2025春深度学习平时实验标准答案¶
lab2¶
实现一元线性回归模型
用随机梯度下降法(SGD)和最小二乘法(LSE)优化一元线性回归模型
• 不能修改项目内部给定的代码,不能import其他工具包,只能在“to do”下面书写代码
• 提交之后,测试集上的损失值应该降到一个正确的范围内
• 可多次提交
标准答案
lab3¶
1.熟悉pytorch的自动求导流程
2.实现softmax线性分类模型
• 完成softmax函数并利用梯度下降法优化softmax线性分类模型
• 不能修改项目内部给定的代码,不能import其他工具包,只能在“to do”下面书写代码
def softmax(X):
'''
X is the input
Please compute its softmax outputs
'''
# ===============
# todo: 不调用torch的softmax,手写softmax函数,并返回
# ===============
def manual_backward(self, X, y, y_hat):
'''
X is the input feature;
y is the ground truth label;
y_hat is the predicted label.
Please update self.linear.weight and self.linear.bias
'''
with torch.no_grad():
# ==============
# todo: 将automatic_update设为False,不调用torch的自动更新,手动完成梯度下降法优化'''
# ===============
lab5¶
• 你需要做的:根据提示,补全CNN代码
• 利用设定好的输入完成卷积函数(准确的说互相关函数)和汇聚层的前向传播
• 不能修改给定的对象属性,不能调用其他工具包, 只能在“to do”下面书写代码
• 提交之后,测试集上的准确率应该降到一个正确的范围内并且cnn_hard_version.py文件是可执行的
• 可多次提交。即使对自己的代码没有自信也一定要提交,我们会酌情给过程分
• 禁用pytorch自带函数convXd, einsum和as_strided.
• TO DO: 完成《Convolutional Neural Network》项目。补全cnn_hard_version.py文件使exercise_cnn.py文件中的train_with_CNN_hard()可以顺利执行。
• 如果你有额外时间:尝试不同的CNN模型
• 读懂exercise_cnn.py文件中的代码,熟悉图像识别任务的代码流程,可通过display_cifar看到数据集的图像
• 理解通过pytorch版本实现的CNN模型(cnn_easy_version.py中的CNN实现代码),并尝试修改CNN的参数(如:kernel size, out channel, stride, zero padding size等)或者框架(如:修改卷积块的个数,激活函数等)看看其对模型训练的影响
标准答案
class Conv2D(nn.Module):
def __init__(self, out_channels, in_channels, kernel_size):
super(Conv2D, self).__init__()
self.weight = np.random.randn(out_channels, in_channels, kernel_size[0], kernel_size[1])
self.bias = np.random.randn(out_channels)
def forward_np(self, X):
'''
X --> (B, I, H, W) where B = batch size, I = in_channel, H = height of feature map, W = width of feature map
你需要利用以上初始化的参数weight和bias实现一个卷积层的前向传播
Y should have size (B, O, H-h+1, W-w+1)
