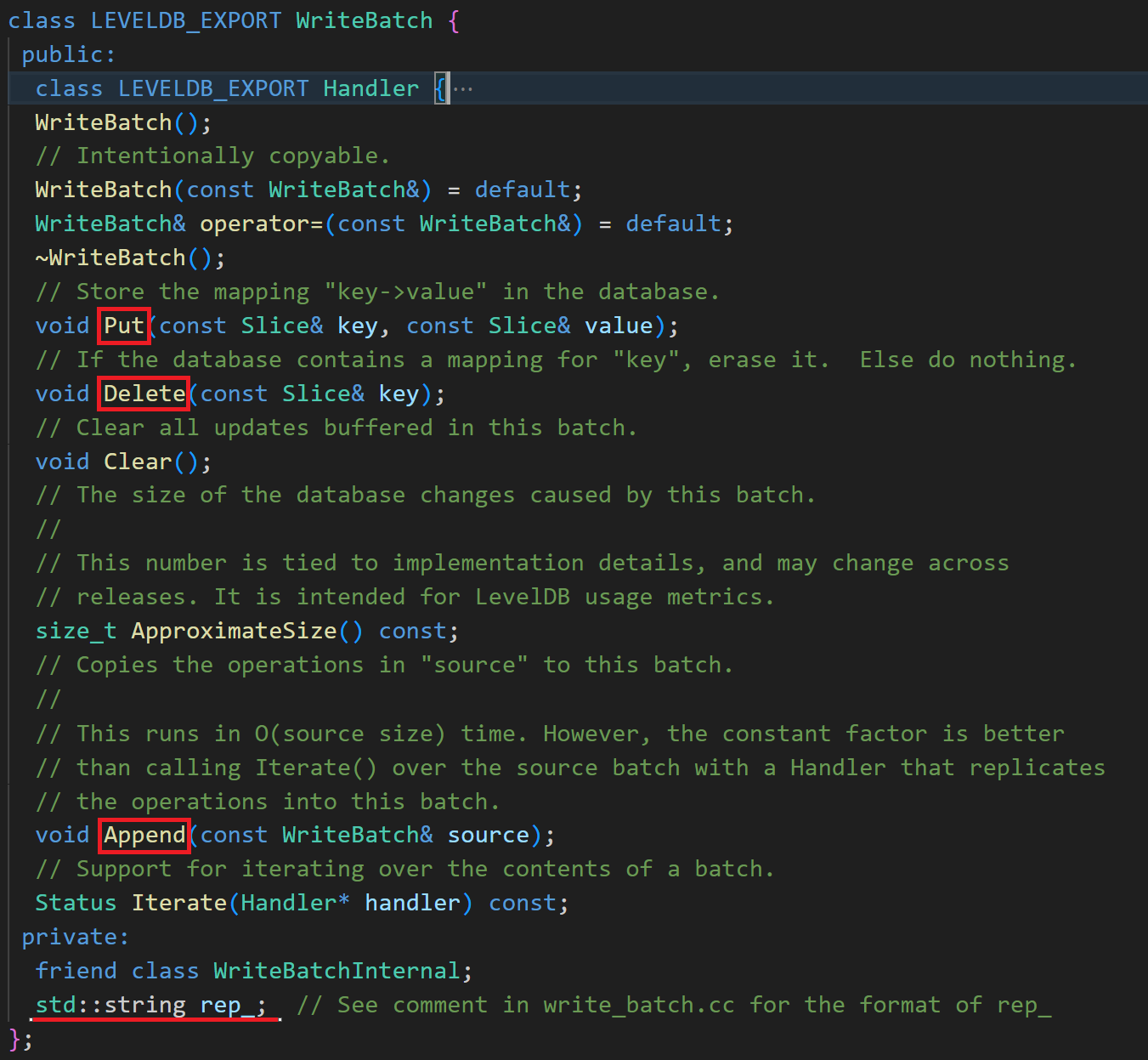
write_batch.h下面有WriteBatch的定义。WriteBatch 接口中除了提到的 Put 和 Delete,还提供了一个 Append 方法可以将其他 WriteBatch 合并过来。另外提供了一个 Iterate 迭代函数和对应的 Handler 类接口,后面会使用到。它只有一个私有成员 rep_。
write_batch_internal.h下面有WriteBatchInternal类的定义,它的样子大概长这样。可以看到类中全部是静态函数,并且附带至少一个 WriteBatch* batch 参数。因为WriteBatchInternal类是WriteBatch类的友元类,所以WriteBatchInternal可以访问WriteBatch的唯一私有成员 rep_。