2024春实验内容和我的完成情况¶
我的平时实验是满分,基本上没问题(当然也没去卷那个榜单)
这里的作业是老师要求完成(计算分数)的实验,其他的不在此罗列了
lab2¶
实现一元线性回归模型,用小批量随机梯度下降法进行优化
实验要求¶
用小批量随机梯度下降法优化一元线性回归模型使训练集上的损失函数接近全局最小值
不能修改项目内部给定的代码,不能import其他工具包,只能在“to do”下面书写代码
def train(self, x, y, k = 8):
'''
x and y are the data for traning a linear regression
k is the batch size
please simply update the value of self.w and not include any other parameters
'''
# ==========
# todo '''使用小批量随机梯度下降法优化对self.w进行更新'''
# ==========
提交之后,测试集上的损失值应该降到一个正确的范围内
完整代码¶
import numpy as np
import random
import os
def load_data(filename):
"""载入数据。"""
xys = []
with open(filename, 'r') as f:
for line in f:
xys.append(map(float, line.strip().split()))
if 'train' in filename:
xs, ys = zip(*xys)
return np.asarray(xs), np.asarray(ys)
else:
xs = [list(x)[0] for x in xys]
return np.asarray(xs), None
class LinearRegression(object):
def __init__(self):
super(LinearRegression, self).__init__()
'''
self.w --> (2, ) is the parameter of a linear regression
self.lr is the learning rate of training
self.epoch is the iteration time of training
'''
self.w = 0.05 * np.random.randn(2)
self.lr = 0.00001
self.epoch = 1000
def predict(self, x):
beta0 = np.expand_dims(np.ones_like(x), axis=1)
beta1 = np.expand_dims(x, axis=1)
x = np.concatenate([beta1, beta0], axis=1)
y = np.dot(x, self.w)
return y
def train(self, x, y, k = 8):
'''
x and y are the data for traning a linear regression
k is the batch size
please simply update the value of self.w and not include any other parameters
'''
# 先用SGD写一下,再改成小批量的
# ==========
# todo '''使用小批量随机梯度下降法优化对self.w进行更新'''
beta0 = np.expand_dims(np.ones_like(x), axis=1)
beta1 = np.expand_dims(x, axis=1)
x_con = np.concatenate([beta1, beta0], axis=1)
y_predict = np.dot(x_con, self.w)
for i in range(0,self.epoch):
tmp = np.arange(len(x))
np.random.shuffle(tmp)
for j in range(0, len(x), k):
batch_indices = tmp[j]
theta=x[batch_indices]
loss=2 * (y_predict[batch_indices] - y[batch_indices])
theta=theta*self.lr*loss
l=loss*self.lr
self.w -= [theta,l]
y_predict = np.dot(x_con, self.w)
# ==========
def evaluate(ys, ys_pred):
"""评估模型。"""
std = np.sqrt(np.mean(np.abs(ys - ys_pred) ** 2))
return std
def zip_fun():
path=os.getcwd()
newpath=path+"/output/"
os.chdir(newpath)
os.system('zip predict.zip predict.npy')
os.chdir(path)
if __name__ == '__main__':
train_file = './input/train.txt'
test_file = './input/test_X.txt'
# 载入数据
x_train, y_train = load_data(train_file)
x_test, _ = load_data(test_file)
# 使用线性回归训练模型,返回一个函数f()使得y = f(x)
f = LinearRegression()
f.train(x_train, y_train)
y_train_pred = f.predict(x_train)
std = evaluate(y_train, y_train_pred)
print('The std on training data via SGD is :{:f}'.format(std))
preds = f.predict(x_test)
np.save('./output/predict', preds)
zip_fun()
The std on training data via SGD is :2.052850
lab3¶
熟悉pytorch的自动求导流程
实现softmax线性分类模型
实验要求¶
完成softmax函数并利用梯度下降法优化softmax线性分类模型
不能修改项目内部给定的代码,不能import其他工具包,只能在“to do”下面书写代码
def softmax(X):
'''
X is the input
Please compute its softmax outputs
'''
# ===============
# todo: 不调用torch的softmax,手写softmax函数,并返回
# ===============
def manual_backward(self, X, y, y_hat):
'''
X is the input feature;
y is the ground truth label;
y_hat is the predicted label.
Please update self.linear.weight and self.linear.bias
'''
with torch.no_grad():
# ==============
# todo: 将automatic_update设为False,不调用torch的自动更新,手动完成梯度下降法优化'''
# ===============
提交之后,测试集上的损失值应该降到一个正确的范围内
完整代码¶
import matplotlib.pyplot as plt
from matplotlib import animation, rc
from IPython.display import HTML
import sys
import os
import torch
from torch import nn
from torch.utils.data import DataLoader
import numpy as np
np.random.seed(2022)
torch.manual_seed(2022)
def softmax(X):
'''
X is the input
Please compute its softmax outputs
'''
# ===============
# todo: 不调用torch的softmax,手写softmax函数,并返回
# 首先通过减去每行的最大值来防止指数爆炸
# 然后计算每行的指数值,最后将每个指数值除以该行所有指数值的总和
exp_values = torch.exp(X - torch.max(X, dim=1, keepdim=True)[0])
return exp_values / torch.sum(exp_values, dim=1, keepdim=True)
# ===============
class SoftmaxRegression(nn.Module):
def __init__(self, num_inputs, num_outputs):
super(SoftmaxRegression, self).__init__()
self.linear = nn.Linear(num_inputs, num_outputs, dtype=torch.float64)
nn.init.normal_(self.linear.weight, mean=0, std=0.01) # 初始化权重:均值为0,标准差为0.01的正态分布
nn.init.constant_(self.linear.bias, val=0) # 初始化偏置:常数0
self.lr = 0.01 # 学习率
self.num_classes = num_outputs # 输出类别的数量
def forward(self, x):
y = self.linear(x.view(x.shape[0], -1)) # 线性变换
y = softmax(y) # 进行softmax操作
return y
def manual_backward(self, X, y, y_hat):
'''
X is the input feature;
y is the ground truth label;
y_hat is the predicted label.
