2024春实验标准答案和常见错误¶
lab2¶

标准答案:
def train(self, x, y, k = 8):
'''
x and y are the data for traning a linear regression
k is the batch size
please simply update the value of self.w and not include any other parameters
'''
# ===========
# todo '''使用小批量随机梯度下降法优化对self.w进行更新'''
beta0 = np.expand_dims(np.ones_like(x), axis=1)
beta1 = np.expand_dims(x, axis=1)
x = np.concatenate([beta1, beta0], axis=1)
for i in range(self.epoch):
ids = np.arange(len(x))
random.shuffle(ids)
iter_num = int(np.ceil(len(x)*1./k))
for n in range(iter_num):
delta_w = []
for j in ids[n*k: (n+1)*k]:
xii = x[j]
yii = y_train[j]
delta_w += [np.dot(xii, yii - np.dot(xii, self.w))]
self.w += self.lr*(np.mean(delta_w, 0))
# ===========
扣分点:没有使用到小批量
def train(self, x, y, k = 8):
'''
x and y are the data for traning a linear regression
k is the batch size
please simply update the value of self.w and not include any other parameters
'''
# ==========
# todo '''使用小批量随机梯度下降法优化对self.w进行更新'''
theta0 = np.expand_dims(np.ones_like(x), axis=1)
theta1 = np.expand_dims(x, axis=1)
theta = np.concatenate([theta1, theta0], axis=1)
for i in range(self.epoch):
print("循环次数: ", i, "参数 w_train = ", self.w)
grad = theta.T.dot(theta.dot(self.w)-y)*2.0/len(theta)
self.w=self.w-self.lr*grad
# ==========
扣分点:没有随机
def train(self, x, y, k=8):
n = x.shape[0]
for _ in range(self.epoch):
for i in range(0, n, k):
x_batch = x[i:i+k]
y_batch = y[i:i+k]
beta0 = np.expand_dims(np.ones_like(x_batch), axis=1)
beta1 = np.expand_dims(x_batch, axis=1)
x_batch = np.concatenate([beta1, beta0], axis=1)
y_pred = np.dot(x_batch, self.w)
error = y_pred - y_batch
gradient = np.dot(x_batch.T, error) / k
self.w -= self.lr * gradient
return self.w
扣分点:使用adam
num_batch = x.shape[0] // k
for epoch in range(self.epoch):
for batch in range(num_batch):
params = {"w": self.w}
optimizer = Adam(params, lr=self.lr)
grad = {}
batch_x = x[batch * k: (batch + 1) * k]
batch_y = y[batch * k: (batch + 1) * k]
predictions = self.predict(batch_x)
errors = predictions - batch_y
dw = 2 * np.dot(batch_x.T, errors) / k
grad['w'] = dw
self.w = optimizer.update(params, grad)['w']
扣分点:只选取第一个批量做梯度下降
w = self.w
for i in range(self.epoch):
np.random.shuffle(data)
x_batch = data[0:k, :2]
y_batch = data[0:k, 2:3]
grads = 0
for i in range(k):
x_ = np.array(x_batch[i])
y_ = np.array(y_batch[i])
x_.resize(len(x_), 1)
y_.resize(len(y_), 1)
c = np.matmul(-1 * x_, y_ - np.matmul(x_.T, w))
grads = grads + c[0]
grads = grads / k
w = w - grads * self.lr
lab3¶
参考答案
def softmax(X):
'''
X is the input
PLease compute its softmax outputs
'''
X_exp = X.exp()
partition = X_exp.sum(dim=1, keepdim=True)
return X_exp / partition
def manual_backward(self, X, y, y_hat):
'''
X is the input feature;
y is the ground truth label;
y_hat is the predicted label.
