作业4¶
提交截至时间:2022/03/11 本周五 20:00(晚上)
理论部分 (范数与二次型)¶
习题 1. 对偶范数常在共轭函数及一些不等式中出现。向量的对偶函数定义为
若向量范数 \(l _ { p }\) 与 \(l _ { q }\) 互为对偶范数,则 \(p , q \in R ^ { n }\) 需满足 \(\textstyle { \frac { 1 } { p } } + { \frac { 1 } { q } } = 1\) (称 \(p , q\) 为 Holder 共轭)
试用对偶范数定义及上述性质证明 Holder 不等式: 对 \(\begin{array} { r } { p > 1 , \frac { 1 } { p } + \frac { 1 } { q } = 1 } \end{array}\) , 以及 \(x , y \in R ^ { n }\) $$ \sum_ {i = 1} ^ {n} \left| x _ {i} y _ {i} \right| \leq \left(\sum_ {i = 1} ^ {n} \left| x _ {i} \right| ^ {p}\right) ^ {1 / p} \left(\sum_ {i = 1} ^ {n} \left| y _ {i} \right| ^ {q}\right) ^ {1 / q} $$
解.
由对偶范数性质
\(p , q \in R ^ { n }\) 且满足 \(\textstyle { \frac { 1 } { p } } + { \frac { 1 } { q } } = 1\)
将其用元素形式展开得 Holder 不等式,证毕
为便于理解,以 \(q = 1 , n = 2\) 为例, $| x | _ { 1 } \leq 1 $ , 不妨只考虑该图像在第一象限部分,
\(Z = \left( \begin{array} { c } { { z _ { 0 } } } \\ { { z _ { 1 } } } \end{array} \right) , X = \left( \begin{array} { c } { { k x _ { 0 } } } \\ { { k ( 1 - x _ { 0 } ) } } \end{array} \right) , \| x \| _ { 1 } = k , 0 \leqslant x _ { 0 } \leqslant 1 , 0 \leqslant k \leqslant 1\)
更一般地,由 Holder 不等式,当 \(\begin{array} { r } { q = \frac { p } { p - 1 } } \end{array}\) , 即 \(\textstyle { \frac { 1 } { p } } + { \frac { 1 } { q } } = 1\) 时, 可得 \(z ^ { \top } x \leq \| x \| _ { p } \| z \| _ { q }\) 。因此该对偶范数性质可以理解为范数视角下的 Holder 不等式。
习题 2. 矩阵的范数主要包括三种主要类型:诱导范数,元素形式范数和 Schatten范数。诱导范数又称矩阵空间上的算子范数 (operator norm),常用的诱导范数为 \(p\) 范数, 定义如下
注:矩阵的诱导范数是由向量范数诱导而来的,向量中的每个元素诱导为了每个列向量 (基)。(1) 设 \(A = ( a _ { i j } ) \in C ^ { m \times n }\) ,证明 \(I\) 范数为列和范数,无穷范数为行和范数
元素形式范数即矩阵按列排成向量,然后采用向量范数的定义得到的矩阵范数,一般称 \(l _ { p }\) 范数。
(2) 试比较 \(l _ {1}\) 范数
与诱导范数的关系
解. (1)
(2)以 \(l _ {1}\) 范数与 1 范数,无穷范数为例,有
实际上对于有限维空间上的任何两个(以矩阵、向量为例) 范数 (满足非负性、齐次性、三角不等式),他们之间都是等价 (equivalent) 的。范数的等价性 (equivalence) 定义如下:
定义 0.0.1. 设 \(\| \cdot \| _ { \alpha }\) 和 \(\| \cdot \| _ { \beta }\) 是 \(R ^ { m \times n } ( R ^ { n } )\) 上任意两个范数, 如果存在 \(\mu _ { 1 } , \mu _ { 2 } > 0 \mathrm { ~ }\) , 使得
则称范数 \(\| \cdot \| _ { \alpha }\) 和范数 \(\| \cdot \| _ { \beta }\) 是等价的。
证: 1. 利用范数三角不等式的性质可以证明对于任意一个 \(F ^ { m \times n }\) 上的范数 \(\left\| \cdot \right\|\) , 函数 \(\varphi : F ^ { m \times n } \mapsto\) \(R , \varphi ( X ) = \| X \|\) 在 \(L _ { 1 }\) 范数下是连续的。
其中, \(E _ { i j } \in F ^ { m \times n }\) 表示只有在第 \(i\) 行第 \(j\) 列的元素为 \(1\) , 其他元素都为 \(0\) 的矩阵。