'''
Y = corr2d(X, self.weight) + np.reshape(self.bias, (1, -1, 1, 1))
return Y
def corr2d(X, K):
'''
X --> (B, I, H, W) where B = batch size, I = in_channel, H = height of feature map, W = width of feature map
K --> (O, I, h, w) where O = out_channel, I = in_channel, h = height of kernel, w = width of kernel
你需要实现一个Stride为1, Padding为0的窄卷积操作
Y should have size (B, O, H-h+1, W-w+1)
'''
B, I, H, W = X.shape
o, _, h, w = K.shape
Y = np.zeros((B, o, H - h + 1, W - w + 1))
for i in range(Y.shape[-2]):
for j in range(Y.shape[-1]):
Y[:, :, i, j] = np.sum(np.sum(np.sum(np.repeat(np.expand_dims(X[:, :, i: i + h, j: j + w], axis = 2), repeats = o, axis = 2) * np.transpose(np.reshape(K, (1, o, I, h, w)), (0, 2, 1, 3, 4)), -1), -1), 1)
return Y
class MaxPool2D(nn.Module):
def __init__(self, pool_size):
super(MaxPool2D, self).__init__()
self.pool_size = pool_size
def forward_np(self, X):
'''
X --> (B, I, H, W) where B = batch size, I = in_channel, H = height of feature map, W = width of feature map
K --> (h, w) where h = height of kernel, w = width of kernel
你需要利用以上pool_size实现一个汇聚层的前向传播, 汇聚层的子区域间无覆盖
Y should have size (B, I, H/h, W/w)
'''
B, I, H, W = X.shape
p_h, p_w = self.pool_size
Y = np.zeros((B, I, int(H/p_h), int(W/p_w)))
for i in range(Y.shape[-2]):
for j in range(Y.shape[-1]):
Y[:, :, i, j] = np.amax(np.amax(X[:, :, i*p_h: (i+1)*p_h, j*p_w: (j+1)*p_w], -1), -1)
return Y
class linear(nn.Module):
def __init__(self, num_outputs, num_inputs):
super(linear, self).__init__()
self.weight = np.random.randn(num_inputs, num_outputs)
self.bias = np.random.randn(num_outputs)
def forward_np(self, X):
'''
X --> (B, I, H, W) where B = batch size, I = in_channel, H = height of feature map, W = width of feature map
你需要利用以上初始化的参数weight和bias实现一个卷积层的前向传播
Y should have size (B, O, H-h+1, W-w+1)
'''
