2020-2021-2-编程作业3¶
Twitter Hot Topics¶
难易程度: ** 中¶
待完成:¶
- 请在DSPPCode.flink.twitter_hot_topics中创建TwitterHotTopicsImpl, 继承TwitterHotTopics, 实现抽象方法
- 请在DSPPCode.flink.twitter_hot_topics中创建TwitterTextHandlerImpl, 继承TwitterTextHandler, 实现抽象方法
题目描述:¶
- 要求:
来自世界各地的Twitter用户们每时每刻都在发布着新的推文。往往,这些推文所讨论的话题是各不相同的,并且在讨论热度上也是有所差异的。一般来说,弄清哪些话题是热门话题有利于为用户做内容推荐。假设存在一个程序正在源源不断地采集着Twitter的推文数据,现在希望你能对这些数据进行处理,以找出英文推文中的热门话题。为了简单起见,推文中的每个英文单词被视作一个话题。当话题数大于等于4时,该话题称之为热门话题。此外,对于每个话题而言,只有其对应的英文单词具备一定的意义才会纳入热门话题。例如,对于the话题,由于the无意义,则不应纳入热门话题。为了方便判定话题是否具备一定的意义,本题提供了一份包含所有无意义单词的停词表,可通过StopWordsOperation.getStopWords方法获取。
- 输入格式
每条输入数据的格式为JSON。在每条JSON数据中,"text"字段表示用户发布的推文 ,而"lang"字段表示用户发布的推文所使用的语言。假设,某一Twitter用户发布了五条相同的英文推文,其内容均为how to use flink? i love it,则推文对应的数据格式如下所示。其中,"text"字段所对应的值为how to use flink? i love it,而"lang"字段所对应的值为en。
json
{
"created_at": "Mon Jan 1 00:00:00 +0000 1901",
"id": 0,
"id_str": "000000000000000000",
"text": "how to use flink? i love it",
"source": null,
"truncated": false,
"in_reply_to_status_id": null,
"in_reply_to_status_id_str": null,
"in_reply_to_user_id": null,
"in_reply_to_user_id_str": null,
"in_reply_to_screen_name": null,
"user": {
"id": 0,
"id_str": "0000000000",
"name": "test1",
"screen_name": "iphone",
"location": "Shanghai",
"protected": false,
"verified": false,
"followers_count": 999999,
"friends_count": 99999,
"listed_count": 999,
"favourites_count": 9999,
"statuses_count": 999,
"created_at": "Mon Jan 1 00:00:00 +0000 1901",
"utc_offset": 7200,
"time_zone": "Amsterdam",
"geo_enabled": false,
"lang": "en",
"entities": {
"hashtags": [
{
"text": "example1",
"indices": [
0,
0
]
},
{
"text": "tweet1",
"indices": [
0,
0
]
}
]
},
"contributors_enabled": false,
"is_translator": false,
"profile_background_color": "C6E2EE",
"profile_background_tile": false,
"profile_link_color": "1F98C7",
"profile_sidebar_border_color": "FFFFFF",
"profile_sidebar_fill_color": "252429",
"profile_text_color": "666666",
"profile_use_background_image": true,
"default_profile": false,
"default_profile_image": false,
"following": null,
"follow_request_sent": null,
"notifications": null
},
"geo": null,
"coordinates": null,
"place": null,
"contributors": null
}
- 输出格式
每行以元组形式输出热门话题(全部小写)以及热门话题出现的次数,并且当话题数大于等于4时即开始输出。以上述的五条推文数据为例,love这一热门话题总共出现了5次,因此会产生两次输出。
(love,4)
(love,5)
(flink,4)
(flink,5)
TwitterHotTopicsImpl¶
package DSPPCode.flink.twitter_hot_topics.impl;
import DSPPCode.flink.twitter_hot_topics.question.StopWordsOperation;
import DSPPCode.flink.twitter_hot_topics.question.TwitterHotTopics;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.util.Collector;
import java.util.List;
public class TwitterHotTopicsImpl extends TwitterHotTopics {
@Override
protected DataStream<Tuple2<String, Integer>> findHotTopics(DataStream<String> twitterText) {
twitterText.print();
DataStream<Tuple2<String, Integer>> inp = twitterText.flatMap(
new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector)
throws Exception {
String[] strs = s.split(" ");
int l = strs.length;
List<String> stop = StopWordsOperation.getStopWords();
for(int i=0;i<l;i++){
String s0 = strs[i];
s0 = s0.replace("?","").replace(".","").replace(",","").replace("!","");
// System.err.println(s0);
// while(s0.charAt(s.length()-1)>'z' || s0.charAt(s0.length()-1)<'A'){
// System.err.print(s0);
// s0 = s0.substring(0,s0.length()-1);
// }
if(stop.contains(s0))
