操作系统实验报告4¶
实验材料¶
一、实验目的¶
- 优化block cache争用
- 改进 xv6 操作系统的缓冲区缓存(buffer cache),以减少在多进程频繁使用文件系统时对 bcache.lock的争用。
二、实验内容¶
任务解读¶
本次实验要求利用Hash思想改进bcache的结构。
在原实验中,我们采用的是双向链表管理block cache,并且全部进程去争夺一把大锁bcache.lock。这样做固然安全,但是会造成程序在多线程频繁使用文件系统时,对bcache.lock形成争用。因此,我们需要把这种竞争改变,具体是通过改进操作系统的缓冲区缓存完成的:
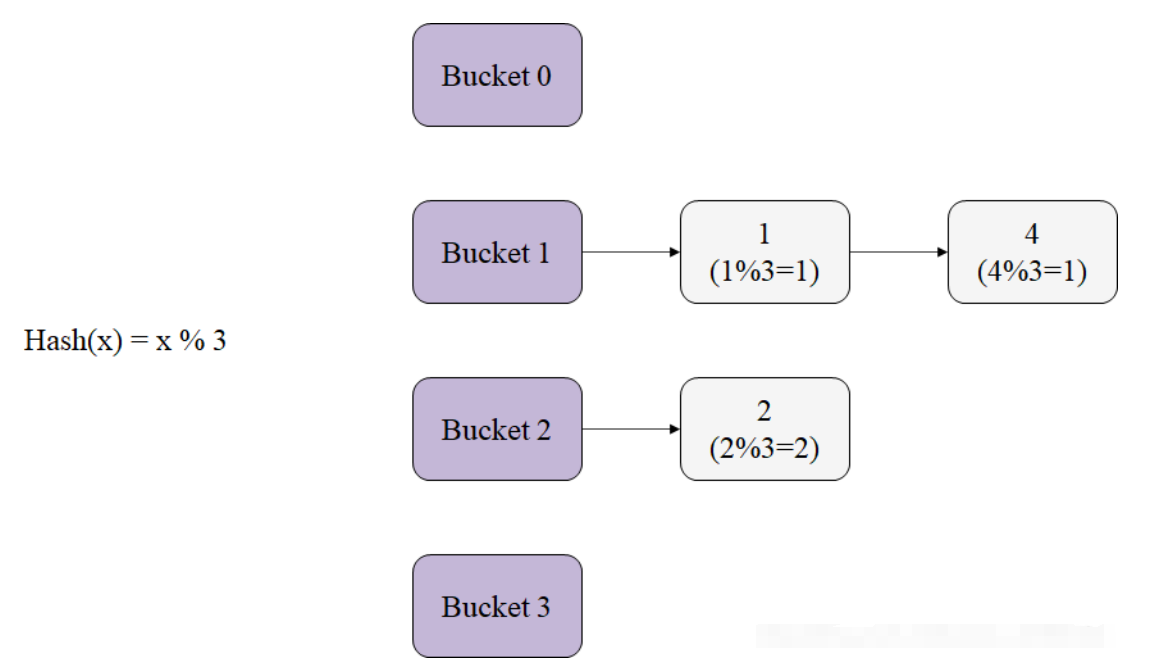
可以看到,我们放弃了双链表的管理方式,利用hash bucket的思想去修改了缓冲区缓存。总地来说是这样的:我们在缓存中通过块号blockno查找块应该属于的Bucket(下文称桶),接下来遍历这个桶内的锁,并按照一定规则获得锁:
- 如果有空闲的锁,分配给它;
- 没有空闲的锁,但是有近期没有使用的锁,则回收后再分配;
- 不满足上述条件,则找到上次使用的时间戳最小(LRU策略)的锁,回收后再分配。
为了满足这些要求,我们需要在buf(用于描述缓冲区的结构体)中添加timestamp,从而实现基于时间戳的LRU策略。同时,这个buf中还需要加入它属于的桶的索引,使定位更简便。
struct buf {
int valid; // has data been read from disk?
int disk; // does disk "own" buf?
