实验报告¶
上机实践名称:数据结构
上机实践编号:No.6
上机实践日期:2023年4月6日
目的¶
1.熟悉算法设计的基本思想。
2.掌握栈、链表等基本数据结构。
3.掌握使用非显式指针来表示链表等数据结构的方法。
内容与设计思想¶
- 用多重数组实现单链表。
- 实现在该单链表上的“增删查改排”操作,插入并不一定在头部插入,排序可以用任意一种排序方法。注意释放对象。
- 和用指针实现的链表相比,本次实验中实现的链表有什么使用和性能上的异同呢?(选做)请通过实验来验证你的猜想。
使用环境¶
推荐使用C/C++集成编译环境。
实验过程¶
1. 写出多重数组单链表的源代码。
2. 验证实现的正确性,给出各种情况的测试数据和运行结果。
3. 分析并提出假设并验证你的猜想。
l 指针实现链表
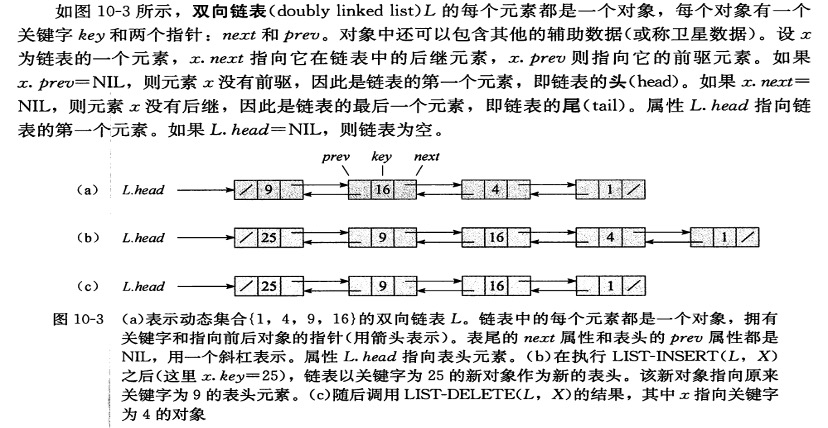



通过指针实现链表是繁琐的,我结合实际情况写了一下相关的代码(见附件)。
l 多数组实现链表
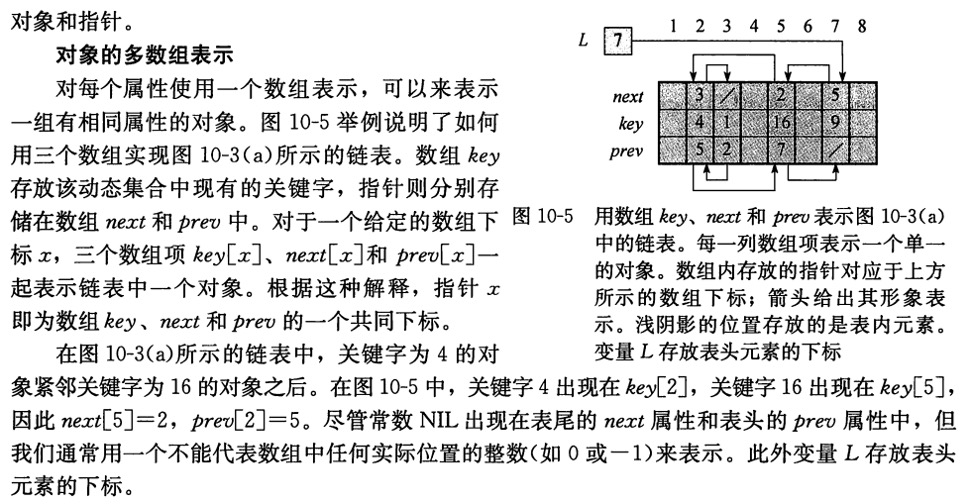
用多数组来实现单链表相对来说要更加容易一些,为了便利自己的操作,我将表示链表的三个数组放到了一个类中,通过封装相关的函数简化了实现的过程。虽然这个题目只是要求实现单链表,但为了简化相关的流程,我采用的其实是双链表模型。
对于“增”操作,就正常的判断、循环即可,重点是对边界条件的处理;对于“删”操作,也是很简单的操作,重点是先后顺序不要搞混了(数据结构小知识点/敲黑板);对于“查”操作,要按顺序地从头找到对应的元素,此时要注意边界条件;对于“改”操作,应该先特判一下改的索引值不能越界,然后再执行一个“查”之后实现对相应元素的修改,这里不可避免的查询操作是时间复杂度无法降低的根本原因。而最后对于排序操作,我在实际操作的过程中碰到了许多问题。
首先从最优化的排序算法入手,由于链表在内存空间上是不一定连续的,快速排序这样的基于连续空间的排序算法是无法使用的——每次都要找一个合适的pivot消耗的平均时间太大了!但是利用分治的归并排序算法却行,主要思路是这样的:首先找到链表的中心结点,然后以此二分两边进行merge操作即可——这样的时间复杂度和正常的归并排序一样,是Θ(nlgn).