continue;
collector.collect(new Tuple2<String, Integer>(s0, 1));
}
}
}
);
inp.print();
DataStream<Tuple2<String, Integer>> ans = inp.keyBy(0).reduce(
new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> stringIntegerTuple2,
Tuple2<String, Integer> t1) throws Exception {
System.err.println("10");
return new Tuple2<String, Integer>(stringIntegerTuple2.f0, stringIntegerTuple2.f1 + t1.f1);
}
}
).filter((tup)->tup.f1 >= HOT_TOPIC_THRESHOLD);
ans.print();
return ans;
}
}
TwitterTextHandlerImpl¶
package DSPPCode.flink.twitter_hot_topics.impl;
import DSPPCode.flink.twitter_hot_topics.question.Twitter;
import DSPPCode.flink.twitter_hot_topics.question.TwitterTextHandler;
public class TwitterTextHandlerImpl extends TwitterTextHandler {
@Override
public String map(String twitterJson) throws Exception {
Twitter twitter = fromJson(twitterJson);
if (twitter.getUser().getLang().equals("en")) {
System.err.println(twitter.getText());
return twitter.getText();
}
else return "the";
}
}
Digital Conversion¶
待完成:¶
- 请在 DSPPCode.flink.digital_conversion.impl 中创建DigitalPartitionerImpl, 继承 DigitalPartitioner, 实现抽象方法
- 请在 DSPPCode.flink.digital_conversion.impl 中创建DigitalConversionImpl, 继承 DigitalConversion, 实现抽象方法
题目描述:¶
-
有一个程序会持续地产生一些数字,这些数字都在0~9以内。小明希望将程序产生的整数转换为英文单词并进行输出。此外,小明发现这些数字均匀的分布在[0-4]和[5-9]区间内。因此,在对这些数据进行转换时,小明还希望将这些数字均匀地划分到两个任务中。
-
输入格式: 输入的每行为一个数字
0
1
2
3
4
5
6
7
8
9
- 输出格式: 每行输出数字对应的英文单词,单词的首字母要求大写。
任务1的输出
One
Three
Zero
Two
Four
任务2的输出
Five
Seven
Nine
Six
Eight
DigitalConversionImpl¶
package DSPPCode.flink.digital_conversion.impl;
import DSPPCode.flink.digital_conversion.question.DigitalConversion;
import DSPPCode.flink.digital_conversion.question.DigitalWord;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple1;
import org.apache.flink.streaming.api.datastream.DataStream;
public class DigitalConversionImpl extends DigitalConversion{
public DataStream<String> digitalConversion(DataStream<Tuple1<String>> digitals){
DataStream<String> ans = digitals.map(
new MapFunction<Tuple1<String>, String>() {
@Override
public String map(Tuple1<String> tuple1) throws Exception {
double d = Double.parseDouble(tuple1.f0);
int i = (int)d;
if (Math.abs(d - i) > 0.00001){
return "";
}
switch(i){
case 0:
return DigitalWord.ZERO.getWord();
// break;
case 1:
return DigitalWord.ONE.getWord();
// break;
case 2:
return DigitalWord.TWO.getWord();
// break;
case 3:
return DigitalWord.THREE.getWord();
// break;
case 4:
return DigitalWord.FOUR.getWord();
// break;
case 5:
return DigitalWord.FIVE.getWord();
// break;
case 6:
return DigitalWord.SIX.getWord();
// break;
case 7:
return DigitalWord.SEVEN.getWord();
// break;
case 8:
return DigitalWord.EIGHT.getWord();
// break;
case 9:
return DigitalWord.NINE.getWord();
// break;
default:
return "";
}
}
}).filter(
new FilterFunction<String>() {
@Override
public boolean filter(String s) throws Exception {
if(s != "") return true;
return false;
}
}
);
return ans;
}
}
DigitalPartitionerImpl¶
package DSPPCode.flink.digital_conversion.impl;
import DSPPCode.flink.digital_conversion.question.DigitalPartitioner;
public class DigitalPartitionerImpl extends DigitalPartitioner{
public int partition(String key, int numPartitions){
if(key.charAt(0) < '5')
return 0;
else return 1;
}
}
Email Assignment¶
待完成:¶
- 请在DSPPCode.flink.email_assignment.impl中创建EmailAssignmentImpl, 继承EmailAssignment, 实现抽象方法.