Please update self.linear.weight and self.linear.bias
'''
lr = self.lr
N = X.shape[0]
y1 = torch.zeros(N, self.num_classes)
y1.scatter_(1, y.unsqueeze(1).long(), 1)
y2 = softmax(y_hat)
with torch.no_grad():
# ==============
# todo: 将automatic_update设为False,不调用torch的自动更新,手动完成梯度下降法优化'''
distance = y2 - y1
dw = distance.T @ X / N
db = torch.sum(y_hat - y1, dim=0)
self.linear.weight -= self.lr * dw
self.linear.bias -= self.lr * db
# ===============
def evaluate_accuracy(data_iter, net):
acc_sum, n = 0.0, 0
for X, y in data_iter:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n
def train_model(train_set, automatic_update=False):
train_dataloader = DataLoader(train_set, batch_size=64, shuffle=True) # 加载数据
model = SoftmaxRegression(2, 3) # softmax回归模型
optimizer = torch.optim.SGD(model.parameters(), lr=0.1) # 随机梯度下降(SGD)优化器
loss_func = nn.CrossEntropyLoss() # 交叉熵损失函数
num_epochs = 20
animation_fram = []
for epoch in range(1, num_epochs + 1):
train_l_sum, train_acc_sum, n = 0., 0., 0
for Xy in train_dataloader:
Xy = Xy.squeeze(1)
X, y = Xy[:, :-1], Xy[:, -1]
y_hat = model(X).squeeze(1) # 模型预测
loss = loss_func(y_hat, y.long()).sum() # 计算损失
if automatic_update: # 是否使用自动更新梯度
optimizer.zero_grad()
loss.backward()
optimizer.step()
else:
model.manual_backward(X, y, y_hat) # 手动反向传播和梯度更新
train_l_sum += loss.item() # 训练损失总和
train_acc_sum += (y_hat.argmax(dim=1) == y).float().sum().item() # 训练准确率总和
n += y.shape[0] # 样本数量
# 模型的权重、偏置和损失值
animation_fram.append((model.linear.weight.detach().numpy()[0, 0], \
model.linear.weight.detach().numpy()[0, 1], \
model.linear.bias.detach().numpy(), loss.detach().numpy()))
print('epoch %d, loss %.4f, train acc %.3f'
% (epoch + 1, train_l_sum / n, train_acc_sum / n))
# test_acc = evaluate_accuracy(test_iter, model)
# print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f'
# % (epoch + 1, train_l_sum / n, train_acc_sum / n, test_acc))
return model
def load_data(filename):
"""载入数据。"""
xys = []
with open(filename, 'r') as f:
for line in f:
xys.append(line.strip().split())
if 'train' in filename:
C1 = [list(map(float, x)) for x in xys if float(list(x)[2]) == 0]
C2 = [list(map(float, x)) for x in xys if float(list(x)[2]) == 1]
C3 = [list(map(float, x)) for x in xys if float(list(x)[2]) == 2]
return torch.tensor(C1, dtype=torch.float64), torch.tensor(C2, dtype=torch.float64), torch.tensor(C3, dtype=torch.float64)
else:
xs = [list(map(float, x)) for x in xys]
return torch.tensor(xs, dtype=torch.float64), None
def zip_fun():
path=os.getcwd()
newpath=path+"/output/"
os.chdir(newpath)
os.system('zip predict.zip predict.npy')
os.chdir(path)
if __name__ == '__main__':
train_file = './input/train.txt'
test_file = './input/test_X.txt'
# load data
C1, C2, C3 = load_data(train_file)
C, _ = load_data(test_file)
train_set = np.concatenate((C1, C2, C3), axis=0)
test_dataloader = DataLoader(C, batch_size=10000, shuffle=False)
# train model using data set and output animation frame
my_model = train_model(train_set)
test_set = next(iter(test_dataloader)).squeeze(1)
Z = my_model(test_set).detach().numpy()
preds = np.argmax(Z, axis=1)
np.save('./output/predict.npy', preds)
# generate animation
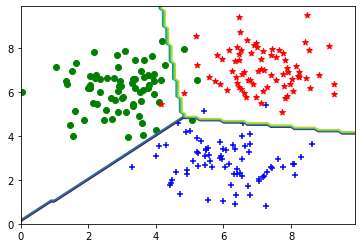
plt.scatter(np.array(C1[:, 0]), np.array(C1[:, 1]), c='b', marker='+')
plt.scatter(np.array(C2[:, 0]), np.array(C2[:, 1]), c='g', marker='o')
plt.scatter(np.array(C3[:, 0]), np.array(C3[:, 1]), c='r', marker='*')
x = np.arange(0., 10., 0.1)
y = np.arange(0., 10., 0.1)
X, Y = np.meshgrid(x, y)
inp = np.array(list(zip(X.reshape(-1), Y.reshape(-1))), dtype=np.float64)
#print(inp[:100])
dataloader = DataLoader(inp, batch_size=10000, shuffle=False)
inp = next(iter(dataloader))
Z = my_model(inp).detach().numpy()
Z = np.argmax(Z, axis=1)
Z = Z.reshape(X.shape)
print(Z.shape)
plt.contour(X, Y, Z)
plt.show()
zip_fun()
epoch 2, loss 0.0196, train acc 0.338
epoch 3, loss 0.0191, train acc 0.622
epoch 4, loss 0.0186, train acc 0.568
epoch 5, loss 0.0182, train acc 0.622
epoch 6, loss 0.0178, train acc 0.752
epoch 7, loss 0.0173, train acc 0.878
epoch 8, loss 0.0170, train acc 0.928
epoch 9, loss 0.0165, train acc 0.937
epoch 10, loss 0.0163, train acc 0.901
epoch 11, loss 0.0159, train acc 0.950
epoch 12, loss 0.0156, train acc 0.950
epoch 13, loss 0.0153, train acc 0.964
epoch 14, loss 0.0150, train acc 0.964
epoch 15, loss 0.0147, train acc 0.968
epoch 16, loss 0.0145, train acc 0.964
epoch 17, loss 0.0143, train acc 0.973
epoch 18, loss 0.0141, train acc 0.959
epoch 19, loss 0.0139, train acc 0.955
epoch 20, loss 0.0137, train acc 0.968
epoch 21, loss 0.0136, train acc 0.968
lab4¶
1.理解图像识别的代码实现流程
2.补全MLP模型
3.比较numpy版本和pytorch版本的MLP模型实现
实验要求¶
• 读懂exercise_mlp.py文件中的代码,熟悉图像识别任务的代码流程,可通过display_mnist看到数据库的图像
• 理解pytorch版本的MLP代码实现
• 用numpy实现基于MLP模型的图像分类任务
• 完成ReLU激活函数的梯度后传
• 利用设定好的对象属性补全MLP前向传播,后向传播和参数更新
• 不能修改给定的对象属性,不能调用其他工具包, 只能在“to do”下面书写代码
• 提交之后,测试集上的准确率应该降到一个正确的范围内可多次提交。
即使对自己的代码没有自信也一定要提交,我们会酌情给过程分
完整代码¶
feedforward_pytorch_version.py
import torch
from torch import nn
class FlattenLayer(torch.nn.Module):
def __init__(self):
super(FlattenLayer, self).__init__()
def forward(self, x): # x shape: (batch, *, *, ...)
return x.view(x.shape[0], -1)
class Model_Pytorch(torch.nn.Module):
def __init__(self, num_inputs, num_outputs, num_hiddens = 100):
super(Model_Pytorch, self).__init__()
self.net = nn.Sequential(
FlattenLayer(),
nn.Linear(num_inputs, num_hiddens),
nn.ReLU(),
nn.Linear(num_hiddens, num_outputs),
)
self.activate_func = nn.Softmax(dim=1)
print('model with pytorch ...')
def forward(self, X):
z = self.net(X)
y = self.activate_func(z)
return y
if __name__ == '__main__':
model = Model_Pytorch()
feedforward_np_version.py
import numpy as np
class Matmul:
def __init__(self):
self.mem = {}
def forward(self, W, x):
h = np.matmul(W, x)
self.mem = {'x': x, 'W': W}
return h
def backward(self, grad_y):
'''
x: shape(d, N)
w: shape(d', d)
grad_y: shape(d', N)
'''
x = self.mem['x']
W = self.mem['W']
grad_x = np.matmul(W.T, grad_y)
grad_W = np.matmul(grad_y, x.T)
return grad_x, grad_W
class Relu:
def __init__(self):
self.mem = {}
def forward(self, x):
self.mem['x'] = x
return np.where(x > 0, x, np.zeros_like(x))
def backward(self, grad_y):
'''
grad_y: same shape as x
'''
# ==========
# todo '''请完成激活函数的梯度后传'''
# ==========
x = self.mem['x']
return (x > 0).astype(np.float32) * grad_y
class Softmax:
'''
softmax over last dimention
'''
def __init__(self):
self.epsilon = 1.e-8
self.mem = {}
def forward(self, x):
'''
x: shape(N, c)
'''
x_exp = np.exp(x)
partition = np.sum(x_exp, axis=1, keepdims=True)
out = x_exp / (partition + self.epsilon)
#print(x_exp[:3, :3], out[:3, :3])
self.mem['out'] = out
self.mem['x_exp'] = x_exp
return out
def backward(self, grad_y):
'''
grad_y: same shape as x
'''
s = self.mem['out']
sisj = np.matmul(np.expand_dims(s, axis=2), np.expand_dims(s, axis=1)) # (N, c, c)
g_y_exp = np.expand_dims(grad_y, axis=1)
tmp = np.matmul(g_y_exp, sisj) # (N, 1, c)
tmp = np.squeeze(tmp, axis=1)
tmp = -tmp + grad_y * s
return tmp
class Log:
'''
softmax over last dimention
'''
def __init__(self):
self.epsilon = 1e-12
self.mem = {}
def forward(self, x):
'''
x: shape(N, c)
'''
out = np.log(x + self.epsilon)
self.mem['x'] = x
return out
def backward(self, grad_y):
'''
grad_y: same shape as x
'''
x = self.mem['x']
return 1. / (x + 1e-12) * grad_y
class Model_NP:
def __init__(self, num_inputs, num_outputs, num_hiddens = 100, lr = 5.e-5, lambda1 = 0.01):
self.W1 = np.random.normal(size=[num_hiddens, num_inputs + 1])
self.W2 = np.random.normal(size=[num_outputs, num_hiddens])
self.mul_h1 = Matmul()
self.mul_h2 = Matmul()
self.relu = Relu()
self.softmax = Softmax()
self.log = Log()
self.lr = lr
self.lambda1 = lambda1
print('model with numpy ...')