因此 \(\varphi ( X )\) 是连续函数。
- 故 \(\varphi ( Y ; \alpha ) = \| Y \| _ { \alpha }\) 在有界闭集 \(S = \{ Y \in F ^ { m \times n } : \| Y \| _ { 1 } = 1 \}\) 上连续,又 \(\varphi ( Y ; \alpha )\) 在 \(S\) 恒大于零,因此在 \(S\) 内必有最大值 \(C _ { \mathrm { m a x } } > 0 ,\) , 最小值 \(C _ { \mathrm { m i n } } > 0\) ,
同理可得 \(\varphi ( Y ; \beta ) = \| Y \| _ { \beta }\) 在 \(S\) 内必有最大值 \(D _ { \mathrm { m a x } } > 0 ,\) ,最小值 \(D _ { \operatorname* { m i n } } > 0\) 。
为便于理解,以 \(\alpha = \infty , F ^ { 2 \times 1 } ,\) (向量) 为例,
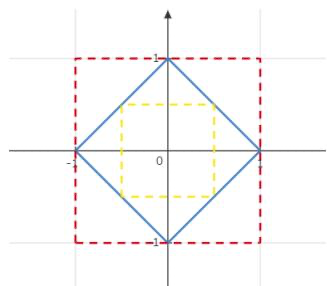
图 1: \(\varphi ( Y ; \infty )\) 在单位范数球 \(S\) 上移动
图中蓝色部分为单位范数球 \(S = \left\{ Y \in F ^ { 2 \times 1 } : \| Y \| _ { 1 } = 1 \right\} , \varphi ( Y ; \infty )\) 在黄色处取到最小值 \(C _ { m i n } =\) \(\begin{array} { l } { { \frac { 1 } { 2 } } } \end{array}\) ,在红色处取到最大值 \(C _ { m i n } = 1\) 。
3 \(. \forall X \in F ^ { m \times n }\) , 若 \(X = \mathbf { 0 } _ { : }\) ,则命题显然成立。
若 \(X \neq \mathbf { 0 } ,\) , 令 \(Y = { \frac { X } { \| X \| _ { 1 } } }\) , \(\| Y \| _ { 1 } = 1\) , 因此对 \(Y \in S ,\) , 有 \(\begin{array} { r } { \frac { \| \boldsymbol { X } \| _ { \beta } } { \| \boldsymbol { X } \| _ { \alpha } } = \frac { \| \boldsymbol { Y } \| _ { \beta } } { \| \boldsymbol { Y } \| _ { \alpha } } \frac { \| \boldsymbol { X } \| _ { 1 } } { \| \boldsymbol { X } \| _ { 1 } } = \frac { \varphi ( \boldsymbol { Y } ; \alpha ) } { \varphi ( \boldsymbol { Y } ; \beta ) } \in \bigg [ \frac { D _ { \operatorname* { m i n } } } { C _ { \operatorname* { m a x } } } , \frac { D _ { \operatorname* { m a x } } } { C _ { \operatorname* { m i n } } } \bigg ] . } \end{array}\)
令 \(\begin{array} { r } { \mu _ { 1 } = \frac { D _ { \mathrm { m i n } } } { C _ { m a x } } } \end{array}\) , \(\begin{array} { r } { \mu _ { 2 } = \frac { D _ { \mathrm { m a x } } } { C _ { \mathrm { m i n } } } } \end{array}\) , 则: \(0 < \mu _ { 1 } \leq { \frac { \| X \| _ { \beta } } { \| X \| _ { \alpha } } } \leq \mu _ { 2 }\)
习题 3. (作为阅读材料,不计入分数)
由 \(\begin{array} { r } { \| A \| _ { p } = \operatorname* { s u p } _ { \| x \| _ { p } \neq 0 } \frac { \| A x \| _ { p } } { \| x \| _ { p } } } \end{array}\)
矩阵 \(A\) 的诱导范数可理解为线性变换 \(A x\) 对向量 \(x\) 的最大“拉长倍数”
由 \(\| A \| _ { p } = \operatorname* { s u p } _ { \| x \| _ { p } = 1 } \| A x \| _ { p } ,\)