题目描述:¶
-
ECNU的教职工所使用的工作邮箱的格式为
用户名@邮箱后缀。一般而言,每个教职工可以为工作邮箱申请多个用户名作为别名。然而,由于同一学院的教职工拥有相同的邮箱后缀。例如:数据科学与工程学院的教职工的邮箱后缀都为dase.ecnu.edu.cn。因此,在申请别名时有如下规定: -
同一学院内的别名不能发生重复(如不能同时存在两个用户都拥有
a_name@dase.ecnu.edu.cn的邮箱地址)。 -
不同学院间的别名可以发生重复(如可以同时存在两个用户分别拥有
a_name@dase.ecnu.edu.cn和a_name@cs.ecnu.edu.cn的邮箱地址)。 -
此外,别名长度的取值范围是[5,11],且别名只能由英文字母、数字或下划线(_)组成。
现有一组顺序的别名申请和注销的请求序列,要求结合以上的别名申请规定得出各请求的最终完成状态(成功或者失败)。
-
输入: 答题时无需编写代码来解析输入的文本格式。需要实现的抽象方法的输入为
DataStream<Request>类型。其中每个字段的含义如下:- type: 申请(APPLY)或注销(REVOKE)。
- id: 发出请求用户的工号,每个工号只对应一个邮箱账户。
- depart: 由于邮件系统设计的原因,部门通过两位代码表示,分别为
firstLevelCode(一级部门代码,如1表示信息学部)、secondLevelCode(一级部门内的二级部门代码,如3表示数据学院)。 - alias: 请求的别名。
Request{type=APPLY, id=12345, depart=Department{firstLevelCode=1, secondLevelCode=1}, alias="*invalid"}
Request{type=APPLY, id=22222, depart=Department{firstLevelCode=1, secondLevelCode=3}, alias="a_name"}
Request{type=APPLY, id=25222, depart=Department{firstLevelCode=1, secondLevelCode=3}, alias="a_name"}
Request{type=REVOKE, id=22222, depart=Department{firstLevelCode=1, secondLevelCode=3}, alias="a_name"}
Request{type=APPLY, id=25222, depart=Department{firstLevelCode=1, secondLevelCode=3}, alias="b_name"}
- 输出:
输出每个请求的完成状态,
SUCCESS表示请求成功执行,FAILURE表示请求执行失败。
FAILURE
SUCCESS
FAILURE
SUCCESS
SUCCESS
EmailAssignmentImpl¶
package DSPPCode.flink.email_assignment.impl;
import DSPPCode.flink.email_assignment.question.EmailAssignment;
import DSPPCode.flink.email_assignment.question.Request;
import DSPPCode.flink.email_assignment.question.RequestType;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import java.util.HashMap;
public class EmailAssignmentImpl extends EmailAssignment{
@Override
public DataStream<String> processRequest(DataStream<Request> requests) {
DataStream<String> ans = requests.map(
new MapFunction<Request, String>() {
HashMap<String, Integer> hash = new HashMap<String, Integer>();
@Override
public String map(Request request) throws Exception {
String TRUE = "SUCCESS";
String FALSE = "FAILURE";
String regex = "^[a-z0-9A-Z_]+$";
if (request.getAlias().length() < 5 || request.getAlias().length() > 11) {
System.err.print("no bother ");
System.err.println(hash);
return FALSE;
}
if (!request.getAlias().matches(regex)) {
System.err.print("no bother ");
System.err.println(hash);
return FALSE;
}
Integer fi = new Integer(request.getDepart().getFirstLevelCode());
Integer se = new Integer(request.getDepart().getSecondLevelCode());
String k = fi.toString() + se.toString() + request.getAlias();