我们对WriteBatch的修改及追加信息,本质上是对rep_这个成员的修改。
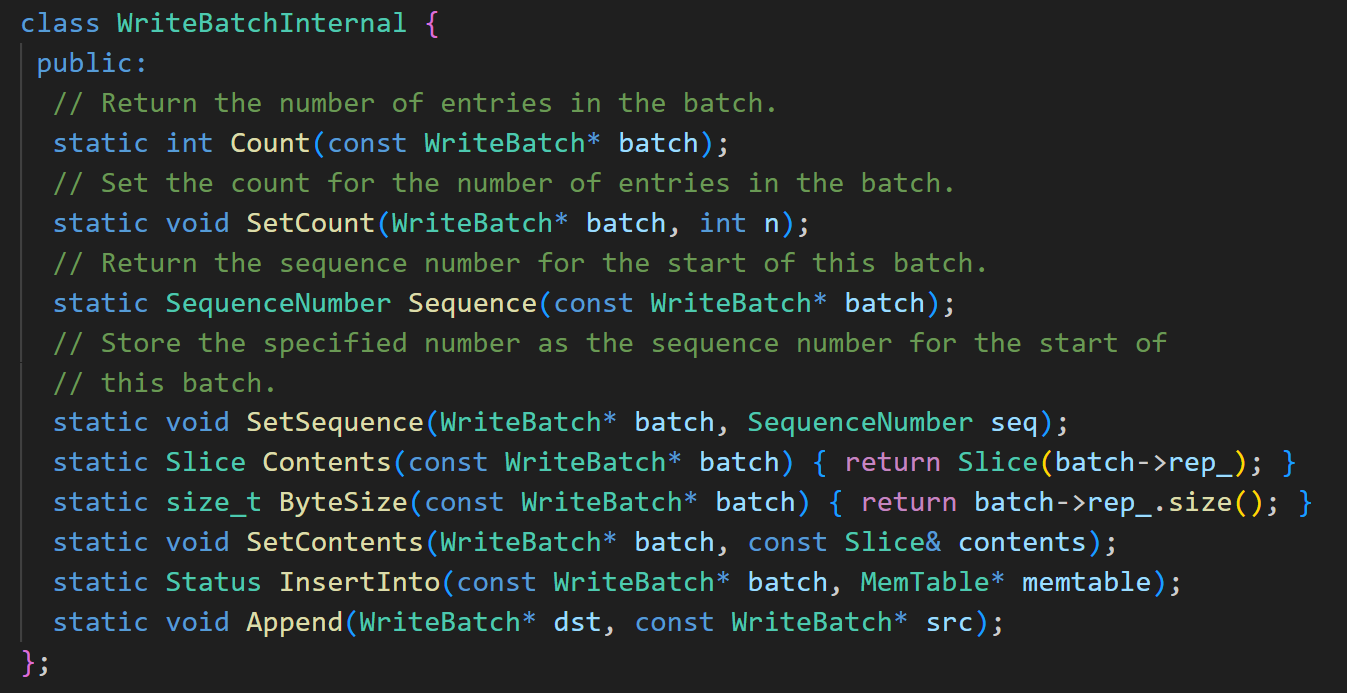
根据WriteBatch那里的注释,我们看write_batch.cc中它具体的样貌长什么。
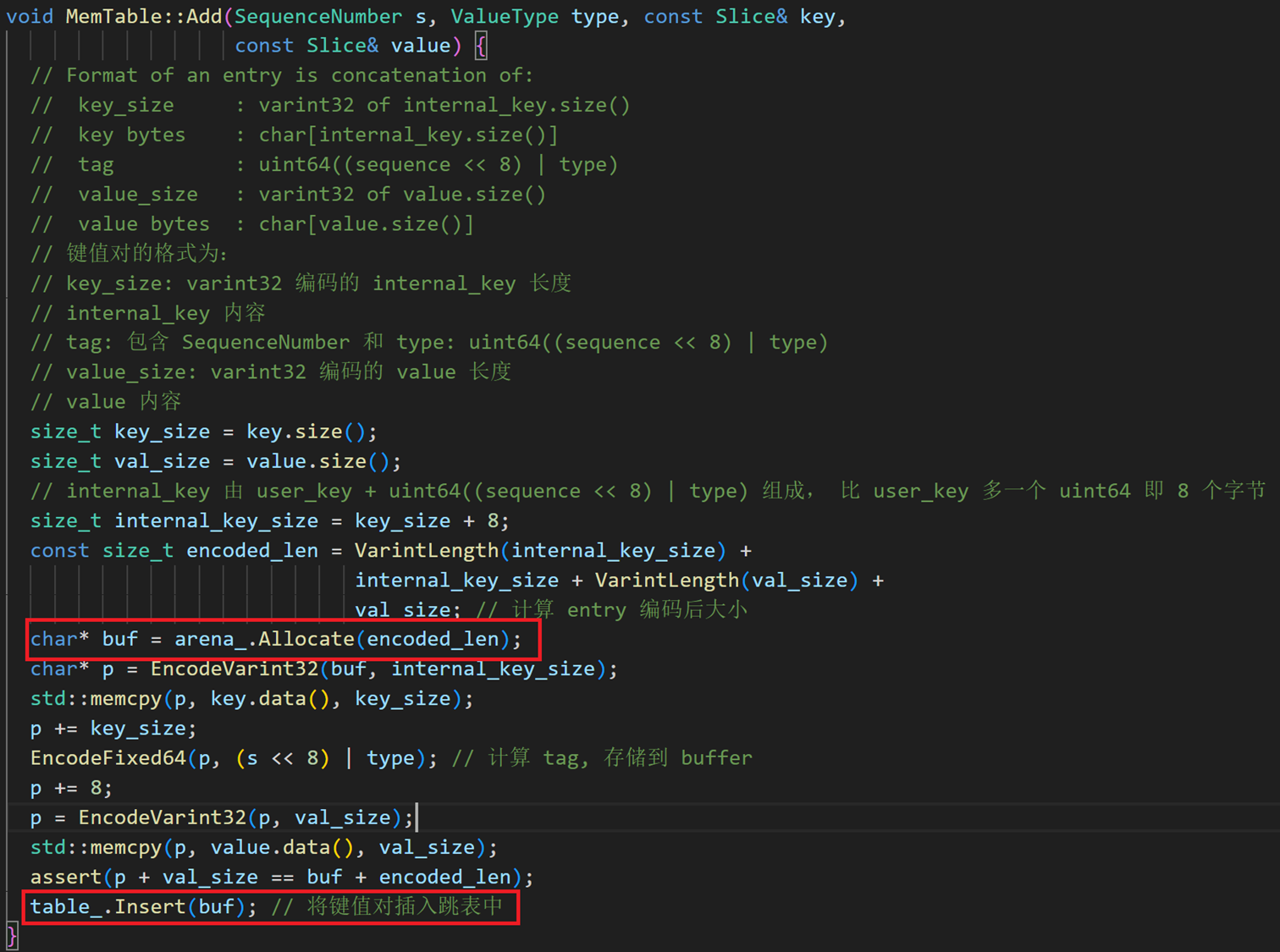
结合它的样貌,我上网查了一下相关资料,发现rep_最开始8个字节用于存储Sequence,表示当前Writebatch中第一个操作所对应的序列号,接下来4个字节用户存储Count,表示当前WriteBatch有多少个Operation,然后紧接着就是count条Operation记录,每一个operation记录就是一个Put操作或者Delete操作。
