2024期末大作业实验报告¶
一、实验环境¶
我使用的库并不特殊,为了方便复现,以requirements.txt的格式给出:
torch==2.1.2 torchaudio==2.1.2 torchvision==0.16.2 tqdm==4.65.0 numpy==1.24.3 ftfy==6.1.3 grpcio==1.60.0 accelerate==0.25.0 transformers==4.32.1 pandas==2.0.3
系统环境是UCloud的云主机平台(Ubuntu 22.04 64位)
GPU: Tesla V100S-PCIE-32GB显存
但是有一点需要特别注意,为了保证可复现性,我的模型虽然保存到了本地但是体积有点大,不适合传输到水杉平台,我将其上传到了Google Drive供下载(https://drive.google.com/drive/folders/193qZb-DCXRSAGNSmIMkmDO8AWNydckv6)如果下载出现问题可以联系本人。
代码就一个文件main.py,如果不想加载本地的模型而是重新开始训练,可以把is_load设置为False。代码运行就指定对应目录终端输入python main.py即可。
二、实验过程¶
(1)正式实验之前的思考¶
正常情况我们对于文档检索任务的思路是什么?对于文档和查询的问题,正常来说通过预训练模型的tokenizer,将每个词映射到对应的token,再通过词嵌入算法映射成对应的embedding向量,最后只要计算出向量之间的相似度即可。因为词嵌入算法保证语义相关的向量在向量空间中靠近,所以这套方法理论上来说可以保证相关的文档相似度也相应更高。
结合老师的一再提醒,这次实验的初衷并不是让我们使用预训练模型;而且数据是被脱敏的,文本数据已经经历了未知模型之tokenizer处理,所以我们不能依赖它们进行词嵌入;baseline是单纯依靠doc和query之间embedding的余弦相似度运算的,超差的效果表明doc和query的embedding虽然都是1024维,但是并非在一个向量空间,所以无法保证它们如果相关则余弦相似度更大。
经过漫长思考,我甚至觉得这个实验压根就无从下手。我尝试过BERT等预训练模型,也用过聚类这样的经典算法,但是效果都非常差。经过不断的思考和实验,我终于找到了一套行之有效的模型,碍于篇幅限制此处不多描述中间的失败尝试,只描述最终的解决方案。
我最终的方案有两个模型,分别是分类模型和预测模型,它们都面向embedding而不是token。整体思想是通过第一个模型的缩小范围之后,让第二个模型在缩小的范围中找Top3相关的答案。
(2)模型构建¶
1缩小范围、查找是否相关:分类模型¶
文档条目数量是非常多的(26599条),但是对于某个query而言相关的文档非常少,我们需要的还仅仅是其中很小的一部分(top3).巨大的不均衡现象促使我思考,能不能先缩小一下查找的范围,把那些不太相关的文档先过滤掉?如果筛选工作是有必要的,我应该依据什么进行筛选呢?最自然的思路便是根据某个query和某个doc是否相关作为指标。
我主要的想法是操作embedding而不是token(也保证了训练数据维度的一致性),对于来自query和doc的embedding,各自都是1024维的向量,我该如何统筹呢?这里最自然的思路是直接将两个embedding拼接起来形成一个2048维的向量,即(query_embedding, doc_embedding),然后再对这个2048维的向量输入模型即可。
这个模型只是在做查找是否相关,它岂不就只是个二分类模型了?是的,它的确是一个二分类模型,输出就是0(不相关)或者1(相关)。要进行二分类,我有很多选择,结合上学期人工智能课程的实验,我发现感知机的效果是最好的,所以在这个任务中也采用了感知机模型。
class ModelMLP(nn.Module):
def __init__(self, input_dim, hidden_dim, num_classes, num_layers):
super(ModelMLP, self).__init__()
self.layers = nn.ModuleList()
self.layers.append(nn.Linear(input_dim, hidden_dim))
for _ in range(num_layers - 1):
self.layers.append(nn.Linear(hidden_dim, hidden_dim))
self.output_layer = nn.Linear(hidden_dim, num_classes)
def forward(self, x):
for layer in self.layers:
x = nn.functional.relu(layer(x))
x = self.output_layer(x)
return x
def initialize_weights(self):
for layer in self.layers:
if isinstance(layer, nn.Linear):
nn.init.kaiming_normal_(layer.weight.data)
nn.init.zeros_(layer.bias.data)