Integer rid = hash.getOrDefault(k, -1);
if (rid == -1 && request.getType() == RequestType.APPLY){
hash.put(k, request.getId());
System.err.print("go1 ");
System.err.println(hash);
return TRUE;
}
else if (rid == request.getId() && request.getType() == RequestType.REVOKE){
hash.put(k, -1);
System.err.print("go2 ");
System.err.println(hash);
return TRUE;
}
else {
System.err.print("go3 ");
System.err.println(hash);
return FALSE;
}
}
}
);
DataStream<String> test = ans.map(
new MapFunction<String, String>() {
@Override
public String map(String s) throws Exception {
System.err.println(s);
return s;
}
}
);
System.err.println("---------");
return ans;
}
}
最大公约数(GCD)¶
待完成:¶
- 请在 DSPPCode.flink.gcd.impl 中创建GCDImpl, 继承 GCD, 实现抽象方法
题目描述:¶
- 对于两个正整数,求其最大公约数(GCD)。用于计算最大公约数的辗转相除法的原理是:两个整数的最大公约数等于其中较小的那个数和两数相除余数的最大公约数,即
gcd(a, b) = gcd(b, a mod b)。此处不妨设置r = a mod b,若r != 0,则重新赋值a ← b,b ← r并继续迭代,直至r = 0,此时的b即为最大公约数。 请输出每次迭代后a和b的值。
注:请使用flink迭代算子实现。
- 输入格式: 输入由一个字符标识符以及两个整数
a,b组成的字符串记录,彼此之间使用空格分隔。字符标识符用来区分不同的记录,分别求解每个记录中两个整数a,b的最大公约数。
A 5 2
B 18 6
- 输出格式: 输出为字符标识符以及两个整数组成的元组,代表某一记录每次迭代后
a和b的值。如(A,2,1)表示A记录第一次迭代计算后a=2,b=1。
(A,2,1)
(B,6,0)
(A,1,0)
GCDImpl¶
package DSPPCode.flink.gcd.impl;
import DSPPCode.flink.gcd.question.GCD;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.IterativeStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class GCDImpl extends GCD{
public DataStream<Tuple3<String, Integer, Integer>> calGCD(IterativeStream<Tuple3<String, Integer, Integer>> iteration){
// |创建反馈流|
// |选择第三位置不为0的元组,例如(A, 2, 1)|
DataStream<Tuple3<String, Integer, Integer>> feedback =
iteration.filter(
new FilterFunction<Tuple3<String, Integer, Integer>>() {
@Override
public boolean filter(Tuple3<String, Integer, Integer> value) throws Exception {
return value.f2 != 0;
}
});
// |实现迭代步逻辑,计算下一个GCD|
DataStream<Tuple3<String, Integer, Integer>> iteratedStream =
feedback.flatMap(
new FlatMapFunction<Tuple3<String, Integer, Integer>, Tuple3<String, Integer, Integer>>() {
@Override
public void flatMap(
Tuple3<String, Integer, Integer> value, Collector<Tuple3<String, Integer, Integer>> out)
throws Exception {
// |例如迭代算子的输入输入为(A, 2, 1),此处转换将(A, 2, 1)转换为(A, 1, 0)|
Tuple3<String, Integer, Integer> feedbackValue =
new Tuple3(value.f0, value.f2, value.f1 % value.f2);
out.collect(feedbackValue);
}
});
iteration.closeWith(iteratedStream);
return iteratedStream;
}
}
Grade Point¶
待完成:¶
- 请在DSPPCode.flink.grade_point.impl中创建GradePointImpl, 继承GradePoint, 实现抽象方法.