Y = np.matmul(X, np.transpose(self.weight)) + np.expand_dims(self.bias, axis=0)
return Y
lab6¶
1.熟悉文本生成任务的流程
2.补全rnn_hard_version.py 文件中的基于GRU的歌词预测模型
• 根据提示,补全基于GRU的歌词预测模型代码
• 利用设定好的输入完成GRU的前向传播和歌词预测模型主体
• 正确定义和初始化GRU中的参数
• 不能调用其他工具包,不能调用pytorch内置的GRU模块,只能在“to do”下面书写代码
• 提交之后,测试集上的准确率应该降到一个正确的范围内可多次提交。即使对自己的代码没有自信也一定要提交,我们会酌情给过程分
• TO DO: 完成《Recurrent Neural Network》项目。补全rnn_hard_version.py文件使exercise_rnn.py文件中的train_with_RNN_hard()可以顺利执行。
Note:为了测试方便,这里我们使用准确率作为我们的生成评估标准。实际生成任务一般采用BLEU,Rouge等
class Sequence_Modeling(nn.Module):
def __init__(self, vocab_size, embedding_size, num_outputs, hidden_size):
super(Sequence_Modeling, self).__init__()
self.emb_layer = nn.Embedding(vocab_size, embedding_size)
self.gru_layer = GRU(embedding_size, hidden_size)
self.linear = nn.Linear(hidden_size, num_outputs)
def forward(self, sent, state):
'''
sent --> (B, S) where B = batch size, S = sequence length
sent_emb --> (B, S, I) where B = batch size, S = sequence length, I = num_inputs
state --> (B, 1, H), where B = batch_size, num_hiddens
你需要利用定义好的emb_layer, gru_layer和linear,
补全代码实现歌词预测功能,
sent_outputs的大小应为(B, S, O) where O = num_outputs, state的大小应为(B, 1, H)
'''
sent_emb = self.emb_layer(sent)
sent_hidden, state = self.gru_layer(sent_emb, state)
sent_states = self.linear(sent_hidden)
return sent_states, state
def forward(self, inputs, state):
'''
补全GRU的前向传播,
不能调用pytorch中内置的GRU函数及操作
'''
H = state
outputs = []
for i in range(inputs.size(1)):
Z = torch.sigmoid(torch.matmul(inputs[:, i, :], self.W_xz) + torch.matmul(H, self.W_hz) + self.b_z)
R = torch.sigmoid(torch.matmul(inputs[:, i, :], self.W_xr) + torch.matmul(H, self.W_hr) + self.b_r)
H_tilda = torch.tanh(torch.matmul(inputs[:, i, :], self.W_xh) + torch.matmul(R * H, self.W_hh) + self.b_h)
H = Z * H + (1 - Z) * H_tilda
outputs.append(H)