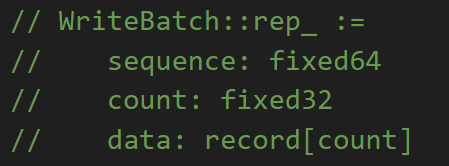
读完了定义,我们就要去db/write_batch.cc来具体看一下两个类的实现了。为了方便阅读我对函数的顺序进行了一些重排,这几个函数其实是和数据的格式对应的。比如说,WriteBatch::rep_ 的前 12 个字节定义为 Header,存储了 sequence number 和 count。EncodeFixed 和 DecodeFixed系列函数实现了数值到字符串的编解码,它们的具体实现竟然是在util/coding.h这个文件而不是util/coding.cc中,感觉有些不大标准,以EncodeFixed32举例让大家看看他在干什么。其实很简单,就是把一个32位的数字转化为了4个8位的字符,转换过程中要注意LevelDB采用的是小端存储方式,比如说0x00001234输入进去,buffer[0]就是0x34,buffer[1]是0x12。
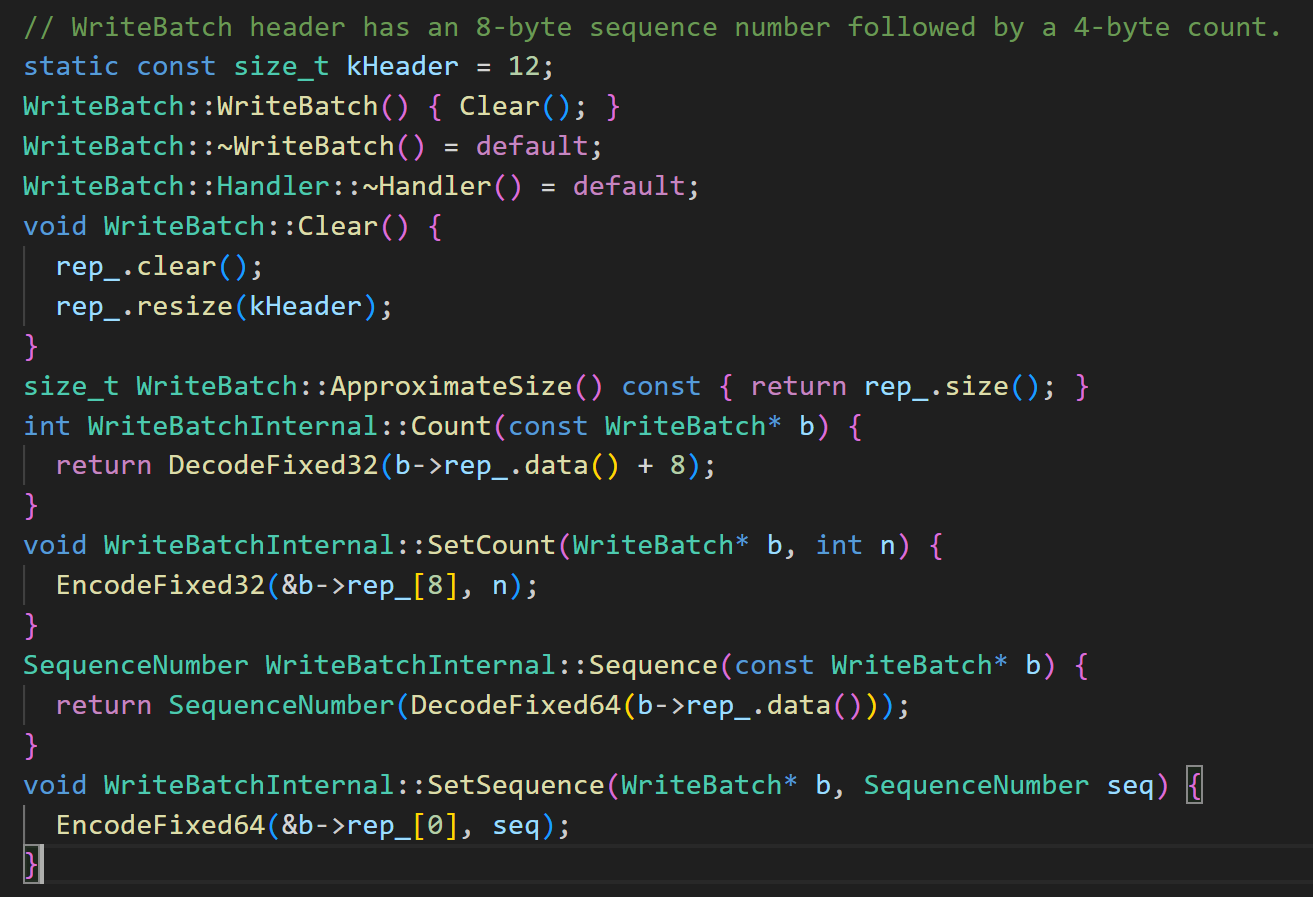
最重要的其实是WriteBatch的几个方法的实现,比如说它的Put,Delete,Append。Put 和 Delete 首先将计数加一,在 rep_ 中写入操作类型,再写入键值对。PutLengthPrefixedSlice 函数会先写入字符串的长度,再写入字符串的内容。WriteBatchInternal 的赋值和追加均是对 rep_ 的进行操作。
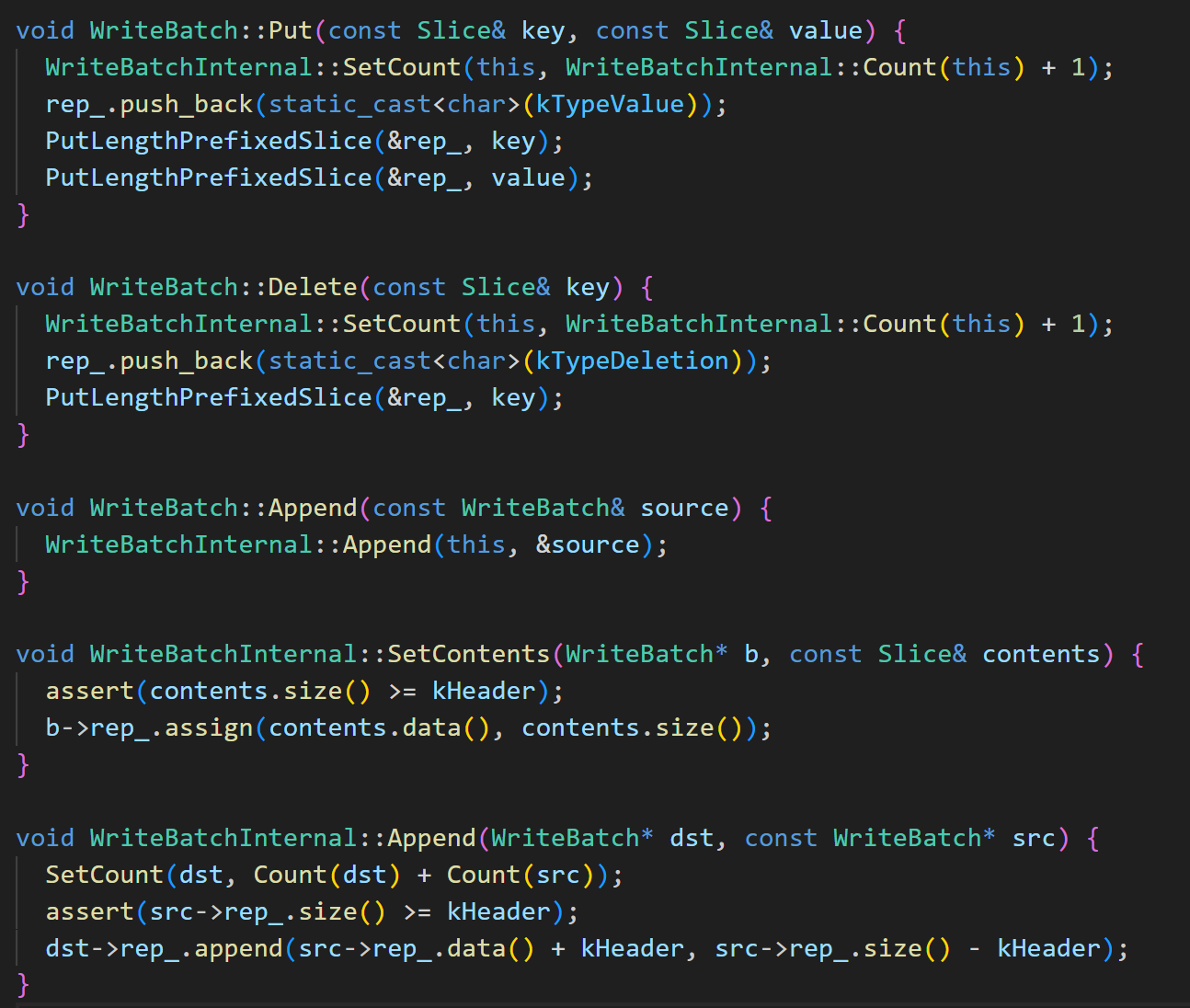