PLease update self.linear.weight and self.linear.bias
'''
with torch.no_grad():
y_onehot = torch.nn.functional.one_hot(y.long(), self.num_classes)
delta_w = - torch.matmul(torch.t(X), (y_hat - y_onehot))/y.size(0)
self.linear.weight += self.lr * torch.t(delta_w)
delta_b = - torch.sum((y_hat - y_onehot), dim=0)/y.size(0)
self.linear.bias += self.lr * delta_b
扣分点:偏导数没算对
def manual_backward(self, X, y, y_hat):
with torch.no_grad():
self.linear.weight -= self.lr * torch.matmul(X.T, (y_hat - y))
self.linear.bias -= self.lr * torch.sum(y_hat - y ,dim = 0)
扣分点:没有更新偏置
def manual_backward(self, X, y, y_hat):
with torch.no_grad():
alpha = 0.0001
N = X.shape[0]
# y: 1,2,0 --> [010][001][100]
y_cp = torch.zeros(y.shape[0], 3)
y_cp[torch.arange(y.shape[0]), y.long()] = 1
dW = -1 / N * (y_cp - y_hat).T @ X
self.linear.weight -= alpha * dW
lab4¶
标准答案
class Relu:
def __init__(self):
self.mem = {}
def forward(self, x):
self.mem['x'] = x
return np.where(x > 0, x, np.zeros_like(x))
def backward(self, grad_y):
'''
grad_y: same shape as x
'''
# ==========
# todo '''请完成激活函数的梯度后传'''
# ==========
x = self.mem['x']
return (x > 0).astype(np.float32) * grad_y
def compute_loss(self, log_prob, labels):
'''
log_prob is the predicted probabilities
labels is the ground truth
Please return the loss
'''
# ==========
# todo '''请完成多分类问题的损失计算 损失为: 交叉熵损失 + L2正则项'''
# ==========
loss = np.sum(np.sum(-log_prob * labels, axis=1)) + self.lambda1 * (np.sum(self.W1 ** 2) + np.sum(self.W2 ** 2)) * 0.5
return loss
def forward(self, x):
'''
x is the input features
Please return the predicted probabilities of x
'''
# ==========
# todo '''请搭建一个MLP前馈神经网络 补全它的前向传播 MLP结构为FFN --> RELU --> FFN --> Softmax'''
# ==========
x = x.reshape(x.shape[0], -1)
bias = np.ones(shape=[x.shape[0], 1])
x = np.concatenate([x, bias], axis=1) # (batch_size, num_inputs+1)
self.h1 = self.mul_h1.forward(self.W1, x.T)
self.h1_relu = self.relu.forward(self.h1)
self.h2 = self.mul_h2.forward(self.W2, self.h1_relu)
self.h2_soft = self.softmax.forward(self.h2.T)
self.h2_log = self.log.forward(self.h2_soft)
return self.h2_log
def backward(self, label):
'''
label is the ground truth
Please compute the gradients of self.W1 and self.W2
'''
# ==========
# todo '''补全该前馈神经网络的后向传播算法'''
# ==========
self.h2_log_grad = self.log.backward(-label)
self.h2_soft_grad = self.softmax.backward(self.h2_log_grad)
self.h2_grad, self.W2_grad = self.mul_h2.backward(self.h2_soft_grad.T)
self.h1_relu_grad = self.relu.backward(self.h2_grad)
self.h1_grad, self.W1_grad = self.mul_h1.backward(self.h1_relu_grad)
def update(self):
'''
Please update self.W1 and self.W2
'''