input_dim = 2048
num_classes = 2
hidden_dim = 512
num_layers = 3
criterion = nn.CrossEntropyLoss().to(device)
learning_rate = 5e-4
model = ModelMLP(input_dim, hidden_dim, num_classes, num_layers).to(device)
model.initialize_weights()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
前面也提到了,为了解决这个二分类问题,我的思路是采用感知机。因为类别比较少(num_classes仅为2),所以感知机的层数其实不用很多,我在实际中设置为3层num_layers。这个模型的输入是(embedding, embedding),所以是2048维的。为了展现较强的分类能力,我的隐藏层神经元数量(hidden_dim)设置为了512,层与层之间采用relu作为激活函数。
因为自己要训练的轮次比较多(几百轮往上),这个光秃秃的MLP实际来看很容易出现梯度爆炸和消失现象,为了缓解这个问题,结合这里的教程[1] [2],我意识到权值初始化的重要性。又因为我采用的激活函数是relu,所以采用了kaiming正态分布的方式来做初始化,实际发现初始化之后提升非常明显。
2embedding映射后的进一步细化:预测模型¶
经过刚刚的操作,我们训练得到的是一个能通过(query_embedding, doc_embedding)来判断这个query和doc是否相关的模型。通过它我们能极大地缩小搜寻规模但是还是无法很精细地得到Top3的文档,那么我该怎么办呢?结合我最开始的分析,我们得知query的embedding和doc的embedding并不是在一个向量空间中,否则效果也不至于那么差,那么我们完全可以训练一个query_embedding到doc_embedding的映射。对于某个query_embedding而言,它在doc_embedding空间中的映射pred去和document中的各个embedding做余弦相似度找k=3个最大的即可。
为了实现这样的seq2seq功能,我本来的想法是采用LSTM这样基于RNN的架构,但是想到当前深度学习领域主流的架构还是基于Transformer的,所以就想去改进Transfomer来适配这一任务。
class ModelTransformer(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim, num_layers, num_heads, dropout):
super(ModelTransformer, self).__init__()
self.input_dim = input_dim
self.hidden_dim = hidden_dim
self.output_dim = output_dim
self.num_layers = num_layers
self.num_heads = num_heads
self.dropout = dropout
self.embedding = nn.Linear(input_dim, hidden_dim)
self.transformer = nn.Transformer(hidden_dim, num_heads, num_layers, num_layers, dim_feedforward=hidden_dim * 4, dropout=dropout)
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
x = self.embedding(x)
x = x.permute(1, 0, 2) # Transformer expects input of shape (seq_len, batch_size, hidden_dim)
transformer_out = self.transformer(x, x)
transformer_out = transformer_out.permute(1, 0, 2) # Convert back to (batch_size, seq_len, hidden_dim)
out = self.fc(transformer_out[:, -1, :]) # Use the output from the last time step
return out
input_dim_transformer = 1024
hidden_dim_transformer = 512
output_dim_transformer = 1024
num_layers_transformer = 3
num_heads_transformer = 8
dropout_transformer = 0.1
model_predict = ModelTransformer(input_dim_transformer, hidden_dim_transformer, output_dim_transformer, num_layers_transformer, num_heads_transformer, dropout_transformer).to(device)