还有个比较关键的是迭代函数和 Handle 的部分。迭代函数 WriteBatch::Iterate 会按照顺序将 rep_ 中存储的键值对操作放到 hander 上执行。
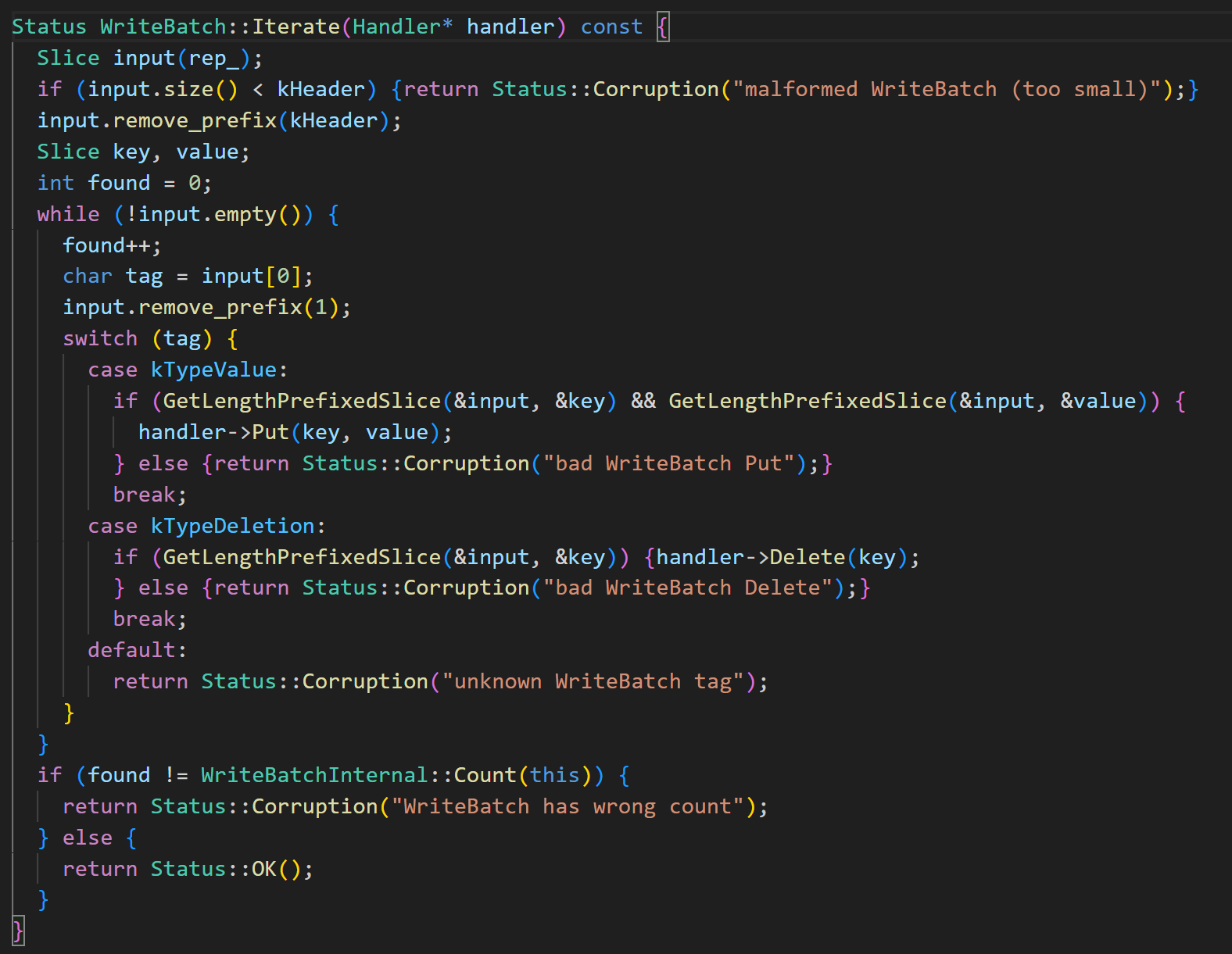
Handle部分这里,下面的匿名空间里定义了一个继承 Handler 的子类 MemTableInserter,将 Put 和 Delete 转到 MemTable 上执行。我们能看到Put和Delete都调用了mem_的Add函数,这是一个小坑,随后我也会介绍。

介绍了这么多相关的函数,我们才能到WriteBatchInternal::InsertInto,它就直接根据 MemTable 构造 MemTableInserter即可。这样做的好处,可能就是 WriteBatch::Iterate 与 MemTable 解耦,Handler 可以自行替换。