# ==========
# todo '''更新该前馈神经网络的参数'''
# ==========
self.W1 -= self.lr * (self.W1_grad + self.lambda1 * self.W1)
self.W2 -= self.lr * (self.W2_grad + self.lambda1 * self.W2)
扣分点:foward最后没有经过log.forward层
def forward(self, x):
# 第一个全连接层
# 检查输入特征 x 的形状
# 将输入特征扁平化为一维向量
x_flattened = np.reshape(x, (x.shape[0], -1))
# 添加偏置项并检查形状
x_with_bias = np.concatenate((x_flattened, np.ones((x_flattened.shape[0], 1))), axis=1)
# 进行矩阵乘法操作
h1 = self.mul_h1.forward(self.W1, np.transpose(x_with_bias))
h1_relu = self.relu.forward(h1)
# 第二个全连接层
h2 = self.mul_h2.forward(self.W2, h1_relu)
probs = self.softmax.forward(h2.T)
# 将输出的形状转置为 (60000, 10)
self.probs = probs
return probs
扣分点:backward label不是-label
def backward(self, label):
grad_y = self.log.backward(label)
grad_y = self.softmax.backward(grad_y)
grad_y, grad_W2 = self.mul_h2.backward(grad_y.T)
grad_y = self.relu.backward(grad_y)
_, grad_W1 = self.mul_h1.backward(grad_y)
self.grad_W1 = grad_W1
self.grad_W2 = grad_W2
扣分点:更新部分写到了forward
def backward(self, label):
grad_log = self.log.backward(label)
grad_softmax = self.softmax.backward(grad_log)
grad_layer2, grad_W2 = self.mul_h2.backward(grad_softmax.T)
grad_relu = self.relu.backward(grad_layer2)
grad_layer1, grad_W1 = self.mul_h1.backward(grad_relu)
self.W1 += self.lr * grad_W1
self.W2 += self.lr * grad_W2
# ===========
def update(self):
'''
PLease update self.W1 and self.W2
'''
# ===========
# todo '''更新该前馈神经网络的参数'''
扣分点:更新里面有backward
def update(self):
'''
PLease update self.W1 and self.W2
'''
# ===========
# todo '''更新该前馈神经网络的参数'''
# ===========
grad_W1, grad_W2 = self.backward(label) # Assuming label is defined elsewhere
self.W1 -= self.lr * grad_W1
self.W2 -= self.lr * grad_W2
lab5¶
未放出标准答案
但是实验课有提到nn.Unfold以后不能再使用了(确实有点投机取巧哈哈)
另外一套可行的代码:
import torch
from torch import nn
def corr2d(X, K):
'''
X --> (B, I, H, W) where B = batch size, I = in_channel, H = height of feature map, W = width of feature map
K --> (O, I, h, w) where O = out_channel, I = in_channel, h = height of kernel, w = width of kernel
你需要实现一个Stride为1,Padding为0的窄卷积操作
Y的大小应为(B, O, H-h+1, W-w+1)
'''
# =============
# todo: 请根据以上提示补全代码
# =============
B, I, H, W = X.shape
O, _, h, w = K.shape
X = X.unsqueeze(1)
K = K.unsqueeze(0)
Y = torch.zeros((B, O, H-h+1, W-w+1))
# print(X[:, :, :, 1:1+h, 1:1+w].shape, K.shape)
# print(torch.sum(X[:, :, :, 1:1+h, 1:1+w] * K, (3,4)).shape)
for i in range(H-h+1):
for j in range(W-w+1):
Y[:, :, i, j] = torch.sum(X[:, :, :, i:i+h, j:j+w] * K, (2, 3,4))
return Y
class Conv2D(nn.Module):
def __init__(self, out_channels, in_channels, kernel_size):
super(Conv2D, self).__init__()
self.weight = nn.Parameter(torch.randn((out_channels, in_channels, kernel_size[0], kernel_size[1])))