题目描述:¶
-
数据学院开设了若干门公选课,每门课的学分均在1-5范围内,学生可以选择自己感兴趣的公选课进行修读,根据毕业要求,学生选修的公选课的总学分需要达到10分。 假设每个学生都满足了毕业要求,并且所有公选课的成绩均已公布,现在需要你根据成绩单和下图的公式来计算所有学生的平均学分绩点,计算结果四舍五入保留两位小数。
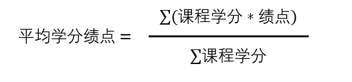
注: 1.学生的某个选修课成绩若为-1,表示该学生并未参加该选修课的考试。此时,该选修课的成绩应按0分计算。
-
输入:每行表示一个学生选修的某课程的成绩信息,该信息包括三个字段(学生id 课程学分 课程绩点),各字段之间使用空格进行分隔。
t001 3 3.6
t001 3 3.5
t001 4 3.0
t002 3 3.0
t002 3 4.0
t002 4 4.0
t003 3 2.7
t003 3 3.4
t003 4 3.5
- 输出:计算每个学生的平均学分绩点,和总学分一起输出。
输出格式为(学生id,总学分,平均学分绩点)
例:学生t001的总学分=3+3+4=10,平均学分绩点=(33.6+33.5+4*3.0)/10=3.33,则学生t001对应的输出为(t001,10,3.33)。
(t001,10,3.33)
(t002,10,3.7)
(t003,10,3.23)
GradePointImpl¶
package DSPPCode.flink.grade_point.impl;
import DSPPCode.flink.grade_point.question.*;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.util.Collector;
import javax.xml.crypto.Data;
import java.math.BigDecimal;
public class GradePointImpl extends GradePoint{
@Override
public DataStream<Tuple3<String, Integer, Float>> calculate(DataStream<String> text) {
// 将成绩信息映射为 [stu id,学分,成绩]
DataStream<Tuple3<String,Integer,Float>> points = text.map(
new MapFunction<String, Tuple3<String, Integer, Float>>() {
@Override
public Tuple3<String, Integer, Float> map(String value) throws Exception {
String[] infos = value.split(" ");
float point = Float.parseFloat(infos[2]);
if (point >= 0 && point<=5){
return new Tuple3<>(infos[0],Integer.parseInt(infos[1]),point);
}
// 若成绩为-1,表示成绩异常,计为0分
return new Tuple3<>(infos[0],Integer.parseInt(infos[1]),point+1);
}
});
DataStream<Tuple3<String,Integer,Float>> pointGroupByKey = points
.keyBy(0)
.reduce(new ReduceFunction<Tuple3<String, Integer, Float>>() {
@Override
public Tuple3<String, Integer, Float> reduce(Tuple3<String, Integer, Float> preRecord,
Tuple3<String, Integer, Float> currRecord) throws Exception {
float temp_pre_course = preRecord.f1*preRecord.f2;
float temp_cur_course = currRecord.f1*currRecord.f2;
float raw_grade_point = (temp_pre_course+temp_cur_course)/(preRecord.f1+ currRecord.f1);
return Tuple3.of(preRecord.f0,preRecord.f1+currRecord.f1, (float)(Math.round(raw_grade_point*10))/10
// 先Math.round四舍五入掉小数点后第二位,然后再/10变成绩点
);
}
});
// pointGroupByKey.print();
DataStream<Tuple3<String,Integer,Float>> result = pointGroupByKey
.filter(value -> value.f1 == 10);
// result.print();
return result;
}
}
区间测速(Speed Measurement)¶
待完成:¶
- 请在 DSPPCode.flink.speed_measurement.impl 中创建SpeedKeyedProcessFunctionImpl, 继承 SpeedKeyedProcessFunction, 实现抽象方法
题目描述:¶
-
为了保障交通安全,从A入口到B出口的路段(全程路长10km)开始实行区间测速制度,该制度的具体规则如下:
-
A入口处和B出口处各设有1个摄像头,摄像头会记录下每一辆车驶入A入口的时刻和驶出B出口的时刻。要求车辆从A行驶到B的平均速度不能超过60km/h。
