2024-2025-2-编程作业2¶
2022级,Spark
Word Count¶
待完成:¶
- 请在 DSPPCode.spark.warm_up.impl 中创建 WordCountImpl, 继承 WordCount, 实现抽象方法
题目描述:¶
-
现存在一份英文文本文件,要求统计文本中每个单次出现的次数,并将计数结果输出到文本中。
-
输入格式:
apple pen applepen pineapple pineapplepen boy cat dog boy cat
dog cat dog dog
- 输出格式:
(pen,1)
(pineapple,1)
(dog,4)
(pineapplepen,1)
(apple,1)
(applepen,1)
(boy,2)
(cat,3)
代码略
Pi¶
难易程度:*易¶
待完成:¶
- 请在 DSPPCode.spark.pi.impl 中创建 PiSimulatorImpl, 继承 PiSimulator, 实现抽象方法
题目描述:¶
- 蒙特卡罗(Monte Carlo)算法计算圆周率的主要思想如下: 给定边长为R的正方形,画其内切圆,然后在正方形内随机打点,设点落在圆内的概为P,则根据概率学原理: P = 落在圆内点的数量/正方形内点的数量 = 圆面积 / 正方形面积 = PI * R * R / 2R * 2R = PI / 4。即 PI=4P。 这样,当随机打点足够多时,统计出来的概率就非常接近于PI的四分之一了。请根据蒙特卡洛思想来估计 Pi 的值。
PiSimulatorImpl¶
package DSPPCode.spark.pi.impl;
import DSPPCode.spark.pi.question.PiSimulator;
import org.apache.spark.api.java.JavaRDD;
import java.util.Random;
public class PiSimulatorImpl extends PiSimulator {
@Override
public JavaRDD<Integer> sampledPoint(JavaRDD<Integer> parallelInput) {
return parallelInput.map(Integer ->
(Math.pow(Math.pow(new Random().nextFloat(), 2) + Math.pow(new Random().nextFloat(), 2), 0.5) <= 1) ? 1 : 0);
}
}
Revised KMeans¶
难易程度: ** 中¶
待完成:¶
- 请在DSPPCode.spark.revised_kmeans.impl中创建RevisedKmeansImpl,继承ReviseKmeans,实现抽象方法
题目描述:¶
- 使用广播变量机制实现KMeans算法,求聚类中心点。
-
本题中,迭代终止条件为满足一定的迭代次数或相邻两次迭代的聚类中心之间的距离小于某一阈值。(以欧氏距离作为距离度量方式)
-
输入:
输入文件有两个,all_points包含了所有点的坐标,init_k_points包含了K个初始聚类中心点的坐标。 输入文件每行按逗号分割成两个整数,表示一个二维点。
all_point:
4,400 96,826 606,776 474,866 400,768 2,920 356,766init_k_points:98,176 5,68 466,272 -
输出:
输出所有点的聚类结果,格式为:坐标1,坐标2 所属类别(类别编号从0开始计)。
4,400 1 96,826 0 606,776 2 474,866 2 400,768 2 2,920 0 356,766 2
RevisedKmeansImpl¶
package DSPPCode.spark.revised_kmeans.impl;
import DSPPCode.spark.revised_kmeans.question.RevisedKmeans;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.broadcast.Broadcast;
import java.util.List;
import scala.Tuple2;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import java.util.ArrayList;
import org.apache.spark.api.java.function.Function;
public class RevisedKmeansImpl extends RevisedKmeans{
@Override
public Integer closestPoint(List<Integer> p, Broadcast<List<List<Double>>> kPoints) {
Integer bestIndex = 0;
Double closest = Double.MAX_VALUE;
List<List<Double>> kPointsValue = kPoints.value();
for (int i = 0; i < kPointsValue.size(); i++) {
Double dist = distanceSquared(p, kPointsValue.get(i));
if (dist < closest) {
closest = dist;
bestIndex = Integer.valueOf(i);
}
}
return bestIndex;
}
@Override
public Broadcast<List<List<Double>>> createBroadcastVariable(JavaSparkContext sc,
List<List<Double>> localVariable) {
Broadcast<List<List<Double>>> broadcastKPoints = sc.broadcast(localVariable);
return broadcastKPoints;
}
@Override
public List<List<Double>> iterationStep(JavaRDD<List<Integer>> points,
Broadcast<List<List<Double>>> broadcastKPoints) {
int counter = 0;
List<List<Double>> kPoints = broadcastKPoints.value();
JavaPairRDD<Integer, Tuple2<List<Integer>, Integer>> closest = getClosestPoint(points, broadcastKPoints);
// 按类别号标识聚合,并计算新的聚类中心
List<List<Double>> newPoints = getNewPoints(closest);
List<List<Double>> emptyPoints = new ArrayList<>();
for (int ii = 0;ii< newPoints.size();ii++)
{
double sum = 0.0;
for (int j = 0; j < kPoints.get(ii).size(); j++) {
sum += Math.pow(kPoints.get(ii).get(j) - newPoints.get(ii).get(j), 2);
}
if (Math.pow(sum,0.5)<=DELTA)
{
counter+=1;