矩阵 \(A\) 的诱导范数也可理解为 \(x\) 在单位范数球上运动时 \(\| A x \| _ { p }\) 的最大值
以下情形可便于理解诱导范数
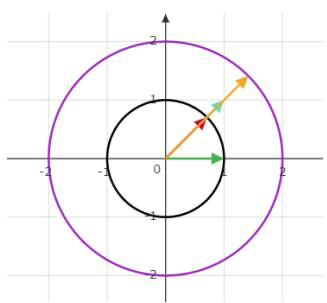
图 2: 诱导范数例 \(\mathrm { ( p } \mathrm { = } 2 )\)
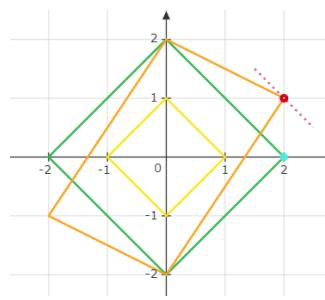
图 3: 诱导范数例 \(( \mathsf { p } \mathrm { = } 1 )\)
例: 左图为 \(A = \left( \begin{array} { c c } { { 1 } } & { { 1 } } \\ { { 1 } } & { { 1 } } \end{array} \right) , p ( A ) = 1 , p = 2\) 时的情形,在 \(x = ( \sqrt { 2 } / 2 , \sqrt { 2 } / 2 )\) \(\| A x \| _ { 2 }\) 取到最大值2
例:右图绿线为 \(A = \left( \begin{array} { c c } { { 2 } } & { { 0 } } \\ { { 0 } } & { { 2 } } \end{array} \right) , p = 1\) 时的情形,在 \(x = ( 1 , 0 )\) 时 \(\| A x \| _ { 1 }\) 取到最大值2
例: 右图橙线为 \(A = \left( \begin{array} { c c } { { 2 } } & { { 0 } } \\ { { 1 } } & { { 2 } } \end{array} \right) , p = 1\) 时的情形,在 \(x = ( 1 , 1 )\) \(\| A x \| _ { 1 }\) 取到最大值3
(1) 试证明
,其中 \(\sigma _ { m a x }\) 为谱范数,即矩阵 \(A\) 的最大奇异值, \(\lambda \left( A ^ { \top } A \right)\) 表示 \(A ^ { \top } A\) 的最大特征值。
证: 即证明对于矩阵 \(A _ { m \times n }\) ,对任意向量 \(x _ { i }\) ,在矩阵 \(A\) 的变换(即 \(A x\) )后, 其长度不大于 \(\sigma _ { m a x } \| x \| _ { 2 }\) 即 \(\| A x \| _ { 2 } \leq \sigma _ { m a x } \| x \| _ { 2 }\) 。
\(A ^ { \top } A\) 是实对称阵,其特征向量两两正交。不妨令 \(B = A ^ { \top } A ,\) ,特征向量矩阵为 $\lambda = d i a g ( \lambda _ { 1 } , . . . , \lambda _ { n } ) $
\(p_1, ..., p_n\) 为 \(B\) 的一组标准正交特征向量,则 \(P = ( p _ { 1 } , . . . , p _ { n } )\) 为正交矩阵, 故
(称 \(\lambda\) 合同于 \(B )\) 假设对一个向量 \(x ,\) 在矩阵 \(A\) 的变换(即 \(A x\) )后得到 \(y\), 即满足 \(y = A x\) 。则
对于二次型,可以看作是一个二次齐次多项式的图形,而正交矩阵 \(P\) 的变换,可以保证变换图形的形状和大小不变,仅仅做了位移、旋转或翻转的变换,类似把物体从一个地方移到另一个地方。(可以想象一个三维坐标系,在坐标系上的点构成的图形通过一个非正交的基表示,现坐标系换了一组标准正交基 \(P\) ,用这组基变换图形不过是移动 (掰正) 了图形的位置。记 \(z = P ^ { \top } x\) ,所以 \(z\) 不过是一个与 \(x\) 一样的(同范数的)向量,只是换了位置,而 \(\lambda = d i a g ( \lambda _ { 1 } , . . . , \lambda _ { n } )\) 则进行了掰正位置后的放缩。因而 $$ \begin{array}{l} | y | ^ {2} = z ^ {T} \left( \begin{array}{c c c} \lambda_ {1} & & \ & \ddots & \ & & \lambda_ {n} \end{array} \right) z = \sum_ {i} \lambda_ {i} z _ {i} ^ {2} \ = \sum_ {i} \left(\sqrt {\lambda_ {i}} z _ {i}\right) ^ {2} \leq \sum_ {i} \left(\max _ {j} \left(\sqrt {\lambda_ {j}}\right) z _ {i}\right) ^ {2} \ = \max \left(\sqrt {\lambda_ {j}}\right) ^ {2} \sum_ {i} z _ {i} ^ {2} = \max \left(\lambda_ {j}\right) | z | ^ {2} = \max \left(\lambda_ {j}\right) | x | ^ {2} \ \end{array} $$