outputs = torch.cat(outputs, 0)
return outputs.transpose(1, 0), H
扣分点:状态更新出错
def forward(self, inputs, H):
'''
利用定义好的参数补全GRU的前向传播,
不能调用pytorch中内置的GRU函数及操作
'''
# ==========
# todo '''请补全GRU网络前向传播'''
outputs=[]
for X in inputs:
z_t = torch.sigmoid(X @ self.Wz + H @ self.Uz + self.bz)
r_t = torch.sigmoid(X @ self.Wr + H @ self.Ur + self.br)
h_tilde_t = torch.tanh(X @ self.Wh + (r_t * H) @ self.Uh + self.bh)
H_new = z_t * H + (1 - z_t) * h_tilde_t
outputs.append(H.unsqueeze(0))
outputs = torch.cat(outputs,dim=0)
# ==========
return outputs,H_new
扣分点:循环封装方式效率低
def forward(self, inputs, H):
'''
利用定义好的参数补全GRU的前向传播,
不能调用pytorch中内置的GRU函数及操作
'''
# ==========
# todo '''请补全GRU网络前向传播'''
Z = torch.sigmoid(torch.matmul(inputs[:, i, :], self.W_xz) + torch.matmul(H, self.W_hz) + self.b_z)
R = torch.sigmoid(torch.matmul(inputs[:, i, :], self.W_xr) + torch.matmul(H, self.W_hr) + self.b_r)
H_tilda = torch.tanh(torch.matmul(inputs[:, i, :], self.W_xh) + torch.matmul(R * H, self.W_hh) + self.b_h)
H_new = Z * H + (1 - Z) * H_tilde
return H_new
def forward(self, sent, state):
'''
sent --> (B, S) where B = batch size, S = sequence length
sent_emb --> (B, S, I) where B = batch size, S = sequence length, I = num_inputs
state --> (B, 1, H), where B = batch_size, num_hiddens
你需要利用定义好的emb_layer, gru_layer和linear,
补全代码实现歌词预测功能,
sent_outputs的大小应为(B, S, O) where O = num_outputs, state的大小应为(B, 1, H)
'''
sent_emb = self.emb_layer(sent)
# ==========
# todo '''请补全代码'''
sent_outputs = []
for i in range(sent_emb.size(1)):
input_emb = sent_emb[:, i, :] # (B, I)
state = self.gru_layer(input_emb, state.squeeze(0))
output = self.linear(state)
sent_outputs.append(output.unsqueeze(1))
lab8¶
1.熟悉用编码器-解码器的框架解决序列逆置任务的流程
2.补全rnn_with_atten.py文件中的融合注意力机制的RNN模型
• 根据提示,补全融合注意力机制的解码器代码,实现序列逆置任务
• 利用设定好的输入完成要求的RNN with attention模型