uint dev;
uint blockno;
struct sleeplock lock;
uint refcnt;
struct buf *prev; // LRU cache list
struct buf *next;
uchar data[BSIZE];
uint timestamp; // 基于时间戳的LRU
uint hashnumber; // 也就是该缓冲区属于的桶的索引
};
注意到哈希表中的每个哈希桶都有一个自旋锁,这相当于分散了线程对锁的争用;而每个缓冲区也存在各自的睡眠锁(struct sleeplock)。
补充说明,睡眠锁就是当线程无法获得锁时,让线程进入睡眠状态。
锁的初始化和争用次数记录¶
按照实验手册对源代码进行修改。
修改buf结构体的原因已经在上文说明,接下来需要进入bio.c中修改代码逻辑。
- 首先,添加哈希表定义。
#define BUCKETSIZE 13 // number of hashing buckets
#define BUFFERSIZE 5 // number of available buckets per bucket
这个定义说明,我们将要使用的表是13*5的规模,也就是说有13个桶,每个桶有5个锁。
- 接下来,声明ticks。ticks在trap.c中有所声明。
- 修改结构体bcache为bachebucket。
struct {
struct spinlock lock;
struct buf buf[BUFFERSIZE];
} bcachebucket[BUCKETSIZE];
这一步中的spinlock(自旋锁)也在trap.c中有声明。同时,声明了大小为BUFFERSIZE=5的缓冲区,以及名为bcachebucket,大小为BUCKETSIZE=13的结构体数组(实际上就是哈希表)。
- 修改binit函数
binit(void)
{
struct buf *b;
for (int i = 0; i < BUCKETSIZE; i++){
initlock(&bcachebucket[i].lock, "bcache");
for (b = bcachebucket[i].buf; b < bcachebucket[i].buf + BUFFERSIZE; b++){
initsleeplock(&b->lock, "buffer");
b->timestamp = 0;
b->hashnumber = i;
}
}
// Create linked list of buffers
}
这一段的代码逻辑相较于之前的双向链表变动较大。首先,我们声明了一个用于指示的buf指针b。
接下来,遍历13个桶。对每一个桶的自旋锁进行初始化。在初始化锁的时候,需要指出锁的地址(&bcachebucket[i].lock),同时给出这个锁的名字(此处为"bacache")。
在任意一个桶中,需要借助上文声明的b遍历所有的缓冲区,并且把缓冲区(buf)的睡眠锁初始化。同时,需要将缓冲区的时间戳初始化为0(说明这是程序一开始就有的,没有使用过),同时记录该缓冲区所属的桶。
最后,删去所有和双向链表有关的代码。
- 修改bpin和bunpin函数。
这两个函数用于确定缓冲区的锁的征用次数。修改逻辑也很简单,替换锁的位置即可:
void
bpin(struct buf *b) {
acquire(&bcachebucket[b->hashnumber].lock); // Teacher yu told me
b->refcnt++;
release(&bcachebucket[b->hashnumber].lock);
}
void
bunpin(struct buf *b) {
acquire(&bcachebucket[b->hashnumber].lock);
b->refcnt--;
release(&bcachebucket[b->hashnumber].lock);
}
因为这个是原子化操作,因此需要先获得该缓存所在桶的自旋锁。注意到桶地址的确定需要借助缓冲区存储的序号b->hashnumber。
修改锁的获取与释放逻辑¶
- 首先修改锁的获取逻辑,即bget()函数。
static struct buf* bget(uint dev, uint blockno);
首先,这个函数传入的参数有两个,dev和blockno。其中dev是用来跟踪每个缓冲区所关联的存储设备的无符号整数,与本实验关系不大;重要的是blockno,这用于确定缓存区的块号。
接下来,我们逐步解析代码。
struct buf *b;
int hash_place = blockno % BUCKETSIZE;
acquire(&bcachebucket[hash_place].lock);
// Is the block already cached?