当且仅当除 \(\boldsymbol { z } _ { o p t \operatorname* { m a x } _ { j } \left( \lambda _ { j } \right) }\) 以外的其他元素均等于 \(0\) 时, 该不等式的等号成立。
即 \(\| A x \| _ { 2 } \leq \sigma _ { m a x } \| x \| _ { 2 }\) ,证毕
(2)元素形式下矩阵的 \(l _ { 2 }\) 范数称为 Frobenius 范数,即
试比较 \(\| A \| _ { 2 }\) 与 \(\| A \| _ { F }\) 的大小
答: \(\| A \| _ { 2 } \leq \| A \| _ { F }\)
习题 4. 上题提到矩阵 \(A\) 的诱导范数也可理解为 \(x\) 在单位范数球上运动时 \(\| A x \| _ { p }\) 的最大值,而对于某些矩阵, \(x\) 的巨大变化只能引起 \(A x\) 很小的变化(旋转而非放缩)。反之,对于线性方程组 \(A x = b\) , \(b\) (或 \(A\) )的微小变化会带来解 \(x\) 的巨大变化。这样的矩阵 \(A\) (及线性方程组)称作病态的。如 \(A = \left( \begin{array} { c c } { 1 } & { 1 } \\ { 1 } & { 1 . 0 0 0 1 } \end{array} \right)\)
\(\left\| \delta b \right\| _ { \infty }=\begin{array} { r } { \left| ( 2 , 2 ) ^ { \mathrm { T } } - ( 2 , 2 . 0 0 0 1 ) ^ { \mathrm { T } } \right| _ { \infty } = 0 . 0 0 0 1 , \left\| \delta x \right\| _ { \infty } = \left\| ( 2 , 0 ) ^ { \mathrm { T } } - ( 1 , 1 ) ^ { \mathrm { T } } \right\| _ { \infty } = 1 , } \end{array}\)
方程组解 \(x\) 的变化程度是 \(b\) 变化程度的 10000 倍, 因此称矩阵 \(A\) 是病态的。
(1) 试推测什么样的矩阵是病态矩阵,用矩阵范数表示。
提示:对线性方程组 \(A x = b ,\) 设 \(A\) 是精确的, \(b\) 有微小的扰动 \(\delta b ,\) , 新方程组的解为 \(x + \delta x ,\) 即\(A ( x + \delta x ) = b + \delta b ,\) , 用
证明
解. 对于提示中的证明,将两个不等式相乘即可,故评价矩阵输入误差的敏感性指标为 \(k ( A ) =\) \(\| A \| \cdot \left\| A ^ { - 1 } \right\|\) (又称条件数)。
以二维向量为例, \(A = ( a _ { 1 } , a _ { 2 } )\) 对 \(x\) 的变换 \(A x\) 相当于把 \(x\) 从 (1,0),(0,1) 的基换成了 \(a _ { 1 } , a _ { 2 }\) 的基下表示,而这个变换又可以拆分为旋转,放缩和投影三种效应(通过之后会学到的奇异值分解)。对于 \(A = { \left( \begin{array} { l l } { 1 } & { 1 } \\ { 1 } & { 1 } \end{array} \right) }\) 这样的奇异阵,由于基 (1,1) 与 (1,1) 方向相同,所以 \(A x\) 只能在一个方向移动(没有旋转),同时也可注意到最小特征值为 \(0\) (由于 \(A\) 是对称方阵,特征向量两两正交,故特征值与奇异值相等)。
\(\begin{array} { r } { A ^ { ' } = \left( \begin{array} { c c } { 1 } & { 1 } \\ { 1 } & { 1 . 0 0 0 1 } \end{array} \right) } \end{array}\) 只是在上述共线的基上进行很小的变换,所以基的夹角很小,即使 \(x\) 变化很大,也只能引起 \(A x\) 很小的变化。同时也可注意到,最小特征值从 \(0\) 变为约 0.00005。
实际上,在二范数下,条件数等于最大奇异值与最小奇异值的比。
其中, \(\sigma _ { \mathrm { m a x } } ( A )\) 为矩阵 \(A\) 的最大奇异值, \(\sigma _ { \mathrm { m i n } } ( A )\) 为矩阵 \(A\) 的最小奇异值。
特殊地,对于对称方阵,特征值与奇异值相等,条件数又可表示为
其中, \(\lambda _ { \operatorname* { m a x } } ( A )\) 为矩阵 \(A\) 的最大特征值, \(\lambda _ { \operatorname* { m i n } } ( A )\) 为矩阵 \(A\) 的最小特征值。