def compute_loss(self, log_prob, labels):
'''
log_prob is the predicted probabilities
labels is the ground truth
Please return the loss
'''
# ==========
# todo '''请完成多分类问题的损失计算 损失为: 交叉熵损失 + L2正则项'''
# ==========
# 交叉熵损失
N = log_prob.shape[0]
loss1 = np.mean(np.sum(-labels * log_prob, axis=1)) #-np.sum(labels * log_prob) / N
# L2正则项
loss2 = self.lambda1 * (np.sum(self.W1 ** 2) + np.sum(self.W2 ** 2)) * 0.5
return loss1 + loss2
def forward(self, x):
'''
x is the input features
Please return the predicted probabilities of x
'''
# ==========
# todo '''请搭建一个MLP前馈神经网络 补全它的前向传播 MLP结构为FFN --> RELU --> FFN --> Softmax'''
# ==========
x = x.reshape(x.shape[0], x.shape[1]*x.shape[2])
bias = np.ones(shape=[x.shape[0], 1])
x = np.concatenate([x, bias], axis=1)
self.h1 = self.mul_h1.forward(self.W1, x.T)
self.h1_relu = self.relu.forward(self.h1)
self.h2 = self.mul_h2.forward(self.W2, self.h1_relu)
self.h2_soft = self.softmax.forward(self.h2.T)
self.h2_log = self.log.forward(self.h2_soft)
return self.h2_log
def backward(self, label):
'''
label is the ground truth
Please compute the gradients of self.W1 and self.W2
'''
# ==========
# todo '''补全该前馈神经网络的后向传播算法'''
# ==========
N = label.shape[0]
self.h2_log_grad = self.log.backward(-label)
self.h2_soft_grad = self.softmax.backward(self.h2_log_grad)
self.h2_grad, self.W2_grad = self.mul_h2.backward(self.h2_soft_grad.T)
self.h1_relu_grad = self.relu.backward(self.h2_grad)
self.h1_grad, self.W1_grad = self.mul_h1.backward(self.h1_relu_grad)
self.W2_grad += self.lambda1 * self.W2
self.W1_grad += self.lambda1 * self.W1
def update(self):
'''
Please update self.W1 and self.W2
'''
# ==========
# todo '''更新该前馈神经网络的参数'''
# ==========
self.W2 -= self.lr * self.W2_grad
self.W1 -= self.lr * self.W1_grad
if __name__ == '__main__':
model = Model_NP()
lab5¶
- 补全cnn_hard_version.py 文件中的CNN模型
- 在cnn_easy_version.py尝试不同结构的CNN模型,调整参数,看看不同CNN模型在图像分类任务上的效果
实验要求¶
• 你需要做的:根据提示,补全CNN代码
• 利用设定好的输入完成卷积函数(准确的说互相关函数)和汇聚层的前向传播
• 不能修改给定的对象属性,不能调用其他工具包, 只能在“to do”下面书写代码
• 提交之后,测试集上的准确率应该降到一个正确的范围内并且cnn_hard_version.py文件是可执行的
• 可多次提交。即使对自己的代码没有自信也一定要提交,我们会酌情给过程分
• 禁用pytorch自带函数convXd, einsum和as_strided.
• TO DO: 完成《Convolutional Neural Network》项目。补全cnn_hard_version.py文件使exercise_cnn.py文件中的train_with_CNN_hard()可以顺利执行。
• 如果你有额外时间:尝试不同的CNN模型
• 读懂exercise_cnn.py文件中的代码,熟悉图像识别任务的代码流程,可通过display_cifar看到数据集的图像
• 理解通过pytorch版本实现的CNN模型(cnn_easy_version.py中的CNN实现代码),并尝试修改CNN的参数(如:kernel size, out channel, stride, zero padding size等)或者框架(如:修改卷积块的个数,激活函数等)看看其对模型训练的影响
• 如果对pytorch的函数不熟悉,可以搜索pytorch的documentation
• Note:你们可能会发现自己实现的CNN会比pytorch内置的CNN慢很多,这是因为pytorch包含一些优化的计算策略,因此我们建议大家在cnn_easy_version.py文件中尝试不同的CNN模型,可以更快的训练模型
完整代码¶
cnn_easy_version.py¶
import torch
from torch import nn
import copy
import torch.nn.functional as F
# 其实这是一个仿MobileNet的结构
class MobileBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(MobileBlock, self).__init__()
self.net = nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=in_channels, kernel_size=3, stride=stride, padding=1, groups=in_channels, bias=False),
nn.BatchNorm2d(in_channels),
nn.ReLU6(),
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU6()
)
def forward(self, x):
return self.net(x)
class ImageCNN(nn.Module):
def __init__(self, num_outputs, in_channels, out_channels, conv_kernel, pool_kernel):
super(ImageCNN, self).__init__()
'''
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels, out_channels, conv_kernel),
nn.ReLU()
)
self.conv2 = nn.Sequential(
nn.Conv2d(out_channels, out_channels, pool_kernel),
nn.ReLU()
)
self.linear = nn.Linear(16*6*6, num_outputs)
'''
self.net = nn.Sequential(
nn.Conv2d(in_channels = in_channels, out_channels = 32, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(32),
nn.ReLU6(),
MobileBlock(32, 64, 1),
MobileBlock(64, 128, 2),
MobileBlock(128, 128, 1),
MobileBlock(128, 256, 2),
MobileBlock(256, 256, 1),
MobileBlock(256, 512, 2),
MobileBlock(512, 512, 1),
MobileBlock(512, 512, 1),
MobileBlock(512, 512, 1),
MobileBlock(512, 512, 1),
MobileBlock(512, 512, 1),
MobileBlock(512, 1024, 2),
MobileBlock(1024, 1024, 1),
nn.AdaptiveAvgPool2d(1),
nn.Flatten(),
nn.Linear(in_features=1024, out_features=num_outputs)
)
def forward(self, sent):
'''
#sent_emb = self.embeddings(sent)
sent_emb = sent
b = sent_emb.size()[0]
sent_hidden = self.conv1(sent_emb)
# sent_hidden = F.max_pool2d(sent_hidden, (sent_hidden.size(2), sent_hidden.size(3))).squeeze()
sent_hidden = F.max_pool2d(sent_hidden, (2, 2))
sent_hidden = self.conv2(sent_hidden)
sent_hidden = F.max_pool2d(sent_hidden, (2, 2))
#print(sent_hidden.size())
logits = self.linear(sent_hidden.reshape(b, -1))
return logits
'''
return self.net(sent)
if __name__ == '__main__':
model = Model_NP()
cnn_hard_version.py¶
import torch
from torch import nn
def corr2d(X, K):
'''
X --> (B, I, H, W) where B = batch size, I = in_channel, H = height of feature map, W = width of feature map
K --> (O, I, h, w) where O = out_channel, I = in_channel, h = height of kernel, w = width of kernel
你需要实现一个Stride为1,Padding为0的窄卷积操作
Y的大小应为(B, O, H-h+1, W-w+1)
'''
# =============
# todo: 请根据以上提示补全代码
'''
本来是这样去写的,但是准确率非常低,我怀疑自己哪里写错了,但是检查了一下发现自己的思路并没有很大的问题。
B, IX, H, W = X.shape
O, IK, h, w = K.shape
Y = torch.zeros((B, O, H-h+1, W-w+1))
X = X.unsqueeze(1) # [B, 1, I, H, W]
K = K.unsqueeze(0) # [1, O, I, h, w]
for i in range(H-h+1):
for j in range(W-w+1):
Y[:, :, i, j] = torch.sum(X[:, :, :, i:i+h, j:j+w] * K, dim=(2, 3, 4))
'''
# 后来我在网上看到有人是这样理解的:conv = unfold + matmul + fold
# 利用这些函数,我看看能不能优化一下。
# 参考:https://blog.csdn.net/zouxiaolv/article/details/125899737
B, IX, H, W = X.shape
O, IK, h, w = K.shape
unfold = nn.Unfold(kernel_size=(h, w), stride=1)