- 此外,A到B的区间内又额外设置了2个测速点,这2个测速点各安装了1个摄像头,摄像头会记录下每辆车经过测速点处时的车牌和速度。要求车辆在途中2个测速点处的车速也不能超过60km/h。
现给定上述4个摄像头的数据,请统计出超速的车辆。
- 输入格式: 每行包含一个车牌号和一个时刻,以空格分隔(例如,下表第1行包含一个车牌号00001和一个时刻10:00:00),或者每行包含一个车牌号和一个速度(例如,下表第2行包含一个车牌号00001和一个速度58km/h)。
00001 10:00:00
00001 58
00001 59
00001 10:12:00
00002 10:15:00
00002 55
00002 66
00002 10:27:00
- 输出格式: 输出超速的车牌号。
00002
SpeedKeyedProcessFunctionImpl¶
package DSPPCode.flink.speed_measurement.impl;
import DSPPCode.flink.speed_measurement.question.SpeedMeasurement;
import DSPPCode.flink.speed_measurement.question.SpeedKeyedProcessFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.util.Collector;
public class SpeedKeyedProcessFunctionImpl extends SpeedKeyedProcessFunction{
@Override
public void open(Configuration parameters) throws Exception {
}
private String[] avt = null;
private String car = null;
@Override
public void processElement(Tuple2<String, String> t, Context context, Collector<String> collector)
throws Exception {
if(car == context.getCurrentKey()) return;
if(t.f1.contains(":")) {
if(avt == null) {
avt = new String[2];
avt[0] = t.f1;
} else {
avt[1] = t.f1;
if(averageSpeed(avt) > 60.0f) {
car = context.getCurrentKey();
collector.collect(car);
}
}
} else {
float speed = Float.valueOf(t.f1);
if(speed > 60.0f) {
car = context.getCurrentKey();
collector.collect(car);
}
}
}
@Override
public float averageSpeed(String[] times) {
String[] t1 = times[0].split(":");
String[] t2 = times[1].split(":");
int h1 = Integer.valueOf(t1[0]), m1 = Integer.valueOf(t1[1]), s1 = Integer.valueOf(t1[2]);
int h2 = Integer.valueOf(t2[0]), m2 = Integer.valueOf(t2[1]), s2 = Integer.valueOf(t2[2]);
return 36000.0f / (((h2 - h1) * 60 + m2 - m1) * 60 + s2 - s1);
}
}
Water Problem¶
待完成:¶
- 请在DSPPCode.flink.water_problem.impl中创建WaterProblemImpl, 继承WaterProblem, 实现抽象方法。 可以参考基于 DataStream API 实现欺诈检测
题目描述:¶
- 有若干个泳池,每个泳池各有一条管道与外界相连。 管道中有水流通过,引起泳池水量的变化。
假设泳池最初是空的,泳池容积无限大。
泳池管理员时常调节管道中水流的速度,来控制泳池的水量,管理员也时常查看泳池的具体水量。
现给出一个包含操作事件和查询事件的流, 请输出每次查询时对应的泳池的水量。
- 输入:
输入数据的格式为(isQuery,poolId,timestamp,speed)。
isQuery的取值是true或者false,如果是true请输出水量,如果是false请修改水流速度。
poolId是一个整数,取值范围是[0,10],表示查询或者修改的那个泳池的编号。
timestamp是一个整数,取值范围是[0,2000],表示查询或者修改事件发生的时刻,输入数据保证timestamp是非降序的。
speed是一个整数,取值在int范围内。如果isQuery是false,表示把对应泳池管道的速度修改到speed;如果isQuery是true,请忽略这个字段。
false,1,0,10
false,2,0,20
true,1,5,0
true,2,5,0
false,1,10,100
false,2,10,0
true,1,20,0
true,2,20,0
- 输出:
对每次查询事件请输出当时对应泳池的水量,输出格式为(poolId,timestamp,volume)。
1,5,50
2,5,100
1,20,1100
2,20,200
- 样例解释
在t=0时,把1号泳池的流速修改到10,把2号泳池的流速修改到20。