self.bias = nn.Parameter(torch.randn((out_channels)))
def forward(self, X):
'''
X --> (B, I, H, W) where B = batch size, I = in_channel, H = height of feature map, W = width of feature map
你需要利用以上初始化的参数weight和bias实现一个卷积层的前向传播
Y should have size (B, O, H-h+1, W-w+1)
'''
# =============
# todo: 请根据以上提示补全代码
# =============
Y = corr2d(X, self.weight) + self.bias.view(1, self.weight.shape[0], 1, 1)
return Y
class MaxPool2D(nn.Module):
def __init__(self, pool_size):
super(MaxPool2D, self).__init__()
self.pool_size = pool_size
def forward(self, X):
'''
X --> (B, I, H, W) where B = batch size, I = in_channel, H = height of feature map, W = width of feature map
K --> (h, w) where h = height of kernel, w = width of kernel
你需要利用以上pool_size实现一个最大汇聚层的前向传播,汇聚层的子区域间无覆盖
Y的大小应为(B, I, H/h, W/w)
'''
# =============
# todo: 请根据以上提示补全代码
# =============
B, I, H, W = X.shape
h, w = self.pool_size[0], self.pool_size[1]
Y = torch.zeros((B, I,H//h, W//w))
for i in range(H//h):
for j in range(W//w):
Y[:, :, i, j] = torch.amax(X[:, :, i*h:(i+1)*h, j*w:(j+1)*w], (2, 3))
return Y
class ImageCNN(nn.Module):
def __init__(self, input_size, num_outputs, in_channels, out_channels, conv_kernel, pool_kernel):
super(ImageCNN, self).__init__()
self.conv1 = nn.Sequential(
Conv2D(out_channels, in_channels, conv_kernel),
nn.ReLU()
)
self.pool1 = MaxPool2D(pool_kernel)
self.linear = nn.Linear(16 * 5 * 5, num_outputs)
def forward(self, feature_map):
b = feature_map.size()[0]
feature_map = self.conv1(feature_map)
feature_map = self.pool1(feature_map)
outputs = self.linear(feature_map.reshape(b, -1))
return outputs
lab7¶
未放出标准答案
VAE/GAN实现代码(她只说看一下就好)
import torch
from torchvision import transforms
import matplotlib.pyplot as plt
from torch import nn
import numpy as np
from VAE import VAE
import GAN
import gzip
torch.manual_seed(2024)
class MNISTDataset():
def __init__(self, data_path, train=True, transform=None):
X, y = self.load_data(data_path, train)
self.X = X
self.y = y
self.transform = transform
def __getitem__(self, index):
img = self.X[index]
if self.transform is not None:
img = self.transform(img)
if self.y is None:
return img
else:
return img, int(self.y[index])
def __len__(self):
return len(self.X)
def load_data(self, data_path, train):
y_train = None
if train:
with gzip.open(data_path + '-labels.gz', 'rb') as f:
y_train = np.frombuffer(f.read(), np.uint8, offset=8)
with gzip.open(data_path + '-images.gz', 'rb') as f:
x_train = np.frombuffer(f.read(), np.uint8, offset=16).reshape(-1, 28, 28)
return x_train, y_train
def load_mnist():
train_set = MNISTDataset(r'./data/train', train=True,
transform = transforms.Compose([