input_vector = unfold(X)
kernel_vector = K.reshape(K.shape[0], -1).T
Y = (input_vector.permute(0, 2, 1).contiguous() @ kernel_vector)
Y = Y.reshape(B, H - h + 1, W - w + 1, O).permute(0, 3, 1, 2).contiguous()
# =============
return Y
class Conv2D(nn.Module):
def __init__(self, out_channels, in_channels, kernel_size):
super(Conv2D, self).__init__()
self.weight = nn.Parameter(torch.randn((out_channels, in_channels, kernel_size[0], kernel_size[1])))
self.bias = nn.Parameter(torch.randn((out_channels)))
def forward(self, X):
'''
X --> (B, I, H, W) where B = batch size, I = in_channel, H = height of feature map, W = width of feature map
你需要利用以上初始化的参数weight和bias实现一个卷积层的前向传播
Y should have size (B, O, H-h+1, W-w+1)
'''
# =============
# todo: 请根据以上提示补全代码
Y = corr2d(X, self.weight) + self.bias.view(1, -1, 1, 1)
# =============
return Y
class MaxPool2D(nn.Module):
def __init__(self, pool_size):
super(MaxPool2D, self).__init__()
self.pool_size = pool_size
def forward(self, X):
'''
X --> (B, I, H, W) where B = batch size, I = in_channel, H = height of feature map, W = width of feature map
K --> (h, w) where h = height of kernel, w = width of kernel
你需要利用以上pool_size实现一个最大汇聚层的前向传播,汇聚层的子区域间无覆盖
Y的大小应为(B, I, H/h, W/w)
'''
# =============
# todo: 请根据以上提示补全代码
B, I, H, W = X.shape
h, w = self.pool_size[0], self.pool_size[1]
# 输出张量的大小
out_H = H // h
out_W = W // h
Y = torch.zeros((B, I, out_H, out_W))
for i in range(out_H):
ih = i*h
ih1 = ih+h
for j in range(out_W):
Y[:, :, i, j] = torch.max(X[:, :, ih:ih1, j*w:(j+1)*w].flatten(-2, -1), dim=-1)[0]
#torch.amax(X[:, :, ih:ih1, j*w:(j+1)*w], dim=(2, 3))
# =============
return Y
class ImageCNN(nn.Module):
def __init__(self, input_size, num_outputs, in_channels, out_channels, conv_kernel, pool_kernel):
super(ImageCNN, self).__init__()
self.conv1 = nn.Sequential(
Conv2D(out_channels, in_channels, conv_kernel),
nn.ReLU()
)
self.pool1 = MaxPool2D(pool_kernel)
self.linear = nn.Linear(16*5*5, num_outputs)
def forward(self, feature_map):
b = feature_map.size()[0]
feature_map = self.conv1(feature_map)
feature_map = self.pool1(feature_map)
outputs = self.linear(feature_map.reshape(b, -1))
return outputs
exercise_cnn.py¶
import torch
from torchvision import transforms
import matplotlib.pyplot as plt
from torch import nn
import numpy as np
from cnn_hard_version import ImageCNN
from cnn_easy_version import ImageCNN as ImageCNN_easy
import pickle
import os
# os.environ['CUDA_VISIBLE_DEVICES'] = '4'
class CIFAR10Dataset():
def __init__(self, data_path, train=True, transform=None):
X, y = self.load_data(data_path, train)
self.X = X
self.y = y
self.transform = transform
def __getitem__(self, index):
img = self.X[index]
if self.transform is not None:
img = self.transform(img)
if self.y is None:
return img
else:
return img, int(self.y[index])
def __len__(self):
return len(self.X)
def load_data(self, data_path, train):
y_train = None
if train:
with open(data_path + '_labels', 'rb') as f:
y_train = np.asarray(pickle.load(f)).reshape(-1)
with open(data_path + '_images', 'rb') as f:
x_train = np.asarray(pickle.load(f)).reshape(-1, 3, 32*32)
return x_train, y_train
def display_cifar():
data_train = CIFAR10Dataset('./input/train', train=True)
fig = plt.figure()
index = np.arange(len(data_train))
np.random.shuffle(index)
index2label = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
for i in range(6):
plt.subplot(2, 3, i + 1)
plt.tight_layout()
plt.imshow(np.transpose(data_train[index[i]][0].reshape(3, 32, 32), (1, 2, 0)), interpolation='none')
plt.title("Ground Truth: {}".format(index2label[data_train[index[i]][1]]))
plt.xticks([])
plt.yticks([])
plt.show()
def load_cifar10():
train_set = CIFAR10Dataset('./input/train', train=True,
transform = transforms.Compose([
transforms.ToTensor()
]))
test_set = CIFAR10Dataset('./input/test', train=False,
transform = transforms.Compose([
transforms.ToTensor()
]))
return train_set, test_set
def train_with_CNN_hard(train_set, test_set):
train_dataloader = torch.utils.data.DataLoader(train_set, batch_size=64, shuffle=True)
model = ImageCNN((32, 32) , 10, 3, 16, (8, 8), (5, 5))
# gpu环境下
# model = model.cuda()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
loss_func = nn.CrossEntropyLoss()
num_epochs = 80
for epoch in range(1, num_epochs + 1):
train_l_sum, train_acc_sum, n = 0., 0., 0
for i, Xy in enumerate(train_dataloader):
#if i> 10:continue
X, y = Xy
# gpu环境下
# X = X.cuda()
# y = y.cuda()
X = X.reshape(-1, 3, 32, 32)
y_hat = model(X).squeeze(1)
loss = loss_func(y_hat, y.long()).sum()
# print('epoch:',epoch,' iteros:',i,' loss:',loss)
# 梯度清零
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_l_sum += loss.item()
train_acc_sum += (y_hat.argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
print('epoch %d, loss %.4f, train acc %.3f'
% (epoch, train_l_sum / n, train_acc_sum / n))
X = torch.stack(list(test_set), 0)
X = X.reshape(-1, 3, 32, 32)
# gpu环境下
# X = X.cuda()
y_hat = model(X)
y_hat = y_hat[:, :].argmax(dim=1).numpy()
# gpu环境下
# y_hat = y_hat[:, :].argmax(dim=1).cpu().numpy() # 将结果从 GPU 移动到 CPU,然后转换为 NumPy 数组
pred_txt = [str(w) for w in y_hat]
g = open('./output/predict.txt', 'w')
g.write('\n'.join(pred_txt))
g.close()
print('./output/predict.txt successfully saved')
def train_with_CNN_easy(train_set, test_set):
train_dataloader = torch.utils.data.DataLoader(train_set, batch_size=64, shuffle=True)
model = ImageCNN_easy(10, 3, 16, (5, 5), (3, 3))
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
loss_func = nn.CrossEntropyLoss()
num_epochs = 100
for epoch in range(1, num_epochs + 1):
train_l_sum, train_acc_sum, n = 0., 0., 0
for i, Xy in enumerate(train_dataloader):