在t=5时,查询1号和2号泳池的水量。此时,1号泳池的水量是 10*5=50 ,2号泳池的水量是
20*5=100 ,所以输出(1,5,50)和(2,5,100)。
在t=10时,把1号泳池的流速修改到100,把2号泳池的流速修改到0。
在t=20时,查询1号和2号泳池的水量。此时,1号泳池的水量是 10*10+100*10=1100 ,2号泳池的水量是
20*10+0*10=200 ,所以输出(1,20,1100)和(2,20,200)。
WaterProblemImpl¶
package DSPPCode.flink.water_problem.impl;
import DSPPCode.flink.water_problem.question.WaterProblem;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.util.Collector;
import java.math.BigInteger;
import org.apache.flink.api.java.tuple.Tuple4;
public class WaterProblemImpl extends WaterProblem {
@Override
public DataStream<String> execute(DataStream<String> dataStream) {
DataStream<Tuple4<Boolean, Long, Long, Long>> input = dataStream.map(
new MapFunction<String, Tuple4<Boolean, Long, Long, Long>>() {
@Override
public Tuple4<Boolean, Long, Long, Long> map(String s) throws Exception {
// System.err.println(s);
String[] ns = s.split(",");
Boolean b = false;
if (ns[0].equals("true"))
b = true;
Tuple4<Boolean, Long, Long, Long> ret = new Tuple4<Boolean, Long, Long, Long>
(b, Long.parseLong(ns[1]), Long.parseLong(ns[2]), Long.parseLong(ns[3]));
return ret;
}
}
);
DataStream<Tuple4<Boolean, Long, Long, Long>> cal = input.keyBy(1).flatMap(
new FlatMapFunction<Tuple4<Boolean, Long, Long, Long>, Tuple4<Boolean, Long, Long, Long>>() {
long[] line = new long[]{0, 0, 0, 0, 0, 0, 0, 0, 0, 0};
long[] speed = new long[]{0, 0, 0, 0, 0, 0, 0, 0, 0, 0};
long[] lasttime = new long[]{0, 0, 0, 0, 0, 0, 0, 0, 0, 0};
@Override
public void flatMap(
Tuple4<Boolean, Long, Long, Long> tuple4,
Collector<Tuple4<Boolean, Long, Long, Long>> collector) throws Exception {
int p = tuple4.f1.intValue();
if(tuple4.f0){
Tuple4<Boolean, Long, Long, Long> col = new Tuple4<Boolean, Long, Long, Long>(true,
tuple4.f1, tuple4.f2,
(line[p] + (tuple4.f2 - lasttime[p]) * speed[p]) >= 0 ? (line[p] + (tuple4.f2 - lasttime[p]) * speed[p]) : 0);
collector.collect(col);
} else {
line[p] += (tuple4.f2 - lasttime[p]) * speed[p];
if (line[p] < 0)
line[p] = 0;
speed[p] = tuple4.f3;
lasttime[p] = tuple4.f2;
}
System.err.print(p);
System.err.print(' ');
System.err.print(line[p]);
System.err.print(' ');
System.err.print(speed[p]);
System.err.print(' ');
System.err.println(lasttime[p]);
}
}
);
DataStream<String> ans = cal.map(
new MapFunction<Tuple4<Boolean, Long, Long, Long>, String>() {
@Override
public String map(Tuple4<Boolean, Long, Long, Long> tuple4)
throws Exception {
return tuple4.f1.toString() + "," + tuple4.f2.toString() + "," + tuple4.f3.toString();
}
}
);
System.err.println("--------------");
ans.print();
return ans;
}
}