}
}
if (counter == newPoints.size())
{
return emptyPoints;
}
else
{
return newPoints;
}
}
}
KNN¶
难易程度:** 中¶
待完成¶
- 请在 DSPPCode.spark.knn.impl 中创建 KNNImpl,继承 KNN,实现抽象方法。
题目描述¶
-
要求:给定训练数据集和查询数据集,使用 KNN 算法完成对查询数据集的分类。(注意:当一条数据对应多个类别的权重相等时,请选择序号较小的类别。)
-
输入格式
训练数据集:每行 n+2 个数字,分别是数据 id、类别 id、n 维特征,中间使用空格分割。
1 0 1.0 0.9
2 1 0.2 0.3
3 0 0.8 0.7
4 1 0.1 0.2
5 0 0.8 0.8
6 1 0.2 0.2
查询数据集:每行 n+1 个数字,分别是数据 id、n 维特征,中间使用空格分割。
7 0.8 0.9
8 0.2 0.1
- 输出格式
查询数据集类别:每行 2 个数字,分别是数据 id、类别 id,中间使用逗号分割。
7,0
8,1
KNNImpl¶
package DSPPCode.spark.knn.impl;
import DSPPCode.spark.knn.question.Data;
import DSPPCode.spark.knn.question.KNN;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class KNNImpl extends KNN {
public KNNImpl(int k) {
super(k);
}
@Override
public JavaPairRDD<Data, Data> kNNJoin(JavaRDD<Data> trainData, JavaRDD<Data> queryData) {
return trainData.cartesian(queryData);
}
@Override
public JavaPairRDD<Integer, Tuple2<Integer, Double>> calculateDistance(JavaPairRDD<Data, Data> data) {
return data.mapToPair(new PairFunction<Tuple2<Data, Data>, Integer, Tuple2<Integer, Double>>() {
@Override
public Tuple2<Integer, Tuple2<Integer, Double>> call(Tuple2<Data, Data> t) {
Data train = t._1;
Data query = t._2;
double[] trainFeatures = train.x;
double[] queryFeatures = query.x;
double sum = 0.0;
for (int i = 0; i < trainFeatures.length; i++) {
double diff = trainFeatures[i] - queryFeatures[i];
sum += diff * diff;
}
double distance = Math.sqrt(sum);
return new Tuple2<>(query.id, new Tuple2<>(train.y, distance));
}
});
}
@Override
public JavaPairRDD<Integer, Integer> classify(JavaPairRDD<Integer, Tuple2<Integer, Double>> distances) {
// Use combineByKey to combine distances
JavaPairRDD<Integer, List<Tuple2<Integer, Double>>> combinedDistances = distances.combineByKey(
// CreateCombiner: initialize a list with the first value
(Tuple2<Integer, Double> value) -> {
List<Tuple2<Integer, Double>> list = new ArrayList<>();
list.add(value);
return list;
},
// MergeValue: add each new value to the list
(List<Tuple2<Integer, Double>> list, Tuple2<Integer, Double> value) -> {
list.add(value);
return list;
},
// MergeCombiners: merge two lists
(List<Tuple2<Integer, Double>> list1, List<Tuple2<Integer, Double>> list2) -> {
list1.addAll(list2);
return list1;
}
);
JavaPairRDD<Integer, Integer> classifiedData = combinedDistances.mapToPair(group -> {
Integer queryId = group._1();
List<Tuple2<Integer, Double>> neighbors = group._2();
// 通过距离来排序邻居
neighbors.sort(Comparator.comparingDouble(Tuple2::_2));
// 用Hashmap来计数标签
Map<Integer, Integer> labelCount = new HashMap<>();
int count = 0;
for (Tuple2<Integer, Double> neighbor : neighbors) {
if (count < k) {
int label = neighbor._1();
labelCount.put(label, labelCount.getOrDefault(label, 0) + 1);
count++;
} else {
break;
}
}
// 最频繁的标签
int mostFrequentLabel = -1;
int maxCount = -1;
for (Map.Entry<Integer, Integer> entry : labelCount.entrySet()) {
if (entry.getValue() > maxCount || (entry.getValue() == maxCount && entry.getKey() < mostFrequentLabel)) {
mostFrequentLabel = entry.getKey();
maxCount = entry.getValue();
}
}
return new Tuple2<>(queryId, mostFrequentLabel);
});
return classifiedData;
}
}
LogisticRegression¶
难易程度: *** 难¶
待完成:¶
- 请在 DSPPCode.spark.logistic_regression.impl 中创建 IterationStepImpl,继承IterationStep,实现抽象方法。
题目描述:¶
- 背景:二项逻辑斯蒂回归模型是机器学习中经典的分类模型,求解方法简述如下。