#if i> 10:continue
X, y = Xy
X = X.reshape(-1, 3, 32, 32)
y_hat = model(X).squeeze(1)
loss = loss_func(y_hat, y.long()).sum()
# 梯度清零
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_l_sum += loss.item()
train_acc_sum += (y_hat.argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
print('epoch %d, loss %.4f, train acc %.3f'
% (epoch, train_l_sum / n, train_acc_sum / n))
def zip_fun():
path=os.getcwd()
newpath=path+"/output/"
os.chdir(newpath)
os.system('zip prediction.zip predict.txt')
os.chdir(path)
if __name__ == '__main__':
train_set, test_set = load_cifar10()
display_cifar()
train_with_CNN_hard(train_set, test_set)
zip_fun()
#train_with_CNN_easy(train_set, test_set)
#zip_fun()
lab7¶
1.熟悉文本生成任务的流程
2.补全rnn_hard_version.py 文件中的基于GRU的歌词预测模型
实验要求¶
• 根据提示,补全基于GRU的歌词预测模型代码
• 利用设定好的输入完成GRU的前向传播和歌词预测模型主体
• 正确定义和初始化GRU中的参数
• 不能调用其他工具包,不能调用pytorch内置的GRU模块,只能在“to do”下面书写代码
• 提交之后,测试集上的准确率应该降到一个正确的范围内可多次提交。即使对自己的代码没有自信也一定要提交,我们会酌情给过程分
• TO DO: 完成《Recurrent Neural Network》项目。补全rnn_hard_version.py文件使exercise_rnn.py文件中的train_with_RNN_hard()可以顺利执行。
Note:为了测试方便,这里我们使用准确率作为我们的生成评估标准。实际生成任务一般采用BLEU,Rouge等
完整代码¶
rnn_easy_version.py¶
import torch
from torch import nn
class Sequence_Modeling(nn.Module):
def __init__(self, vocab_size, embedding_size, num_outputs, hidden_size):
super(Sequence_Modeling, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embedding_size)
self.step = nn.GRU(embedding_size, hidden_size, batch_first=True)
self.linear = nn.Linear(hidden_size, num_outputs)
def forward(self, sent, state):
sent_emb = self.embeddings(sent)
steps = sent.size(1)
sent_hidden, state = self.step(sent_emb, state)
sent_states = self.linear(sent_hidden)
return sent_states, state
rnn_hard_version.py¶
import torch
from torch import nn
import numpy as np
np.random.seed(2022)
torch.manual_seed(2022)
class GRU(nn.Module):
def __init__(self, num_inputs, num_hiddens):
super(GRU, self).__init__()
# 隐藏层参数
self.W_xz = torch.nn.Parameter(torch.tensor(np.random.normal(0, 0.01, size=(num_inputs, num_hiddens)), dtype=torch.float32))
self.W_hz = torch.nn.Parameter(torch.tensor(np.random.normal(0, 0.01, size=(num_hiddens, num_hiddens)), dtype=torch.float32))
self.b_z = torch.nn.Parameter(torch.zeros(num_hiddens))
self.W_xr = torch.nn.Parameter(torch.tensor(np.random.normal(0, 0.01, size=(num_inputs, num_hiddens)), dtype=torch.float32))
self.W_hr = torch.nn.Parameter(torch.tensor(np.random.normal(0, 0.01, size=(num_hiddens, num_hiddens)), dtype=torch.float32))
self.b_r = torch.nn.Parameter(torch.zeros(num_hiddens))
self.W_xh = torch.nn.Parameter(torch.tensor(np.random.normal(0, 0.01, size=(num_inputs, num_hiddens)), dtype=torch.float32))
self.W_hh = torch.nn.Parameter(torch.tensor(np.random.normal(0, 0.01, size=(num_hiddens, num_hiddens)), dtype=torch.float32))
self.b_h = torch.nn.Parameter(torch.zeros(num_hiddens))
def forward(self, inputs, H):
'''
补全GRU的前向传播,
不能调用pytorch中内置的GRU函数及操作
'''
# ==========
# todo '''请补全GRU网络前向传播'''
hidden_size = self.b_z.shape[0]
num_inputs_size, num_hiddens_size = self.W_xz.shape
B, S, _ = inputs.shape
outputs = torch.zeros(B, S, num_hiddens_size)
for i in range(S):
r_t = torch.sigmoid(
torch.matmul(inputs[:, i], self.W_xr) + torch.matmul(H, self.W_hr) + self.b_r.unsqueeze(0))
z_t = torch.sigmoid(
torch.matmul(inputs[:, i], self.W_xz) + torch.matmul(H, self.W_hz) + self.b_z.unsqueeze(0))
h_t_hat = torch.tanh(
torch.matmul(inputs[:, i], self.W_xh) + torch.matmul(r_t * H, self.W_hh) + self.b_h.unsqueeze(0))
H = z_t * H + (1 - z_t) * h_t_hat
outputs[:, i] = H
# ==========
return outputs, H
class Sequence_Modeling(nn.Module):
def __init__(self, vocab_size, embedding_size, num_outputs, hidden_size):
super(Sequence_Modeling, self).__init__()
self.emb_layer = nn.Embedding(vocab_size, embedding_size)
self.gru_layer = GRU(embedding_size, hidden_size)
self.linear = nn.Linear(hidden_size, num_outputs)
def forward(self, sent, state):
'''
sent --> (B, S) where B = batch size, S = sequence length
sent_emb --> (B, S, I) where B = batch size, S = sequence length, I = num_inputs
state --> (1, B, H), where B = batch_size, num_hiddens
你需要利用定义好的emb_layer, gru_layer和linear,
补全代码实现歌词预测功能,
sent_outputs的大小应为(B, S, O) where O = num_outputs, state的大小应为(1, B, H)
'''
# ==========
# todo '''请补全代码'''
# ==========
sent_emb = self.emb_layer(sent)
sent_hidden, state = self.gru_layer(sent_emb, state)
sent_outputs = self.linear(sent_hidden)
return sent_outputs, state
if __name__ == '__main__':
model = Sequence_Modeling()
测试代码¶
import torch
from torch import nn
import math
from rnn_hard_version import Sequence_Modeling
from rnn_easy_version import Sequence_Modeling as Sequence_Modeling_pytorch
import pickle
import os
torch.manual_seed(2022)
def load_jaychou_lyrics():
with open('input/jaychou_train.txt', encoding='GBK') as f:
train_chars = f.readlines()
train_chars = (''.join(train_chars)).replace('\n', ' ').replace('\r', ' ')
with open('input/jaychou_test_X.txt', encoding='GBK') as f:
test_chars = f.readlines()
test_chars = [sent.replace('\n', '') for sent in test_chars]
return train_chars, test_chars
def text_processing(train_chars, test_chars, num_steps):
word2idx, idx2word = {'PAD': 0, 'UNK': 1}, {0: 'PAD', 1: 'UNK'}
train_ids, train_labels, test_ids, test_labels = [], [], [], []
for w in train_chars:
if w not in word2idx:
word2idx[w] = len(word2idx)
idx2word[word2idx[w]] = w
train_id = word2idx[w] if w in word2idx else word2idx['UNK']
train_ids += [train_id]
for sent in test_chars:
if len(sent) != num_steps: print(sent); print(len(sent)); exit()
test_id = [word2idx[w] if w in word2idx else word2idx['UNK'] for w in sent]
test_ids += [test_id]