for(b = bcachebucket[hash_place].buf; b < bcachebucket[hash_place].buf + BUFFERSIZE; b++){
if(b->dev == dev && b->blockno == blockno){
b->refcnt++;
b->timestamp = ticks; // last used
release(&bcachebucket[hash_place].lock);
acquiresleep(&b->lock);
return b;
}
}
-
根据块号,我们确定hash_place,也就是需要分配到的桶号。接下来,获得这个桶的锁,确保程序安全;
-
进入桶中,开始就桶中的缓冲区进行第一次遍历:在一个哈希表(缓存桶)中搜索给定设备和块号的缓存块,即探索该块是否已经缓存。
-
如果已经缓存,那么就进行下述操作:
-
增加缓存块的征用次数;
- 将该缓存块的调用时间改为当前的时间戳;
- 释放桶的锁;
- 获得这个块的睡眠锁;
- 返回这个缓存块;
c
for(b = bcachebucket[hash_place].buf; b < bcachebucket[hash_place].buf + BUFFERSIZE; b++){
if(b->refcnt == 0) {
b->dev = dev;
b->blockno = blockno;
b->valid = 0;
b->refcnt = 1;
release(&bcachebucket[hash_place].lock);
acquiresleep(&b->lock);
return b;
}
}
-
如果这个块没有缓存,那么进入第二次遍历:探索是否有块的引用次数为0。如果有,则进行以下操作:
-
将这个块的存储设备更改为当前设备;
- 将这个块的块号改为当前块号;
- 使这个块的有效值为0(即不再可用,不空闲);
- 征用次数设定为1;
- 释放桶的锁,然后获得这个块的睡眠锁,并返回这个块;
```c
// Not chched and no refcnt is 0.
// find the smallest timestamp and replace it.
uint smallest = ticks+100000;
struct buf* b_smallest = 0;
for(b = bcachebucket[hash_place].buf; b < bcachebucket[hash_place].buf + BUFFERSIZE; b++){
if (b->timestamp <= smallest){
smallest = b->timestamp;
b_smallest = b;
}
}
if (smallest != ticks+100000){
b_smallest->dev = dev;
b_smallest->blockno = blockno;
b_smallest->valid = 0;
b_smallest->refcnt = 1;
release(&bcachebucket[hash_place].lock);
acquiresleep(&b_smallest->lock);
return b_smallest;
}
```
-
如果也没有引用次数为0的块,那么就进入第三次遍历:征用最早使用的块。首先初始化最小时间戳为当前时间戳+10000,确保这个值一定会被替换;再遍历所有的缓冲区,找到最小的那个时间戳对应的缓冲区。
-
接下来,沿用第二次遍历的代码逻辑,将缓冲区进行初始化。
-
最后,如果仍然没有对应的值,说明出现了一定的问题,需要抛出异常:
c
panic("bget: no buffers");
}
至此,缓冲区锁的获取就完成了。
接下来,开始进行锁的释放,即对brelse进行部分修改。
void
brelse(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("brelse");
releasesleep(&b->lock);
int hash_place = b->hashnumber;
acquire(&bcachebucket[hash_place].lock);
b->refcnt--;
if (b->refcnt == 0) {
// no one is waiting for it.