• 所有预设的网络层都应当用到
• 不能修改给定的对象属性,不能调用其他工具包,只能在“to do”下面书写代码,可以调试超参数
• 提交之后,测试集上的准确率应该提升到一个正确的范围内
• 可多次提交。即使对自己的代码没有自信也一定要提交,我们会酌情给过程分
• 本次Lab在截止日期之前将不公开榜单
• TO DO: 完成《Attention Mechanism》项目。补全rnn_with_atten.py文件使exercise_reverse_sequence.py文件中的train_with_RNN()可以顺利执行。
• 输入一个序列要求模型输出序列的逆置
• 如:输入“ABCDEFG”, 输出“GFEDCBA”
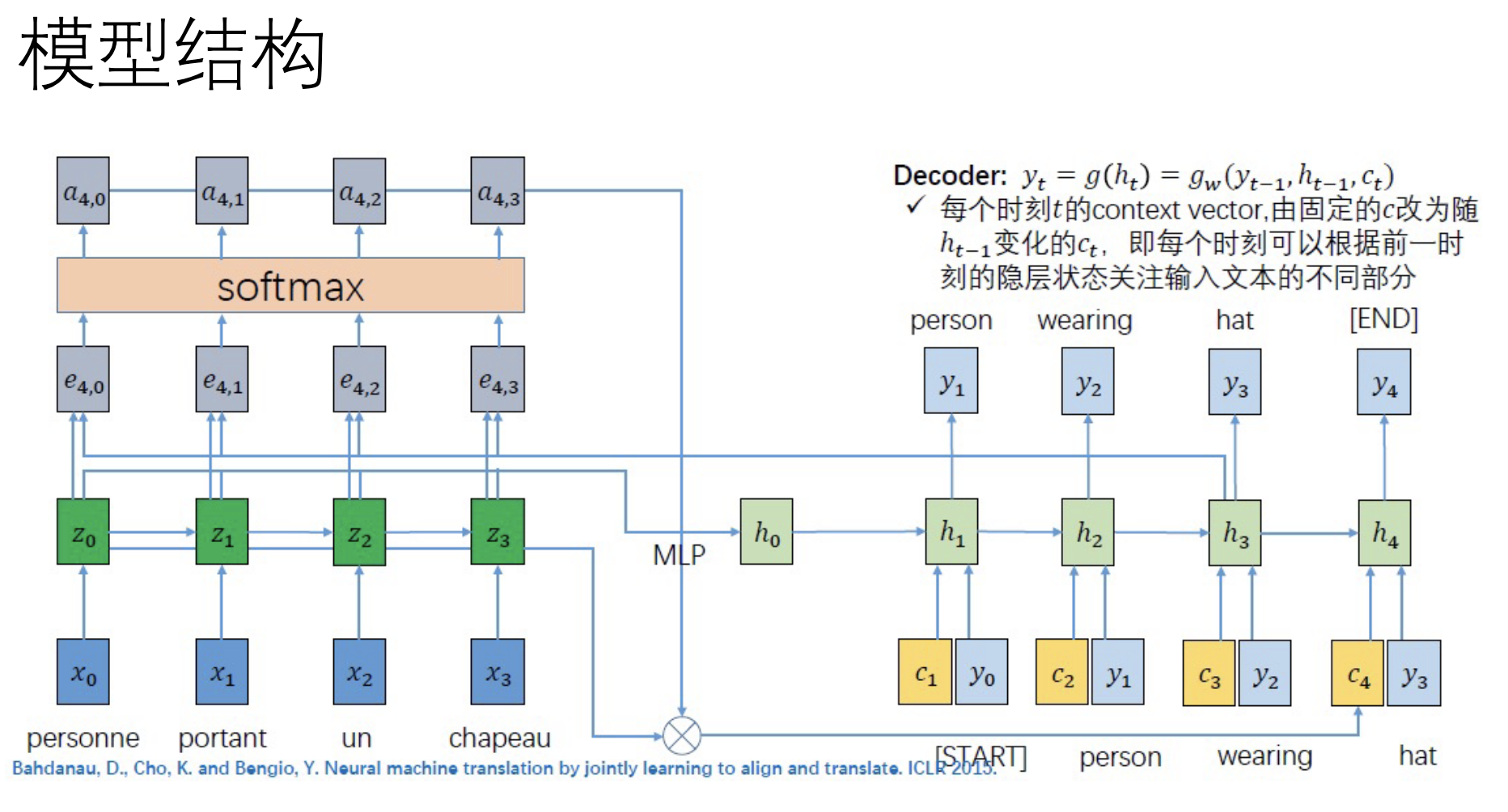
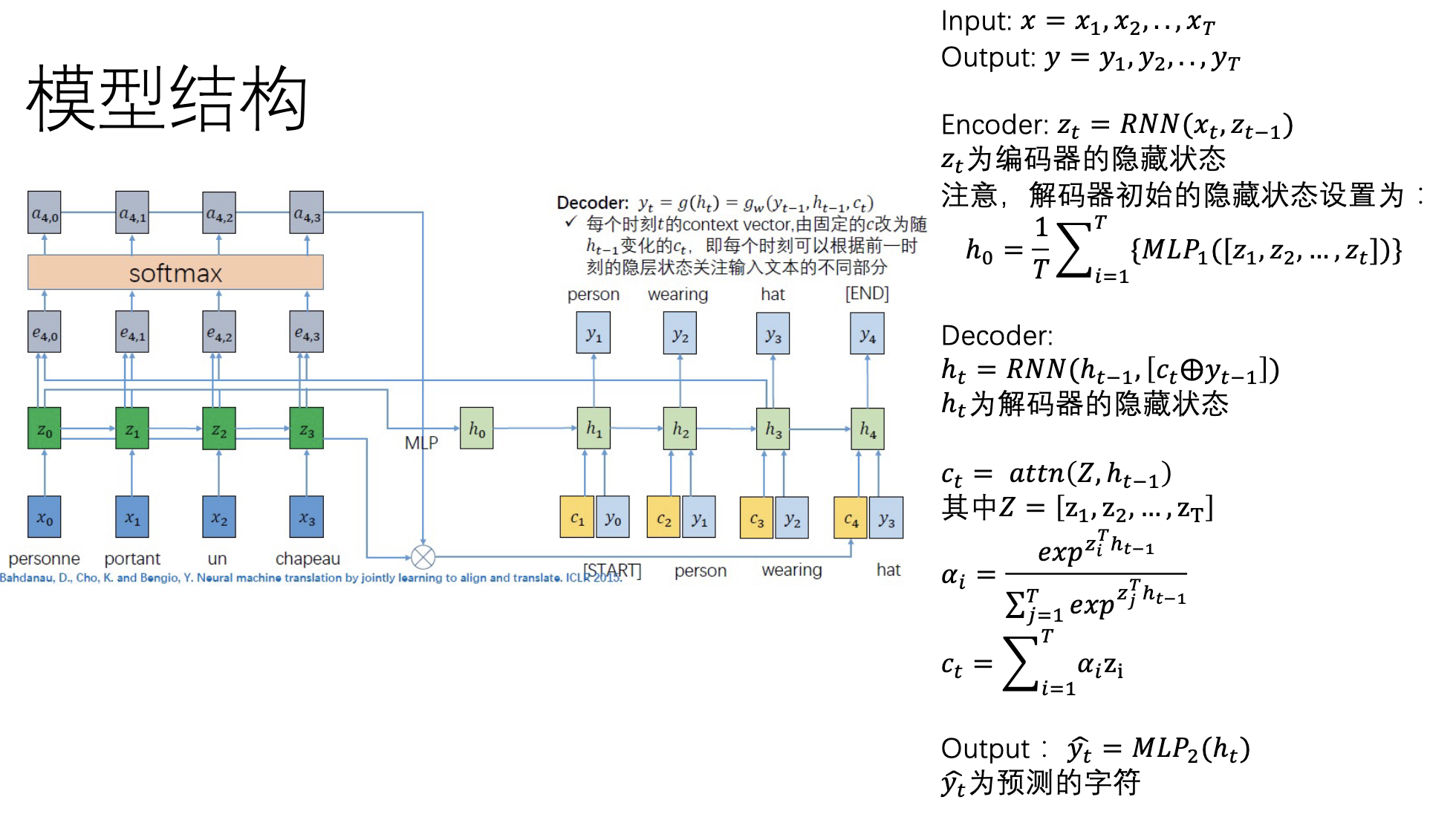
标准答案
def decode(self, dec_y, enc_hidden, state, is_first_step = True):
dec_embs = self.emb_layer(dec_y)
trg_len = dec_y.shape[1]
outputs = []
if is_first_step:
state = self.mlp1(enc_hidden).mean(1).unsqueeze(1)
# print(state.shape)
else:
state = state.transpose(1, 0)
for t in range(trg_len):
scores = torch.bmm(state, enc_hidden.transpose(2, 1))
# 计算attention weights
alpha = self.softmax(scores) # (batch_size, 1, seq_len)
# 计算context vector
cont_vec = torch.bmm(alpha, enc_hidden).squeeze(1)
input_vec = torch.cat([cont_vec, dec_embs[:, t, :]], 1).unsqueeze(1)
sent_hidden, state = self.decoder(input_vec, state.transpose(0, 1))
state = state.transpose(0, 1)
# 输出预测字符
pred = self.mlp2(sent_hidden)
outputs += [pred]
sent_outputs = torch.cat(outputs, dim = 1)
return sent_outputs, state
扣分点:decoder初始状态计算失误
- decoder 初始状态错误地只用encoder最后一个时间步的输出作为初始状态,忽略了题目中要求的对所有encoder 输出的平均
query = state.transpose(0, 1)
if t == 0 and is_first_step:
query = enc_hidden[:, -1, :] #第一步用编码器的最后隐藏状态
else:
query = state.squeeze(0) #后续步骤使用当前的隐藏状态
- 初始状态初始化顺序错误,
mean应该作用在mlp1(enc_hidden)上而非先mean后mlp1
if is_first_step:
state = self.mlp1(enc_hidden.mean(dim=1, keepdim=True)).permute(1, 0, 2) # (1, B, H)
正确答案是先将 encoder 的所有时间步输出 enc_hidden 通过 mlp1 映射,再在时间维度上取均值:
state = self.mlp1(enc_hidden).mean(1).unsqueeze(1)
扣分点:attention机制中的key错误
错误地把 mlp1(enc_hidden) 作为key,按照题目要求的模型结构不需要额外变换,key就是 enc_hidden
keys = self.mlp1(enc_hidden)
...