transforms.ToTensor(), #,transforms.Normalize([0.5], [0.5])
]))
return train_set
def deprocess_img(x):
# rescale image from [-1, 1] to [0, 1]
return (x + 1.0) / 2.0
def loss_function(reconstruction_function, recon_x, x, mu, logvar):
#print(recon_x[:3, :3], x[:3, :3])
BCE = reconstruction_function(recon_x, x)
KLD = -0.5 * torch.sum(1 + 2*logvar - torch.exp(2*logvar) - mu**2)
return BCE + KLD
def train_with_VAE(train_set):
#print(test_set[0]); exit()
_, height, width = train_set[0][0].shape
train_dataloader = torch.utils.data.DataLoader(train_set, batch_size=64, shuffle=True)
model = VAE(width*height, 50, 10)
optimizer = torch.optim.SGD(model.parameters(), lr=1e-5)
loss_func = nn.BCELoss(reduction = 'sum')
recons = []
num_epochs = 40
for epoch in range(1, num_epochs + 1):
train_l_sum, train_acc_sum, n = 0., 0., 0
for i, Xy in enumerate(train_dataloader):
#if i> 100: continue
X, y = Xy
X = X.squeeze(1).view(-1, width * height)
recon_batch, mu, logvar = model(X)
loss = loss_function(loss_func, recon_batch, X, mu, logvar)
# 梯度清零
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_l_sum += loss.item()
n += y.shape[0]
if epoch % 10 == 0:
print('epoch %d, loss %.4f' % (epoch, train_l_sum / n))
recon_batch = recon_batch.view(-1, height, width).detach().numpy()
recon, row_recon = [], []
for i in range(len(recon_batch)):
recon += [recon_batch[i, :, :]]
if (i + 1) % 8 == 0:
row_recon += [np.concatenate(recon, 1)]
recon = []
row_recon = np.concatenate(row_recon, 0)
# print('row_recon', row_recon.shape); exit()
fig = plt.figure()
plt.imshow(row_recon, cmap='gray', interpolation='none')
plt.title("Generated Images")
plt.xticks([])
plt.yticks([])
plt.show()
def discriminator_loss(loss_fn, logits_real, logits_fake):
size = logits_real.shape[0]
true_labels = torch.ones(size, 1).float()
false_labels = torch.zeros(size, 1).float()
loss = loss_fn(logits_real, true_labels) + loss_fn(logits_fake, false_labels)
return loss
def generator_loss(loss_fn, logits_fake):
size = logits_fake.shape[0]
true_labels = torch.ones(size, 1).float()
loss = loss_fn(logits_fake, true_labels)
return loss
def train_with_GAN(train_set):
#print(test_set[0]); exit()
noise_dim = 96
_, height, width = train_set[0][0].shape
train_dataloader = torch.utils.data.DataLoader(train_set, batch_size=64, shuffle=True)
discriminator = GAN.Discriminator(width*height, 256, 256)
generator = GAN.Generator(noise_dim, 1024, width*height)
dis_optimizer = torch.optim.Adam(discriminator.parameters(), lr=5e-4, betas=(0.5, 0.999))
gen_optimizer = torch.optim.Adam(generator.parameters(), lr=5e-4, betas=(0.5, 0.999))
dis_loss_func = nn.BCELoss(reduction = 'sum')
gen_loss_func = nn.BCELoss(reduction = 'sum')