可是实现链表上的归并排序是复杂的,对于我们眼前的问题,是不是可以采用虽然时间复杂度较差但更容易实现的算法呢?很直接的想法是冒泡排序和插入排序,因为这两种排序算法都是根据某个元素相邻的元素不断比较最后达到使一个数列有序化的目的,而链表中我们可控的元素不正是某个结点的相邻结点吗?我在实际的代码实践过程中是以插入排序完成的,具体的方法就不再赘述了,可以参考传统的插入排序的流程。但是这里有一个小细节,就是插入排序找的那个插入的地方距离当前元素的位置毕竟还是有些距离的,不像冒泡排序那样即便交换也就仅仅是相邻元素的交换。基于链表的性质,如果这里使用冒泡排序,在需要交换相邻元素时其实不需要使得相邻的那两个元素的三个特征全部交换,我们只需要交换其中的val值就行了!这样就可以节省很多赋值等操作消耗的时间。即便这样确实取得了很大的优化,但从时间复杂度角度来讲冒泡排序和插入排序一样都是Θ(n^2).
总结¶
对上机实践结果进行分析,问题回答,上机的心得体会及改进意见。
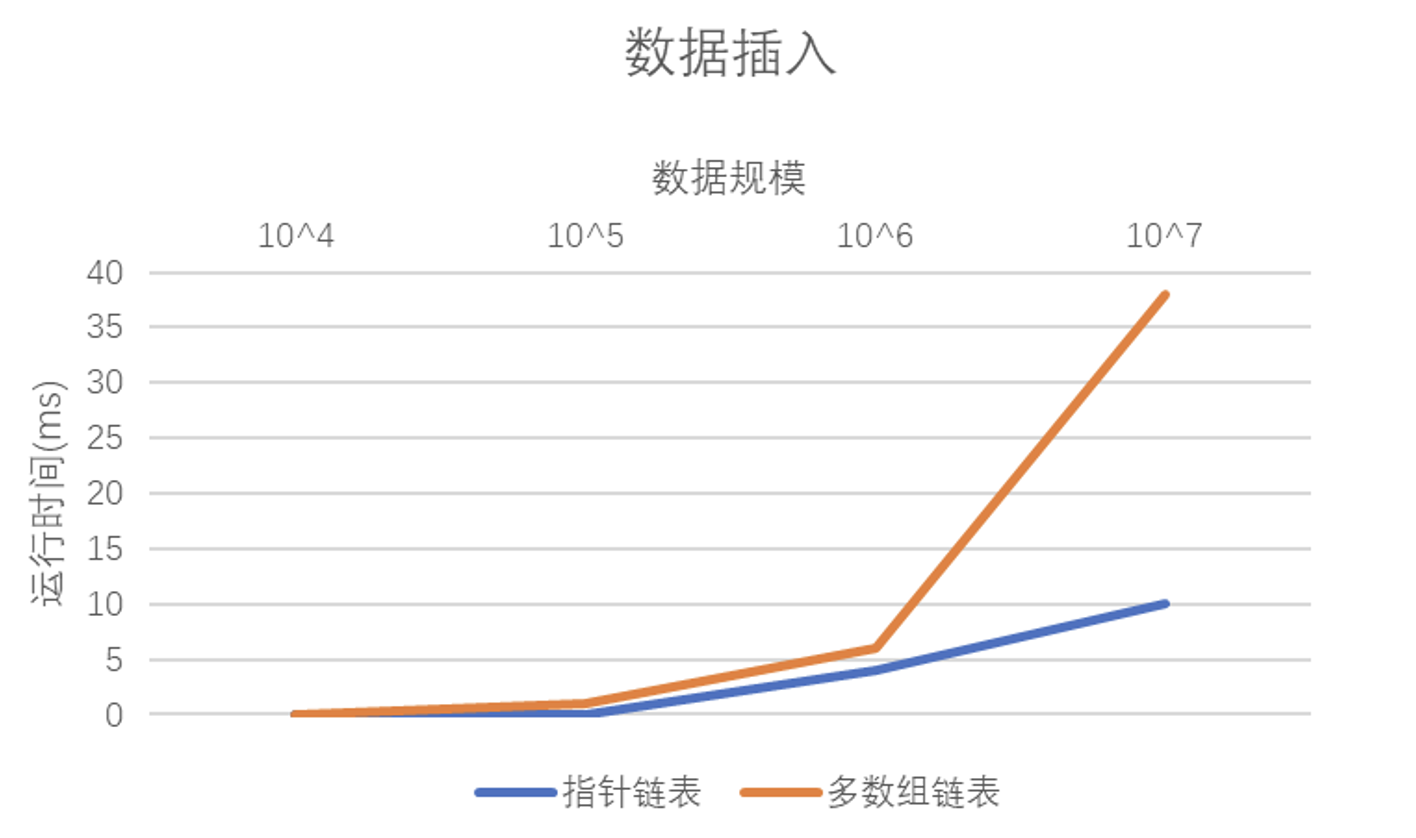
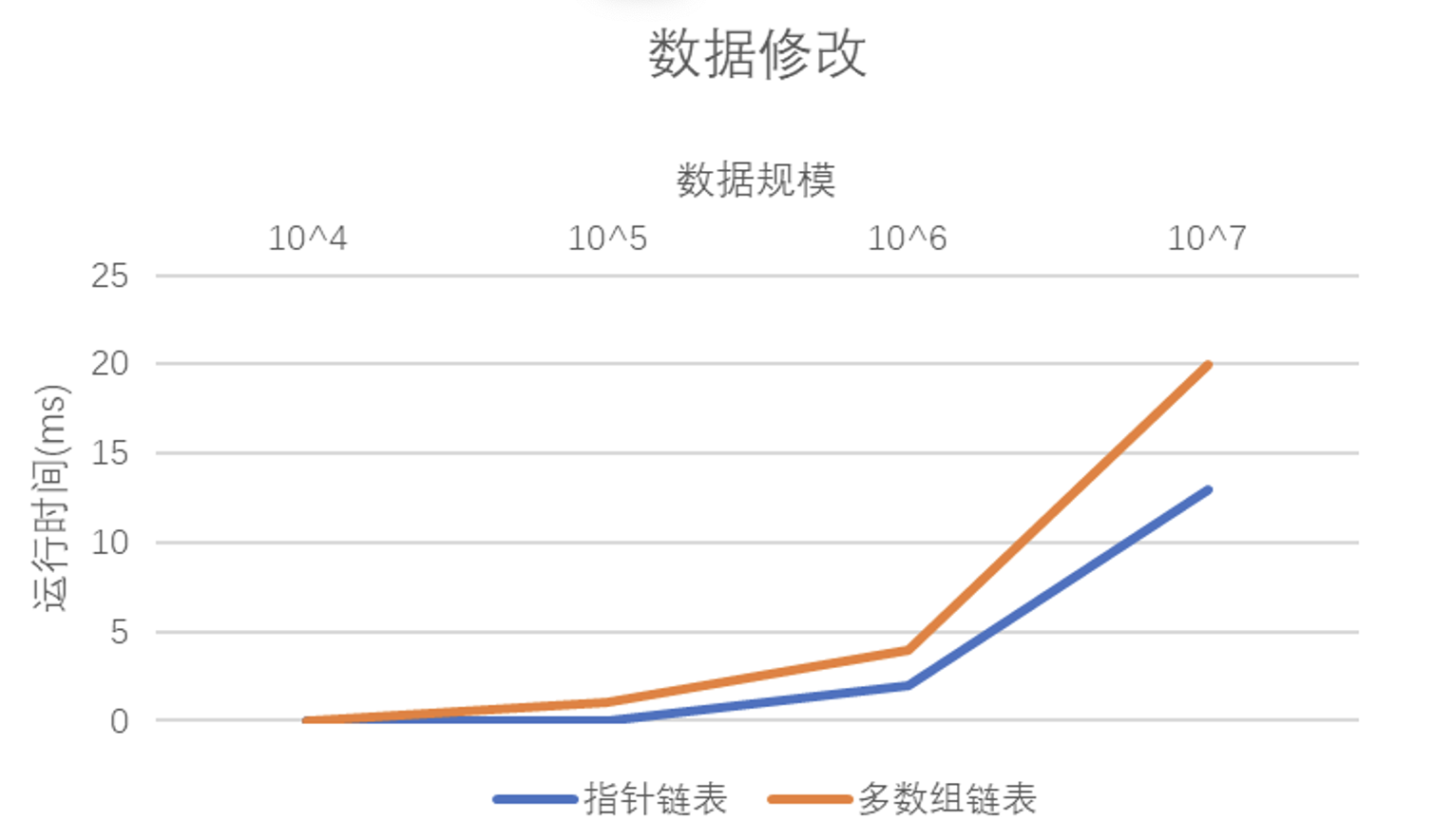
虽然本次实验没有明确地要求,但我还是简单地比较了一下两种链表的修改和插入操作。在实际情况中,由于我的指针式链表通过的是尾插法插入结点但是多数组链表在插入之前要先通过一个循环到对应的位置,所以很明显多数组链表的插入操作时间复杂度是线性的。对于数据修改的情况与之类似,时间复杂度也是线性的。即便我没有绘制查找操作的时间复杂度对比图,但是其运行情况应该是类似于上述两张图的,还是线性的时间复杂度。
如果使用头插法构建链表,多数组实现链表的运行时间应该是小于指针实现的,这主要是因为指针结点要花费大量的时间在无意义的操作上,但是多数组的运行过程却没有额外的操作。
本次实验从整体上来说还是比较简单的,通过实现多数组链表的简单操作,我对链表的原理有了一个更为深刻的认识,相信未来能更加好的利用链式数据结构在特定场合下的价值。