return train_ids, test_ids, word2idx, idx2word
def data_iter_consecutive(corpus_indices, batch_size, num_steps):
corpus_indices = torch.tensor(corpus_indices, dtype=torch.float32)
data_len = len(corpus_indices)
batch_len = data_len // batch_size
indices = corpus_indices[0: batch_size*batch_len].view(batch_size, batch_len)
epoch_size = (batch_len - 1) // num_steps
for i in range(epoch_size):
i = i * num_steps
X = indices[:, i: i + num_steps]
Y = indices[:, i + 1: i + num_steps + 1]
yield torch.tensor(X, dtype=torch.int), torch.tensor(Y, dtype=torch.int)
def predict_rnn_pytorch(prefix, num_chars, model, state, idx_to_char, char_to_idx):
output = [char_to_idx[prefix[0]]]
for t in range(num_chars + len(prefix) - 1):
X = torch.tensor([output[-1]]).view(1, 1)
Y, state = model(X, state)
if t < len(prefix) - 1:
output.append(char_to_idx[prefix[t + 1]])
else:
output.append(int(Y.squeeze(1).argmax(dim=1).item()))
return ''.join([idx_to_char[i] for i in output])
def init_rnn_state(batch_size, num_hiddens):
return torch.zeros((1, batch_size, num_hiddens))
def train_with_RNN_hard(train_chars, test_chars):
batch_size, num_hiddens, num_steps = 64, 256, 35
train_ids, test_ids, word2idx, idx2word = text_processing(train_chars, test_chars, num_steps)
model = Sequence_Modeling(len(word2idx), 300, len(word2idx), num_hiddens)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
loss_func = nn.CrossEntropyLoss()
num_epochs = 30
for epoch in range(1, num_epochs + 1):
state = init_rnn_state(batch_size, num_hiddens)
train_dataloader = data_iter_consecutive(train_ids, batch_size, num_steps)
train_l_sum, train_acc_sum, n = 0., 0., 0
for i, Xy in enumerate(train_dataloader):
state.detach_()
X, y = Xy
y_hat, state = model(X, state)
y_hat = y_hat.view(y_hat.size(0)*y_hat.size(1), -1)
y = y.view(-1)
loss = loss_func(y_hat, y.long()).sum()
# 梯度清零
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_l_sum += loss.item() * y.size(0)
train_acc_sum += (y_hat.argmax(dim=1) == y).float().sum().item()
n += y.size(0)
print('epoch %d, perplexity %.4f, train acc %.3f'
% (epoch, math.exp(train_l_sum / n), train_acc_sum / n))
if epoch % 5 == 0:
pred_len, prefixes = 50, ['分开', '不分开']
state = init_rnn_state(1, num_hiddens)
for prefix in prefixes:
print(' -', predict_rnn_pytorch(
prefix, pred_len, model, state, idx2word, word2idx))
pred_txt = []
for i in range(500, len(test_ids)+500, 500):
X = torch.tensor(test_ids[i-500:i], dtype=torch.int)
state = init_rnn_state(X.size(0), num_hiddens)
y_hat, _ = model(X, state)
y_hat = y_hat[:, -1, :].argmax(dim=1).numpy()
pred_txt_temp = [idx2word[w] for w in y_hat]
pred_txt += pred_txt_temp
g = open('output/predict.txt', 'w')
g.write('\n'.join(pred_txt))
g.close()
def train_with_RNN_easy(train_chars, test_chars):
batch_size, num_hiddens, num_steps = 64, 256, 35
train_ids, test_ids, word2idx, idx2word = text_processing(train_chars, test_chars, num_steps)
model = Sequence_Modeling_pytorch(len(word2idx), 300, len(word2idx), num_hiddens)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
loss_func = nn.CrossEntropyLoss()
num_epochs = 60
for epoch in range(1, num_epochs + 1):
state = init_rnn_state(batch_size, num_hiddens)
train_dataloader = data_iter_consecutive(train_ids, batch_size, num_steps)
train_l_sum, train_acc_sum, n = 0., 0., 0
for i, Xy in enumerate(train_dataloader):
state.detach_()
X, y = Xy
y_hat, state = model(X, state)
y_hat = y_hat.view(y_hat.size(0)*y_hat.size(1), -1)
y = y.view(-1)
loss = loss_func(y_hat, y.long()).sum()
# 梯度清零
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_l_sum += loss.item() * y.size(0)
train_acc_sum += (y_hat.argmax(dim=1) == y).float().sum().item()
n += y.size(0)
print('epoch %d, perplexity %.4f, train acc %.3f'
% (epoch, math.exp(train_l_sum / n), train_acc_sum / n))
if epoch % 20 == 0:
pred_len, prefixes = 50, ['分开', '不分开']
state = init_rnn_state(1, num_hiddens)
for prefix in prefixes:
print(' -', predict_rnn_pytorch(
prefix, pred_len, model, state, idx2word, word2idx))
def zip_fun():
path=os.getcwd()
newpath=path+"/output/"
os.chdir(newpath)
os.system('zip prediction.zip predict.txt')
os.chdir(path)
if __name__ == '__main__':
train_chars, test_chars = load_jaychou_lyrics()
train_with_RNN_hard(train_chars, test_chars)
zip_fun()
train_with_RNN_easy(train_chars, test_chars)
C:\Users\tom\AppData\Local\Temp\ipykernel_10328\1763869187.py:11: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
yield torch.tensor(X, dtype=torch.int), torch.tensor(Y, dtype=torch.int)
epoch 1, perplexity 318.8472, train acc 0.163
epoch 2, perplexity 51.4136, train acc 0.298
epoch 3, perplexity 16.0361, train acc 0.446
epoch 4, perplexity 7.1232, train acc 0.590
epoch 5, perplexity 4.0854, train acc 0.700
- 分开身体 还能不能 重新编织 脑海中起毛球的记忆 再慢慢变成永 不用麻烦了 不用麻烦了 不用麻烦了 不用
- 不分开 合 你的完美主义 太
epoch 6, perplexity 2.8310, train acc 0.776
epoch 7, perplexity 2.2186, train acc 0.829
epoch 8, perplexity 1.8413, train acc 0.870
epoch 9, perplexity 1.6031, train acc 0.900
epoch 10, perplexity 1.4532, train acc 0.922
- 分开 有话说不出来 分手说不出来 分手说不出来 分手说不出来 分手说不出来 分手说不出来 分手
- 不分开 合 转身离开 分手说不出来 分手说不出来 分手说不出来 分手说不出来 分手说不出来
epoch 11, perplexity 1.3492, train acc 0.938
epoch 12, perplexity 1.2749, train acc 0.950
epoch 13, perplexity 1.2268, train acc 0.960
epoch 14, perplexity 1.1892, train acc 0.966
epoch 15, perplexity 1.1566, train acc 0.971
- 分开 离开你以后 并没有更自由 酸酸的空气 嗅出我们的距离 一幕锥心的结局 像呼吸般无法停息 抽屉泛黄的
- 不分开 合 我的感觉 你已听不见 你的转变 像断掉的弦 再怎么接 音都不对 你的改变我能够分辨 在我地
epoch 16, perplexity 1.1391, train acc 0.974
epoch 17, perplexity 1.1209, train acc 0.977
epoch 18, perplexity 1.1031, train acc 0.980
epoch 19, perplexity 1.0924, train acc 0.982
...