recons = []
num_epochs = 5
for epoch in range(1, num_epochs + 1):
train_d_sum, train_g_sum, n = 0., 0., 0
for i, Xy in enumerate(train_dataloader):
#if i> 100: continue
X, y = Xy
batch_size = X.size(0)
X = X.squeeze(1).view(-1, width * height)
# 训练判别网络
logits_real = discriminator(X)
rand_noise = (torch.rand(batch_size, noise_dim) - 0.5)/0.5
fake_images = generator(rand_noise)
logits_fake = discriminator(fake_images)
d_error = discriminator_loss(dis_loss_func, logits_real, logits_fake)
dis_optimizer.zero_grad()
d_error.backward()
dis_optimizer.step()
# 训练生成网络
rand_noise = (torch.rand(batch_size, noise_dim) - 0.5)/0.5
fake_images = generator(rand_noise)
gen_logits_fake = discriminator(fake_images)
g_error = generator_loss(gen_loss_func, gen_logits_fake)
gen_optimizer.zero_grad()
g_error.backward()
gen_optimizer.step()
train_d_sum += d_error.item()
train_g_sum += g_error.item()
n += y.shape[0]
print('epoch %d, discriminator loss %.4f, generator loss %.4f' % (epoch, train_d_sum/n, train_g_sum/n))
recon_batch = fake_images.view(-1, height, width).detach().numpy()
recon_batch = deprocess_img(recon_batch)
recon, row_recon = [], []
for i in range(len(recon_batch)):
recon += [recon_batch[i, :, :]]
if (i + 1) % 8 == 0:
row_recon += [np.concatenate(recon, 1)]
recon = []
row_recon = np.concatenate(row_recon, 0)
fig = plt.figure()
plt.imshow(row_recon, cmap='gray', interpolation='none')
plt.title("Generated Images")
plt.xticks([])
plt.yticks([])
plt.show()
if __name__ == '__main__':
train_set = load_mnist()
train_with_VAE(train_set)
train_with_GAN(train_set)
import torch
from torch import nn
from torch.autograd import Variable
import torch.nn.functional as F
class VAE(nn.Module):
def __init__(self, input_feature, h1, h2):
super(VAE, self).__init__()
'''
The inference network has structure:
h1 = ReLU(W1 x + b1)
mu = W2 h1 + b2
log sigma = W3 h1 + b3
The generation network has structure:
h1 = ReLU(W1 z + b1)
x_{hat} = sigmoid(W2 h1 + b2)
'''
self.fc1 = nn.Linear(input_feature, h1)
self.fc21 = nn.Linear(h1, h2)
self.fc22 = nn.Linear(h1, h2)
self.fc3 = nn.Linear(h2, h1)
self.fc4 = nn.Linear(h1, input_feature)
def encode(self, x):
h1 = F.relu(self.fc1(x))
return self.fc21(h1), self.fc22(h1)
def reparameterize(self, mu, logvar):
'''
Sampling z via reparameterize:
z = mu + sigma * epsilon
'''
std = 0.5 * torch.exp(logvar)
z = torch.randn(std.size()) * std + mu
return z
def decode(self, z):
h3 = F.relu(self.fc3(z))
return torch.sigmoid(self.fc4(h3))
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparameterize(mu, logvar)
return self.decode(z), mu, logvar
class Discriminator(nn.Module):
def __init__(self, input_feature, h1, h2):