综合来看,WriteBatch 将所有的修改和删除操作均存储到一个字符串中,并且提供了内存数据库的迭代接口。
刚刚我们提到了Put和Delete都调用了mem_的Add函数,让我们来看一下它的具体实现。在这里我们能看到Add过程使用Arena进行内存分配,经过格式转换之后最终将数据插入了跳表。
抱着为什么用arena而不是malloc的疑问我多了解了一些,现在向大家介绍它。Arena是一种简单的内存分配器,Arena 会预先分配一大块内存,每次申请对象都从其中连续进行分配。在这个图里面也有它的草图,Arena每次都从OS申请内存都是申请一个block,然后放到blocks_里。其中,第一个指针是当前block里下一次分配内存返回的地址,第二个变量放的是是当前block里剩余可分配的bytes


Arena 中分配的对象不能单独释放,只能和 Arena 一起释放。它可以显著的加快内存分配速度并减少内存碎片的产生。LevelDB经常需要分配小块内存。对于每个小分配使用malloc可能因为开销而效率不高。Arena一次性分配较大的内存块,然后高效地分割出小段。这减少了许多小malloc调用的开销。LevelDB需要跟踪内存使用情况,通过Arena而不是直接malloc可以方便的记录内存使用情况。
leveldb 中的 MemTable 同样会有一个伴生的 Arena,MemTable 中的各种对象都在这个 Arena 上分配,Arena 的生命周期和memTable相同。
刚刚我们也看到了,Add最后将数据插入跳表,insert的本质是跳表的插入,下面请另一位同学向大家详细介绍它。