我使用一个线性嵌入层将输入特征映射到高维空间,然后通过多层Transformer处理嵌入后的特征,最后通过一个全连接层生成最终的输出结果,这种架构比较适用于处理序列数据。前向传播过程中值得注意的几点包括:
1 嵌入层输入的已经是embedding数据了,直接过一遍全连接层即可;
2 x.permute(1, 0, 2)将输入 x的形状从 (batch_size, seq_len, hidden_dim) 转换为 (seq_len, batch_size, hidden_dim),以符合 Transformer 的输入要求。
3 将嵌入向量输入到 Transformer 层,x 既是输入序列,又是目标序列。
4 transformer_out.permute(1, 0, 2)将 Transformer 的输出形状从 (seq_len, batch_size, hidden_dim) 转换回 (batch_size, seq_len, hidden_dim)。
5 再使用最后一个时间步的输出,通过全连接层生成最终输出。
我直接使用torch封装好的Transformer架构,transformer层包含多个 Transformer 编码器层,用于处理嵌入后的输入。它输入向量的维度和嵌入层的输出是一样的,都被我设置为了hidden_dim=512。注意力头的数量(num_heads)被我设置为了8;Transformer 的层数(num_layers)为3;为防止过拟合,Dropout 概率设为0.1;前馈网络的维度(dim_feedforward)被设置为了hidden_dim的 4 倍。这些超参数的设定有的基于Transformer的原始论文,有的是基于我日常使用的经验。
(3)数据集预处理与构建¶
1分类模型¶
分类模型的训练数据集应该怎么搞?看了一遍又一遍的数据样貌,我对构建数据有了眉目:
来源一:训练集query_trainset中,对于某个问题query,提供了它的query_embedding,也有它的evidence_list。在evidence_list中,有几条和这个query相关的、在document词嵌入空间的fact_embedding,显然这几条(query_embedding, fact_embedding)是相关的。
来源二:实验要求文档中评分指标部分有一句话:“标准答案里面的fact_input_list只有一句话,只要你检索到的文档里面包含这句话即可。” 再看一眼query_trainset的evidence_list,我发现它不仅给了fact_embedding,还给了token(fact_input_list)! 结合那里示范的计算recall和MRR值的代码,这样我就能以类似的方式(去掉开始和结尾的字符通过token反向查询到对应的document)找到某条fact在document中对应的条目,进而找到它的facts_embedding。

上面这个过程听起来确实不太浅显易懂,所以我一步一步来拆开讲解:
def preprocess_tokens(data):
return [' '.join(map(str, item['fact_input_list'][1:-1])) for item in data]
def query2docBytoken(query, document):
query_tokens_list = [preprocess_tokens(q['evidence_list']) for q in query]
document_tokens_list = preprocess_tokens(document)
query_doc_pairs = [(i, j)
for i, q in enumerate(query_tokens_list)
for j, d in enumerate(document_tokens_list)
if any(q_token in d for q_token in q)]
with open('query2doc.txt', 'w') as f:
f.writelines(f'{item}\n' for item in query_doc_pairs)
preprocess_tokens处理输入数据,提取每个数据项中 fact_input_list`字段中的元素(去掉第一个和最后一个元素),将这些元素转换为字符串并连接成一个字符串列表。
query2docBytoken先对query中每个evidence_list字段和文档document用preprocess_tokens处理生成对应的词列表;然后遍历每个查询和文档,检查查询中的任何一个词是否在文档中出现,若出现,则将该查询和文档的索引对(i, j)加入结果列表 query_doc_pairs。为了避免每次程序运行都进行query2docBytoken,我将query_doc_pairs的结果保存到了文件中。
query_doc_pairs = []
if not os.path.exists('query2doc.txt'):
query2docBytoken(query, document)
with open('query2doc.txt', 'r') as f:
query_doc_pairs = [tuple(map(int, line.strip('()\n').split(','))) for line in f]
positive_num2 = len(query_doc_pairs)
data2 = torch.empty((positive_num2, 2048)).to(device)
label2 = torch.ones((positive_num2, 1)).to(device)
data2 = torch.stack([
torch.cat((
query_embeddings[i],
doc_embeddings[j]
))
for i,j in query_doc_pairs
])
接下来要干的事便是读取query2docBytoken的结果文件,对于结果文件中的(i, j)而言,拼接(query_embeddings[i], doc_embeddings[j])即可认为是相关的
来源三:最难的便是构建不相关数据了,这个问题的搁置一度让我放弃了这一思路。结合深入的查询资料查阅,我发现Negative Sampling是信息检索领域中非常经典的问题,尤其是用于训练rerank模型时。在训练重排序模型时,通常需要正样本和负样本来帮助模型学习如何区分相关和不相关的文档。正样本是与查询相关的文档,而负样本是不相关的文档。Negative Sampling一般采用的方法是Random Negative(随机选择的负样本,通常是与查询无关的文档。这些样本可能很容易被模型区分,因此对模型的训练效果有限。)和Hard Negative(与查询有一定程度的相似性,模型在早期阶段可能会误认为它们是相关的文档。这些样本通常是模型在初步检索中排名靠前但实际上不相关的文档。)
引入 hard negative 样本有助于增强模型的区分能力。通过训练模型正确区分这些难以识别的负样本,模型可以学习到更细致、更准确的特征,从而提升其在实际应用中的性能。但是,hard negative样本的构建还是比较复杂的,为了节省时间我还是选择了random negative。结合我之前的分析,对某个query来说相关的文档在整个大的document集合中只是很小的一部分,所以通过随机采样得到的样本配对即便偶尔会出现假阴性,但我们大致可以认为整体上是不相关的。
而且更有支撑性的是,其实我也尝试过一些预训练的rerank模型(当然效果都一般),以BGE Reranker[3]来说,它的官方文档[4]里面对于数据预处理的环节也说到了" If you have no negative texts for a query, you can random sample some from the entire corpus as the negatives. "
data3 = torch.empty((negative_num, 2048)).to(device)
label3 = torch.zeros((negative_num, 1)).to(device)
data3 = torch.stack([
torch.cat((
query_embeddings[random.randint(0, 2043)],
doc_embeddings[random.randint(0, 26598)]
))
for _ in range(negative_num)
])
为了确保随机性,我的负样本并不是预先就生成好的,而是在训练过程中随机生成的,这也就意味着每一轮都会来随机生成一批负样本。并且为了保证数量的充分,我调整负样本总数为正样本数量的两倍(负样本更多一些,而不是两者均衡,实际测试发现两者均衡情况下表现一般)
2预测模型¶
为了构建适用于模型的训练数据,其实十分简单。简单起见输入就是query_embedding,输出(标签)就是它的evidence_list各个fact_embedding(来自doc_embedding的向量空间)
query_embeddings_transformer = [entry['query_embedding'] for entry in query if entry['evidence_list'] for _ in entry['evidence_list']]
document_embeddings_transformer = [evidence['fact_embedding'] for entry in query if entry['evidence_list'] for evidence in entry['evidence_list']]
query_embeddings_transformer = torch.tensor(query_embeddings_transformer, dtype=torch.float32, device=device)
document_embeddings_transformer = torch.tensor(document_embeddings_transformer, dtype=torch.float32, device=device)
dataset_transformer = TensorDataset(query_embeddings_transformer, document_embeddings_transformer)