逻辑斯蒂回归模型通过拟合一个线性函数,再通过sigmoid函数输出 [0,1] 区间的概率值,通过概率值来判断因变量的类别,一般以 0.5 为分界,判断样本类别。如下式(由于 idea 不解析 md 中的数学公式,因此以如图片形式给出),
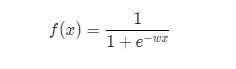
我们使用对数似然函数作为代价函数,如下式。其中 N 为样本数量
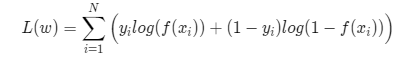
然后使用梯度下降算法求解参数 w,如下式(推导过程略),其中 \(\alpha\) 为学习率(步长)
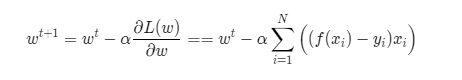
- 要求:使用梯度下降算法求解二项逻辑斯谛回归(Logistic Regression)模型参数。
在 DSPPCode.spark.logistic_regression.question.LogisticRegressionRunner 中已给出 Spark 程序拓扑,但其中求解参数部分需要同学们来实现。 需要完成的内容包括如下三部分:
- 按照上文给出公式,结合逻辑斯蒂回归算法的原理,求解梯度,实现 IterationStepImpl -> VectorSumImpl 和 IterationStepImpl -> ComputeGradientImpl。
- 实现模型的迭代步,更新参数 IterationStepImpl -> runStep(请使用给定的学习率)。
-
实现迭代终止条件,IterationStepImpl -> termination,当参数变化平方距离小于阈值(0.01)时停止迭代。
-
输入格式
0.0 0.4419053154730548 0.21940794898278793
1.0 -0.24986663689089594 -0.40699028639933776
0.0 -0.4190223619272205 -0.015377204367344577
1.0 -0.11722140739872688 -0.6966434026780435
0.0 -0.8909445130708751 0.7862133923906502
1.0 1.5023071496873626 0.5784870753345065
0.0 0.7105062239438624 -1.3402327822135738
1.0 -0.5096444592532914 1.0537576978720287
0.0 -1.1903496491990075 -0.14927846172563708
1.0 -0.5035510019650835 1.0210160806416415
第一列表示数据的类别 1.0 或 0.0,第二列到最后一列表示数据不同维度上的值,数据类型均为 double。即
- 输出格式
w0,0.82
w1,1.02
第一列为模型参数下标,第二列为对应下标的模型参数值。上面展示维度为 2 的数据经计算后的参数结果。
IterationStepImpl¶
package DSPPCode.spark.logistic_regression.impl;
import DSPPCode.spark.logistic_regression.question.DataPoint;
import DSPPCode.spark.logistic_regression.question.IterationStep;
import org.apache.spark.api.java.JavaRDD;
public class IterationStepImpl extends IterationStep {
/**
* 终止条件,当新的权重和旧的权重平方距离小于阈值时迭代终止
*
* @param old 上次迭代的权重
* @param newWeight 新的权重
* @return 是否满足终止条件
*/
@Override
public boolean termination(double[] old, double[] newWeight) {
double squaredDistance = 0.0;
for (int i = 0; i < old.length; i++) {
squaredDistance += (old[i] - newWeight[i]) * (old[i] - newWeight[i]);
}
return squaredDistance < THRESHOLD;
}
/**
* 利用梯度下降法进行一次迭代
*
* @param points 数据点
* @param weights 权重向量
* @return 利用梯度下降法迭代一次求出的权重向量
*/
@Override
public double[] runStep(JavaRDD<DataPoint> points, double[] weights) {
double[] gradient = points.map(new ComputeGradientImpl(weights))
.reduce(new VectorSumImpl());
// 更新权重
double[] newWeights = new double[weights.length];
for (int i = 0; i < weights.length; i++) {
newWeights[i] = weights[i] - STEP * gradient[i];
}
return newWeights;
}
/**
* 向量求和实现
* result[i] = a[i] + b[i]
*/
public static class VectorSumImpl extends VectorSum {
@Override
public double[] call(double[] a, double[] b) throws Exception {
double[] result = new double[a.length];
for (int i = 0; i < a.length; i++) {
result[i] = a[i] + b[i];
}
return result;
}
}
/**
* 计算梯度的实现
* 根据公式:w^{t+1} = w^t - alpha * sum((f(x_i) - y_i) * x_i)
* 这里我们返回 (f(x_i) - y_i) * x_i,外面再处理求和和学习率
*/
public static class ComputeGradientImpl extends ComputeGradient {
public ComputeGradientImpl(double[] weights) {
super(weights);
}
@Override
public double[] call(DataPoint dataPoint) throws Exception {
double[] x = dataPoint.x;
double y = dataPoint.y;
// 计算 sigmoid(wx)
double wx = 0.0;
for (int i = 0; i < x.length; i++) {
wx += weights[i] * x[i];
}
double sigmoid = 1.0 / (1.0 + Math.exp(-wx));
// 计算梯度 (sigmoid(wx) - y) * x
double[] gradient = new double[x.length];
for (int i = 0; i < x.length; i++) {
gradient[i] = (sigmoid - y) * x[i];
}
return gradient;
}
}
}