super(Discriminator, self).__init__()
'''
The discriminator has structure:
h1 = LeakyReLU(W1 x + b1)
h2 = LeakyReLU(W2 h1 + b2)
h3 = sigmoid(W3 h2 + b3)
'''
self.fc1 = nn.Linear(input_feature, h1)
self.act1 = nn.LeakyReLU(0.2)
self.fc2 = nn.Linear(h1, h2)
self.act2 = nn.LeakyReLU(0.2)
self.fc3 = nn.Linear(h2, 1)
def forward(self, x):
x = self.act1(self.fc1(x))
x = self.act2(self.fc2(x))
x = torch.sigmoid(self.fc3(x))
return x
class Generator(nn.Module):
def __init__(self, noise_dim, h1, h2):
super(Generator, self).__init__()
'''
The generator has structure:
h1 = ReLU(W1 z + b1)
h2 = ReLU(W2 h1 + b2)
x_{hat} = tanh(W3 h2 + b3)
'''
self.fc1 = nn.Linear(noise_dim, h1)
self.fc2 = nn.Linear(h1, h1)
self.fc3 = nn.Linear(h1, h2)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = torch.tanh(self.fc3(x))
return x
lab9¶
标准答案1
def decode(self, dec_y, enc_hidden, state, is_train=True):
dec_embs = self.emb_layer(dec_y) # 进行词嵌入
trg_len = dec_y.shape[1] # 获取了目标序列的长度
outputs = []
state = state.transpose(1, 0)
for t in range(trg_len):
scores = torch.bmm(state, enc_hidden.transpose(2, 1)) # 计算解码器当前时间步的注意力分数
alpha = self.softmax(scores) # 转换为注意力权重(batch_size, 1, seq_len)
cont_vec = torch.bmm(alpha, enc_hidden).squeeze(1) # 根据注意力权重,计算当前时间步的上下文向量
input_vec = torch.cat([cont_vec, dec_embs[:, t, :]], 1).unsqueeze(1) # 将上下文向量和解码器输入序列的词嵌入向量拼接在一起
sent_hidden, state = self.decoder(input_vec, state.transpose(0, 1)) # 将当前时间步的输入向量输入到解码器中
state = state.transpose(0, 1) # 再次转置解码器的状态,以恢复原始的维度顺序。
pred = self.linear(sent_hidden) # 输出预测字符
outputs += [pred]
sent_outputs = torch.cat(outputs, dim=1) # 将所有时间步的预测结果连接起来,形成最终的输出序列
return sent_outputs, state
标准答案2
def encode(self, enc_x, state):
enc_emb = self.emb_layer(enc_x)
enc_hidden, state = self.encoder(enc_emb, state)
# 对编码器的隐藏状态 enc_hidden
# 应用一个多层感知机(MLP),然后进行平均池化操作
state = self.mlp(enc_hidden).mean(1).unsqueeze(0)
return enc_hidden, state
def decode(self, dec_y, enc_hidden, state, is_train=True):
dec_embs = self.emb_layer(dec_y) # 进行词嵌入
trg_len = dec_y.shape[1] # 获取解码器输入序列的长度
outputs = []
state = state.transpose(1, 0)
for t in range(trg_len):
scores = torch.bmm(state, enc_hidden.transpose(2, 1))
alpha = self.softmax(scores) # (batch_size, 1, seq_len)
cont_vec = torch.bmm(alpha, enc_hidden).squeeze(1)
input_vec = torch.cat([cont_vec, dec_embs[:, t, :]], 1).unsqueeze(1)
sent_hidden, state = self.decoder(input_vec, state.transpose(0, 1))
state = state.transpose(0, 1)
# 输出预测字符
pred = self.linear(sent_hidden)
outputs += [pred]
sent_outputs = torch.cat(outputs, dim=1)
return sent_outputs, state
失分点:
(1)注意力机制计算错误
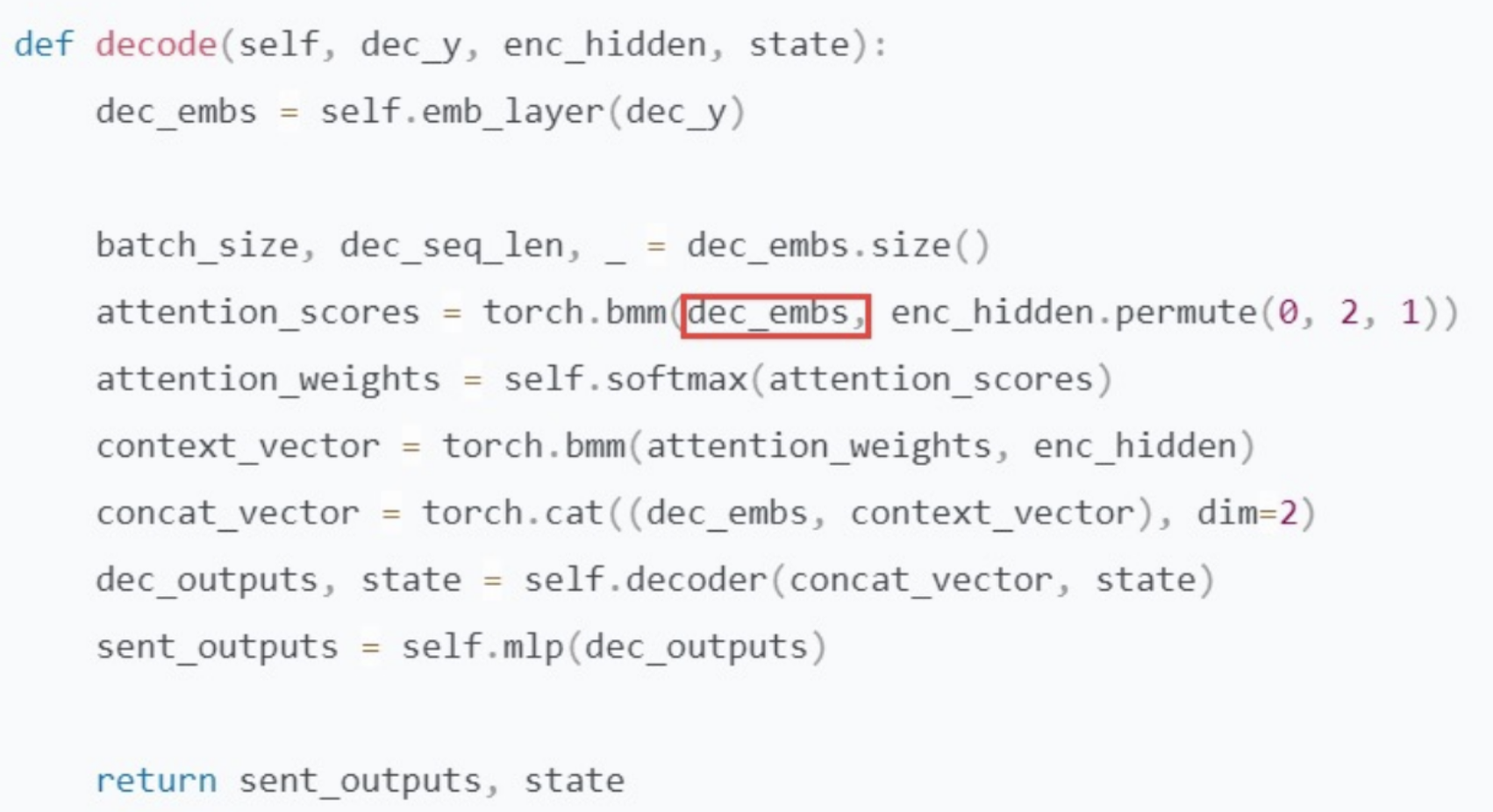
(2)注意力权重计算错误

(3)没有计算注意力