dataloader_transformer = DataLoader(dataset_transformer, batch_size=batch_size_transformer, shuffle=True)
(4)模型训练¶
1分类模型¶
模型训练部分我的MLP训练了1000轮,batch_size设为256,训练集与验证集的比例设置为了9:1(因为每轮训练的数据集是不一样的,所以我想着构建好了之后再划分),学习率5e-4,损失函数是交叉熵,优化器是Adam。
epochs = 1000
batch_size = 256
for e in range(epochs):
# 构建负样本data3和对应的label3
data = torch.cat((data1, data2, data3), dim=0)
label = torch.cat((label1, label2, label3), dim=0)
dataset = TensorDataset(data, label)
train_dataset, val_dataset = random_split(dataset, [train_size, val_size])
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
for d, l in tqdm(train_dataloader):
optimizer.zero_grad()
out = model(d)
true_label = torch.flatten(l).long()
loss = criterion(out, true_label)
loss.backward()
optimizer.step()
if e % 50 == 0:
print("Epoch" + str(e))
model.eval()
val_acc = 0
val_loss = 0
with torch.no_grad():
for vd, vl in tqdm(val_dataloader):
val_out = model(vd)
val_true_label = torch.flatten(vl).long()
val_loss += criterion(val_out, val_true_label).item()
_, val_predicted = torch.max(val_out.data, 1)
val_acc += torch.sum(val_predicted == val_true_label).item()
val_loss /= len(val_dataloader)
val_acc /= len(val_dataset)
print(f'Validation Loss: {val_loss:.6f}, Validation Accuracy: {val_acc:.6f}')
2预测模型¶
模型训练环节我没什么需要深入阐述的,epoch被我设置为了1600,实际训练中发现这个epoch还是比较合理的,尤其是从500到1000的提升带来了模型整体效果的跨越式提升。
epochs_transformer = 1600
model_predict.train()
for e in range(epochs_transformer):
for i, (queries, documents) in enumerate(dataloader_transformer):
outputs = model_predict(queries.unsqueeze(1))
loss = criterion(outputs, documents)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'Epoch {e}, loss: {loss.item():.6f}')
(5)模型整合:推理阶段¶
模型推理就像我之前所讨论的那样,先通过二分类模型将相关文档的范围缩小到k1(在整个document集合中选择k1条和query相关概率最大的),我的k1设置为了7;再在这k1个文档里面通过预测模型进行rerank,找到k=3个最相关的文档。这个地方值得小心的就是数据输入的维度问题,自己调试了很久。具体来说,先根据query_embedding用二分类模型找到最大可能相关的k1个文档,获得它们的序号top_relevant_document_indices,然后根据序号索引对应的document,并提取出相应的doc_embedding,组合起来成为doc_embeddings。接下来通过预测模型将query_embedding映射到doc_embedding空间中,成为新的向量pred。最后只需要拿着这个pred和doc_embeddings中各个doc_embedding做余弦相似度即可。这个过程的索引很容易混淆,重点是转换逻辑不能混。
def retrieve_top_k_documents(query_embedding, document_embeddings, k=3):