scores = torch.bmm(query, keys.transpose(1, 2))
扣分点:attention机制中的query错误
错误地使用 decoder 输入作为 query,应该使用当前 decoder 的隐藏状态作为 query
# 当前时间步的解码器输入
dec_input = dec_emb[:, t, :].unsqueeze(1) # (B, 1, E)
# 计算注意力分数(点积模型)
attention_scores = torch.bmm(dec_input, enc_hidden.transpose(1, 2)) # (B, 1, S)
错误使用 mlp1 投影 query,按照题目要求的模型结构,mlp1 仅用于初始化 decoder 的初始状态,不应再用于 Attention 阶段。
query = self.mlp1(query)
扣分点:缺少基于时间步的解码循环
缺乏 for t in range(seq_len)的解码循环,而是直接将所有时间步的 decoder embedding 和 context 送入 RNN,与题目要求的解码方式不一致。
if is_first_step:
# 推理阶段,每次输入1个字符,S=1
query = dec_emb # (B, 1, E)
key = enc_hidden # (B, S_enc, H)
# 点积 attention: (B, 1, E) x (B, S_enc, E)^T -> (B, 1, S_enc)
attention_scores = torch.bmm(query, key.transpose(1, 2)) # (B, 1, S_enc)
attention_weights = self.softmax(attention_scores) # (B, 1, S_enc)
context_vector = torch.bmm(attention_weights, enc_hidden) # (B, 1, H)
dec_input = torch.cat((query, context_vector), dim=-1) # (B, 1, E+H)
else:
# 训练阶段:批量处理整个序列
B, S, E = dec_emb.size()
query = dec_emb # (B, S, E)
key = enc_hidden # (B, S, H)
attention_scores = torch.bmm(query, key.transpose(1, 2)) # (B, S, S)
attention_weights = self.softmax(attention_scores) # (B, S, S)
context_vector = torch.bmm(attention_weights, key) # (B, S, H)
dec_input = torch.cat((query, context_vector), dim=-1) # (B, S, E+H)
dec_output, state = self.decoder(dec_input, state) # (B, S, H)
sent_outputs = self.mlp2(dec_output) # (B, S, vocab_size)
return sent_outputs, state
lab9¶
1.熟悉bert流程和transformer的代码
2.补全BertModel.py文件中的自注意力层
3.有时间的同学可以尝试其他数据集自行修改代码,在bert上进行微调
• 根据提示,补全transformer中自注意力层的代码,实现完整的transformer前向传播流程
• 利用设定好的输入完成BertSelfAttention模块
• 所有预设的网络层都应当用到
• 不能修改给定的对象属性,不能调用其他工具包,只能在“to do”下面书写代码
• TO DO: 完成《Transformer 》项目。补全BertModel.py文件使文件中的BertSelfAttention模块可以顺利执行。
class BertSelfAttention(nn.Module):
def __init__(self, config):
super(BertSelfAttention, self).__init__()
if config.hidden_size % config.num_attention_heads != 0:
raise ValueError(
"The hidden size (%d) is not a multiple of the number of attention "
"heads (%d)" % (config.hidden_size, config.num_attention_heads))
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(config.hidden_size, self.all_head_size)
self.key = nn.Linear(config.hidden_size, self.all_head_size)
self.value = nn.Linear(config.hidden_size, self.all_head_size)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
def forward(self, hidden_states, attention_mask):
def transpose_for_scores(x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(*new_x_shape)
return x.permute(0, 2, 1, 3)
attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)
mixed_query_layer = self.query(hidden_states)
mixed_key_layer = self.key(hidden_states)
mixed_value_layer = self.value(hidden_states)
query_layer = transpose_for_scores(mixed_query_layer)
key_layer = transpose_for_scores(mixed_key_layer)
value_layer = transpose_for_scores(mixed_value_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
# Apply the attention mask is (precomputed for all layers in BertModel forward() function)
attention_scores = attention_scores + attention_mask
# Normalize the attention scores to probabilities.
attention_probs = nn.Softmax(dim=-1)(attention_scores)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(*new_context_layer_shape)
return context_layer