epoch 59, perplexity 1.0952, train acc 0.983
epoch 60, perplexity 1.0844, train acc 0.984
- 分开 这样也好不起 有个啥用 鼓励你多久我去哪有时间 两行人们在痛痛 在我地盘这 你就得听我的 把音
- 不分开 你 靠着我的肩膀 你 在我胸口睡著 像这样的生活 我爱你 你爱我 你不想太快 我就是不是
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
lab9¶
1.熟悉用编码器-解码器的框架解决序列逆置任务的流程
2.补全rnn_with_atten.py文件中的融合注意力机制的RNN模型
实验要求¶
• 根据提示,补全融合注意力机制的解码器代码,实现序列逆置任务
• 利用设定好的输入完成要求的RNN with attention模型
• 所有预设的网络层都应当用到
• 不能修改给定的对象属性,不能调用其他工具包,只能在“to do”下面书写代码
• 提交之后,测试集上的准确率应该提升到一个正确的范围内
• 可多次提交。即使对自己的代码没有自信也一定要提交,我们会酌情给过程分
• 本次Lab在截止日期之前将不公开榜单
• TO DO: 完成《Attention Mechanism》项目。补全rnn_with_atten.py文件使exercise_reverse_sequence.py文件中的train_with_RNN()可以顺利执行。
• 输入一个序列要求模型输出序列的逆置
• 如:输入“ABCDEFG”, 输出“GFEDCBA”
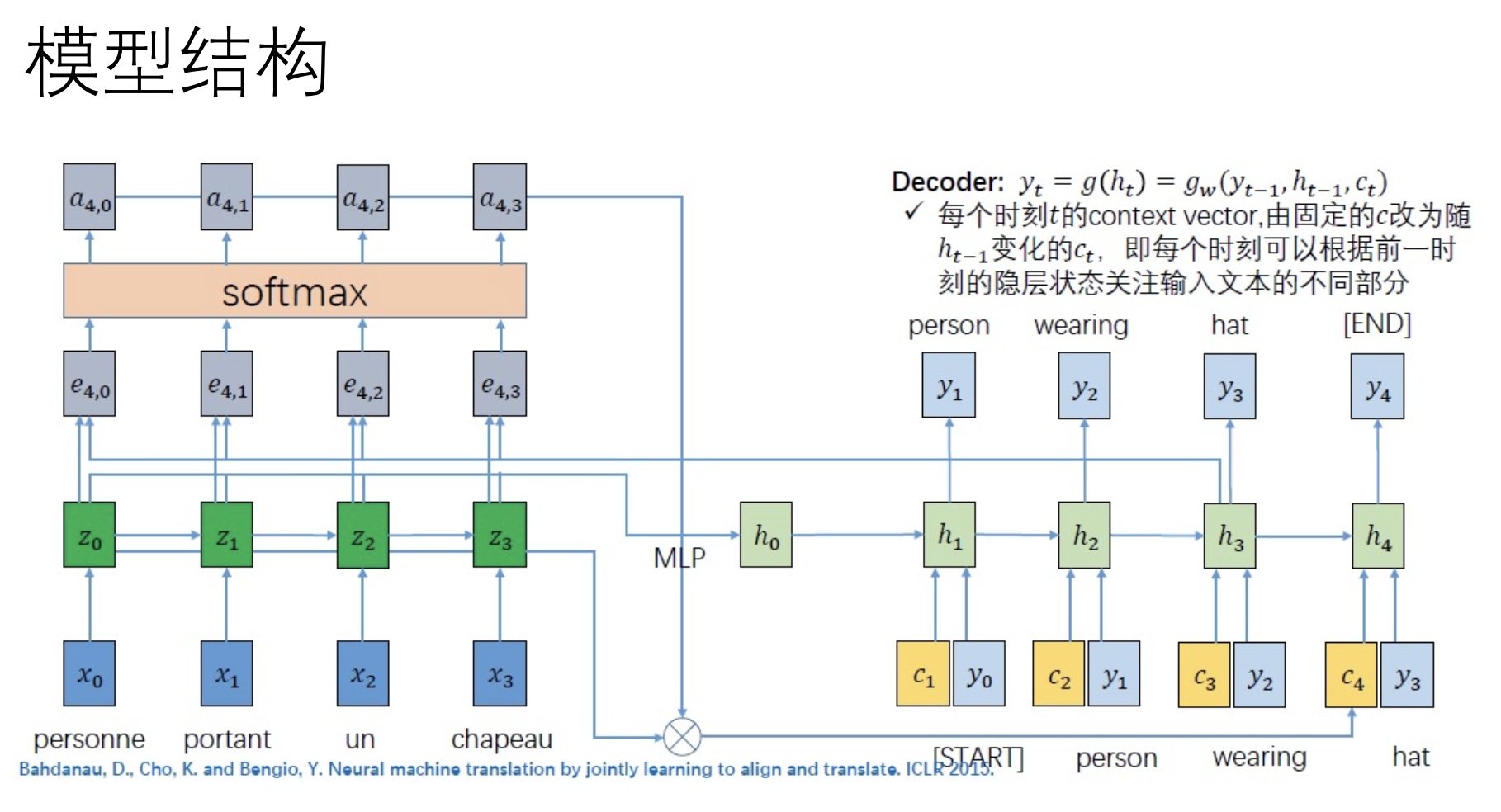
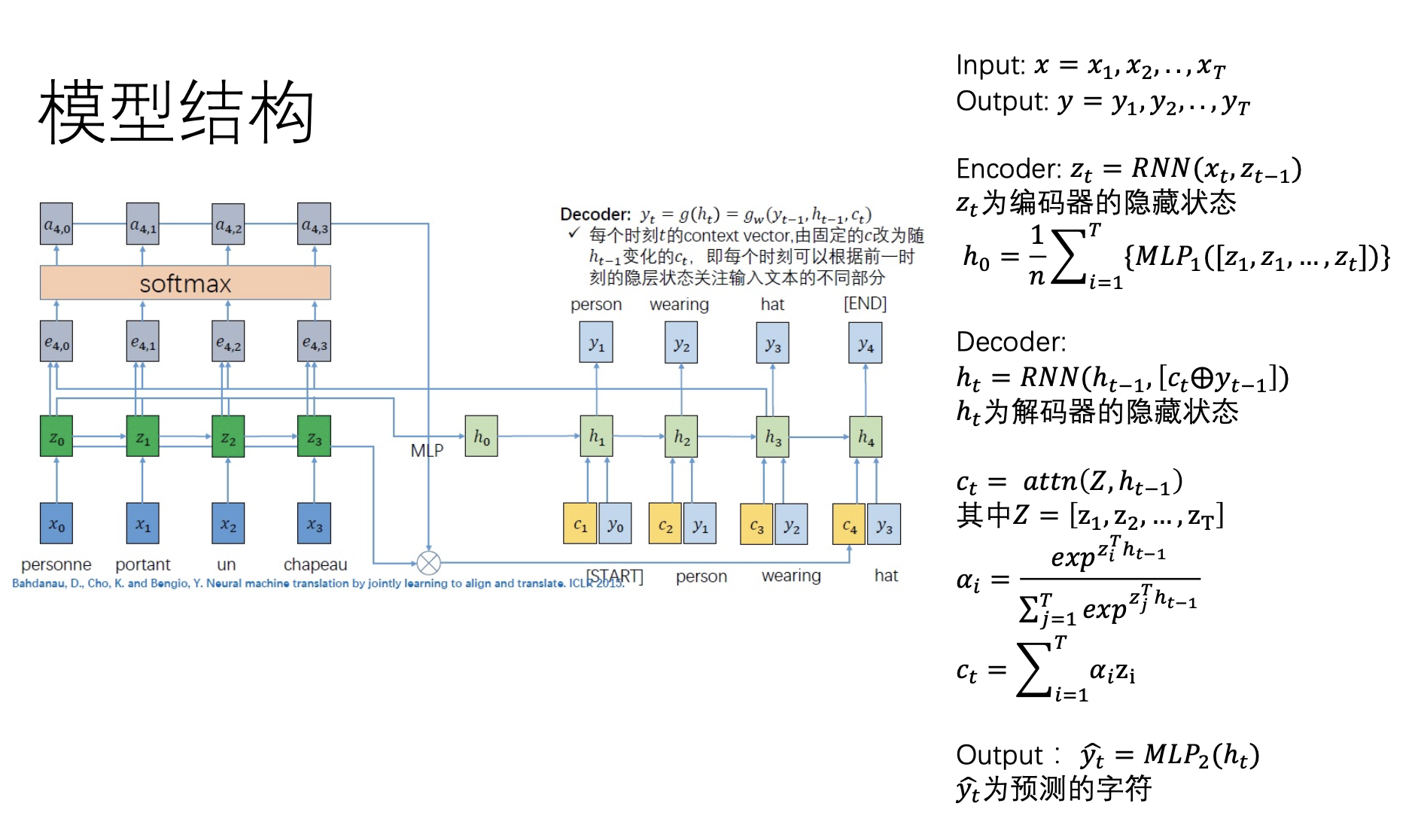
助教后来的更正:

完整代码¶
exercise_reverse_sequence.py
import torch
from torch import nn
import math
import string
import random
from rnn_with_atten_new import Sequence_Modeling
random.seed(2023)
def generate_random_string(string_length):
"""Generate a random string"""
letters = string.ascii_uppercase
return ''.join(random.choice(letters) for i in range(string_length))
def get_string_batch(batch_size, length):
batched_examples = [generate_random_string(length) for _ in range(batch_size)]
enc_x = [[ord(ch)-ord('A')+1 for ch in list(exp)] for exp in batched_examples]
y = [[o for o in reversed(e_idx)] for e_idx in enc_x]
dec_x = [[0]+e_idx[:-1] for e_idx in y]
return (torch.tensor(enc_x, dtype=torch.int32), \
torch.tensor(dec_x, dtype=torch.int32), \
torch.tensor(y, dtype=torch.int32))
def get_test_batch(test_set):
enc_x = [[ord(ch)-ord('A')+1 for ch in list(exp)] for exp in test_set]
return torch.tensor(enc_x, dtype=torch.int32).view(1, -1)
def predict_rnn_pytorch(enc_x, model, state):
output = [0]
enc_hidden, state = model.encode(enc_x, state)
for t in range(len(enc_x[0])):
enc_y = torch.tensor([output[-1]]).view(1, 1)
Y, state = model.decode(enc_y, enc_hidden, state)
output.append(int(Y.squeeze(1).argmax(dim=1).item()))
output = ''.join([chr(i+64) for i in output[1:]])
return output
def init_rnn_state(batch_size, num_hiddens):
return torch.zeros((1, batch_size, num_hiddens))
def load_file(file_path):
with open(file_path) as f:
test_set = f.readlines()
test_set = [line.strip() for line in test_set]
return test_set
def train_with_RNN(test_set):
batch_size, num_hiddens = 64, 100
word_num = ord('Z')-ord('A')+2
model = Sequence_Modeling(word_num, 100, word_num, num_hiddens)
optimizer = torch.optim.SGD(model.parameters(), lr=0.05)
loss_func = nn.CrossEntropyLoss()
num_epochs = 10000
for epoch in range(1, num_epochs + 1):
state = init_rnn_state(batch_size, num_hiddens)
enc_x, enc_y, y = get_string_batch(64, 8)
train_l_sum, train_acc_sum, n = 0., 0., 0
# print(X.shape, y.shape, state[0].shape)
enc_hidden, state = model.encode(enc_x, state)
y_hat, _ = model.decode(enc_y, enc_hidden, state)
# print(y_hat.size(), y.size())
y_hat = y_hat.view(y_hat.size(0)*y_hat.size(1), -1)
y = y.view(-1)