# from baseline
similarities = torch.nn.functional.cosine_similarity(query_embedding.unsqueeze(0), document_embeddings, dim=-1)
# 使用topk获取排序后的索引,然后选择前k个最大的相似度值对应的document索引
_, top_document_indices = similarities.topk(k)
return top_document_indices.tolist()
def search_relevant_doc_indices(model, query_embedding, doc_embeddings, k, device):
# 找k个最有可能是相关的文档
query_embedding = query_embedding.unsqueeze(0).repeat(len(doc_embeddings), 1).to(device)
doc_embeddings = doc_embeddings.to(device)
data = torch.cat([query_embedding, doc_embeddings], dim=1)
model = model.to(device)
out = model(data)
# 取出预测为1(相关)的概率
similarities = out[:, 1]
_, top_k_indices = similarities.topk(k)
return top_k_indices.tolist()
def inference(model, test_query, doc_embeddings, document, device, model_predict, k1=7):
results = []
for item in tqdm(test_query):
result = {}
query_embedding = torch.tensor(item['query_embedding']).to(device)
model.eval()
model_predict.eval()
with torch.no_grad():
top_relevant_document_indices = search_relevant_doc_indices(model, query_embedding, doc_embeddings, k1, device)
result['query_input_list'] = item['query_input_list']
doc_embeddings_relevant = doc_embeddings[top_relevant_document_indices]
query_embedding_pred = model_predict(query_embedding.unsqueeze(0).unsqueeze(1)).squeeze(0)
top3_docs_indices = retrieve_top_k_documents(query_embedding_pred, doc_embeddings_relevant, k=3)
rerank_indices = [top_relevant_document_indices[i] for i in top3_docs_indices]
result['evidence_list'] = [{'fact_input_list': document[index]['fact_input_list']} for index in rerank_indices]
results.append(result)
return results
k1 = 7
test_query = read_json('input/query_testset.json')
results = inference(model, test_query, doc_embeddings, document, device, model_predict, k1)
三、实验结果¶
经过困难的调试,笔者在2024年6月14日中午,即实验截止前夕终于完成了实验,结果如下所示:
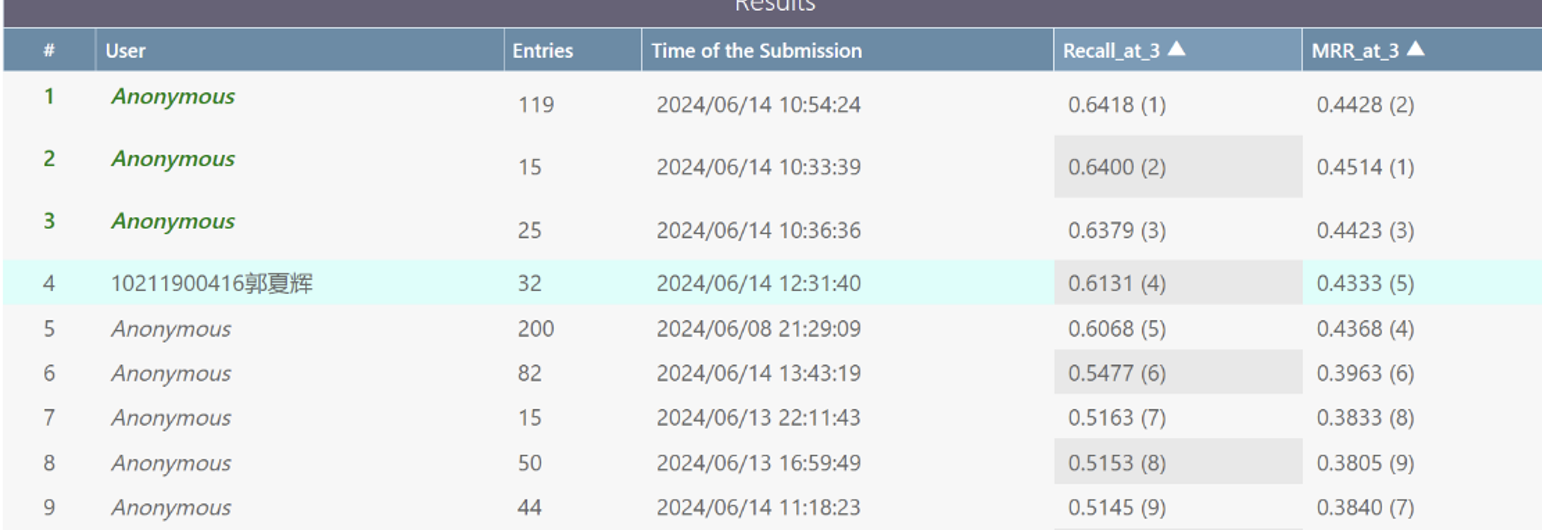
可以看到整体上自己在检索任务上相对于baseline取得了非常明显的提升,最终的结果还是不错的。但是有点遗憾的是本次实验中自己主要利用的是embedding, 并没有非常全面地利用token,兴许利用好token能取得进一步的性能提升。
最后,也感谢老师、助教学姐一学期以来的辛苦传授~希望我能利用好《深度学习》这门课打下的基础,在未来真正的科研中取得有用的进步。
[1] https://blog.csdn.net/abcdrachel/article/details/102898243
[2] https://datawhalechina.github.io/thorough-pytorch/第三章/3.5%20模型初始化.html
[3] https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/reranker
[4] https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune#data-format