loss = loss_func(y_hat, y.long()).sum()
# 梯度清零
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_l_sum += loss.item() * y.size(0)
train_acc_sum += (y_hat.argmax(dim=1) == y).float().sum().item()
n += y.size(0)
if epoch % 500 == 0:
print('epoch %d, perplexity %.4f, train acc %.3f'
% (epoch, math.exp(train_l_sum / n), train_acc_sum / n))
pred_txt = []
for X in test_set:
enc_x = get_test_batch(X)
state = init_rnn_state(1, num_hiddens)
y_hat = predict_rnn_pytorch(enc_x, model, state)
pred_txt += [y_hat]
g = open('data/predict.txt', 'w')
g.write('\n'.join(pred_txt))
g.close()
import os
def zip_fun():
path=os.getcwd()
newpath=path+"/output/"
os.chdir(newpath)
os.system('zip prediction.zip predict.txt')
os.chdir(path)
if __name__ == '__main__':
#print('toy_string', toy_string)
test_set = load_file('data/test_X.txt')
train_with_RNN(test_set)
zip_fun()
rnn_with_atten_new.py
import torch
from torch import nn
class Sequence_Modeling(nn.Module):
def __init__(self, vocab_size, embedding_size, num_outputs, hidden_size):
super(Sequence_Modeling, self).__init__()
self.emb_layer = nn.Embedding(vocab_size, embedding_size)
self.encoder = nn.RNN(embedding_size, hidden_size, batch_first=True)
# 修改了self.mlp
self.mlp = nn.Sequential(
nn.Linear(hidden_size, hidden_size),
nn.Tanh(),
)
self.decoder = nn.RNN(embedding_size + hidden_size, hidden_size, batch_first=True)
self.softmax = nn.Softmax(dim=2)
self.linear = nn.Linear(hidden_size, num_outputs)
def encode(self, enc_x, state):
enc_emb = self.emb_layer(enc_x)
enc_hidden, state = self.encoder(enc_emb, state)
state = torch.mean(self.mlp(enc_hidden), dim=1).unsqueeze(0)
return enc_hidden, state
def decode(self, dec_y, enc_hidden, state):
dec_embs = self.emb_layer(dec_y)
# ==========
# todo 请补全代码
if dec_y.shape[1] > 1:
sent_outputs = []
state = torch.mean(self.mlp(enc_hidden), dim=1).unsqueeze(0)
for t in range(dec_y.shape[1]):
# attention
attn_scores = torch.bmm(state.permute(1, 0, 2), enc_hidden.permute(0, 2, 1)) # (B, 1, H) * (B, H, S) = (B, 1, S)
attn_weights = self.softmax(attn_scores) # (B, 1, S)
context_vector = torch.bmm(attn_weights, enc_hidden) # (B, 1, S) * (B, S, H) = (B, 1, H)
# RNN
decoder_input = torch.cat((dec_embs[:, t, :].unsqueeze(1), context_vector), dim=2) # (B, 1, H+D)
dec_output, state = self.decoder(decoder_input, state)
output = self.linear(dec_output).squeeze(1)
sent_outputs.append(output)
sent_outputs = torch.stack(sent_outputs, dim=1)
else:
# attention
attn_scores = torch.bmm(state.permute(1, 0, 2),
enc_hidden.permute(0, 2, 1)) # (B, 1, H) * (B, H, S) = (B, 1, S)
attn_weights = self.softmax(attn_scores) # (B, 1, S)
context_vector = torch.bmm(attn_weights, enc_hidden) # (B, 1, S) * (B, S, H) = (B, 1, H)
# RNN
decoder_input = torch.cat((dec_embs, context_vector), dim=2) # (B, 1, H+D)
dec_output, state = self.decoder(decoder_input, state)
output = self.linear(dec_output).squeeze(1)
sent_outputs = output.unsqueeze(1)
# ==========
return sent_outputs, state
if __name__ == '__main__':
model = Sequence_Modeling()