// b->next->prev = b->prev;
// b->prev->next = b->next;
// b->next = bcache.head.next;
// b->prev = &bcache.head;
// bcache.head.next->prev = b;
// bcache.head.next = b;
b->timestamp = ticks;
}
release(&bcachebucket[hash_place].lock);
}
首先还是获得需要释放的缓冲区的桶序号,然后获得该桶的锁,确保后续程序安全;接下啦,减少该缓冲区的一次引用记录,并且如果该缓冲区不再被人引用,则将这个缓冲区的最后一次使用时间的时间戳修改为当前时间戳。最后释放桶的自旋锁。
注意到这个函数的修改程度并不大,只需要把所有和双链表有关的内容全部注释掉即可。
三、使用环境¶
ubuntu虚拟机中的xv6系统。
四、实验过程及成果¶
实验结果¶
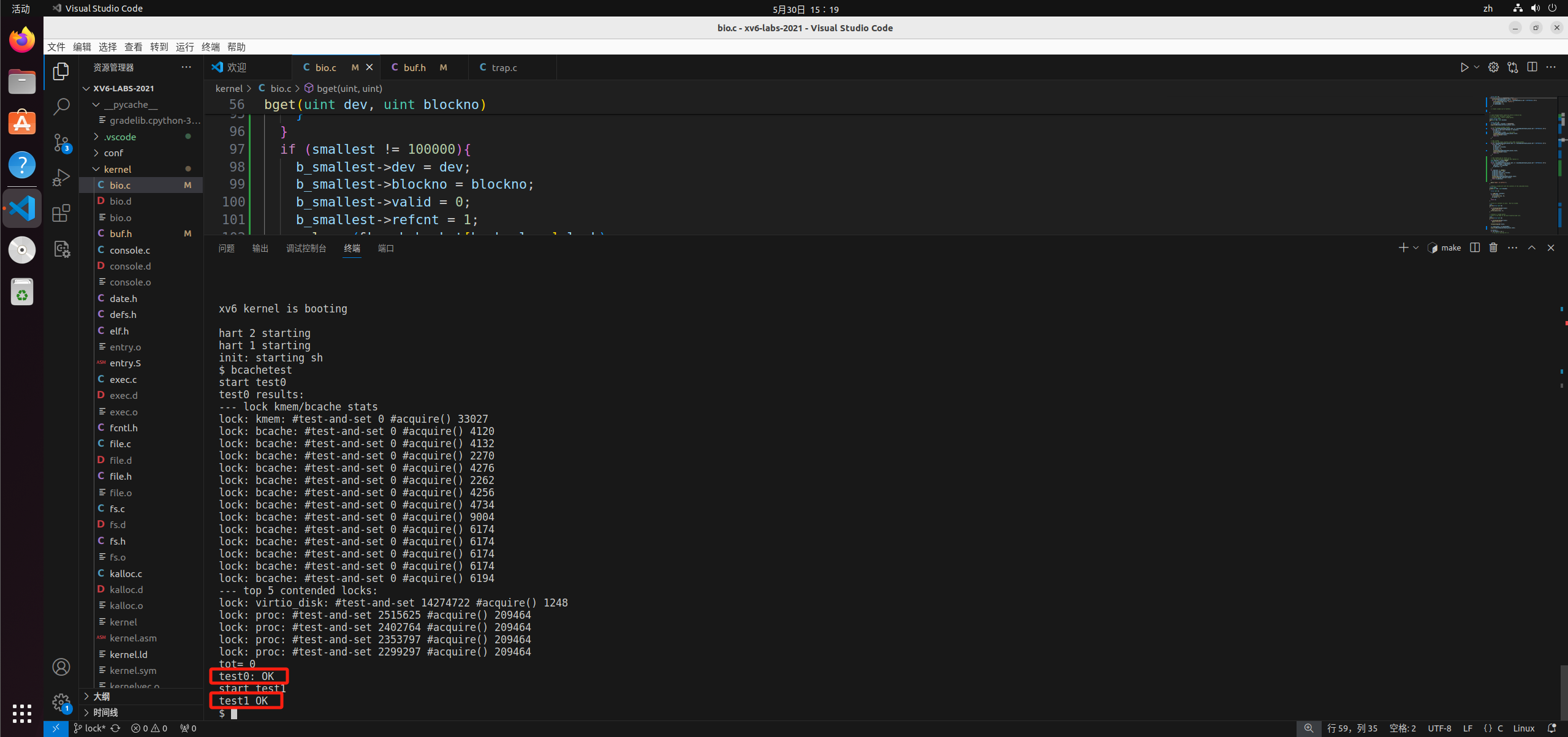
这是执行bcachetest的结果:
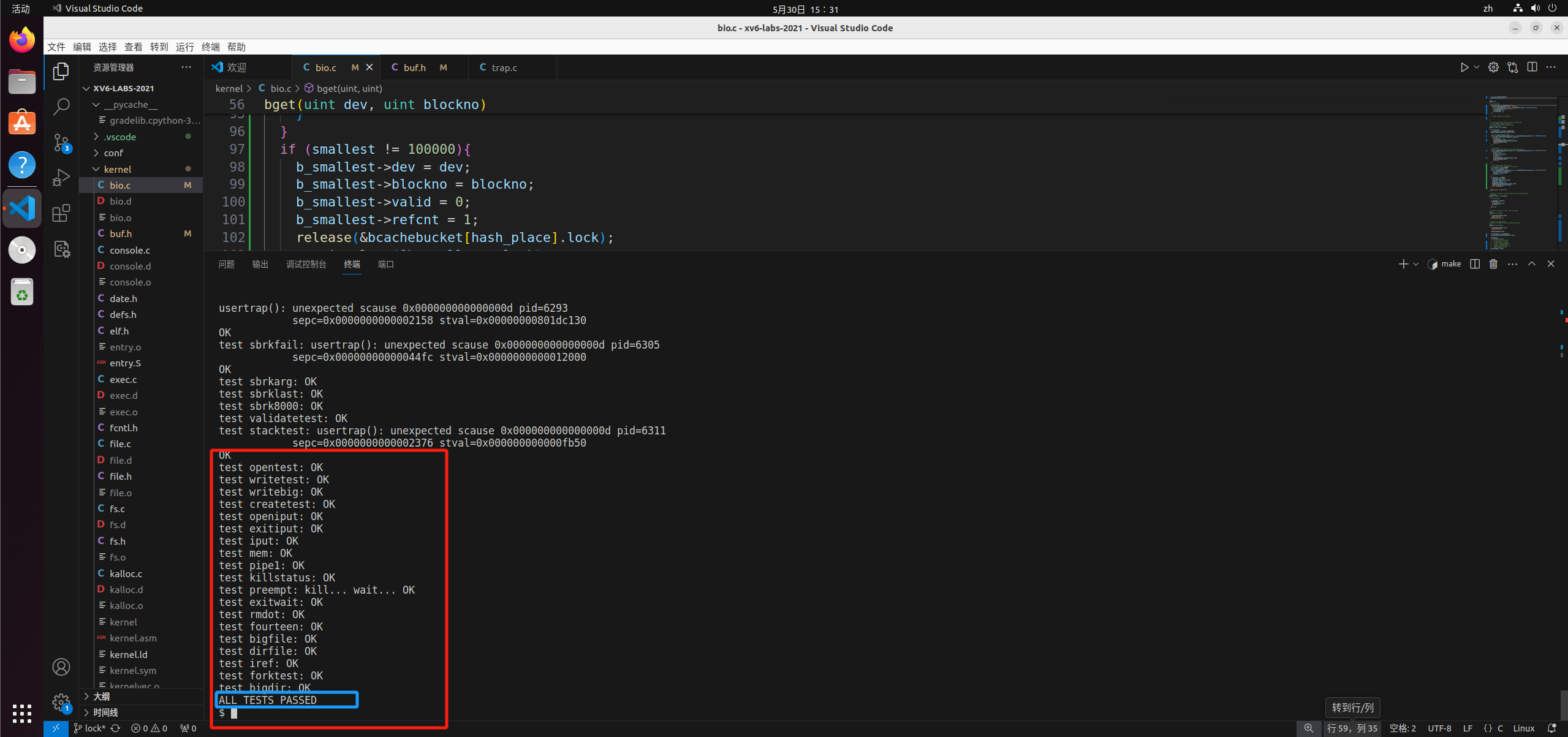
这是执行usertests的结果:
实验问题¶
这里记录了一些实验碰到的问题。
bget中的形式参数dev有什么含义?在函数中怎么处理它?
dev字段通常代表存储设备的设备号。
在操作系统的上下文中,dev字段用于标识缓冲区所关联的特定存储设备(例如硬盘、SSD等)。这样操作系统就可以将磁盘I/O操作路由到正确的设备驱动程序,并相应地管理这些缓冲区。
dev字段通常是一个无符号整数(uint)类型,代表存储设备的唯一标识符。这个标识符可能是主设备号/次设备号的组合,也可能是SCSI设备ID或其他特定于设备的编号方案。dev字段的具体解释取决于操作系统和存储子系统的具体实现。
在bget函数中,dev实际上并不是重点。在根据原bget函数进行修改时,实际上已经给出了dev的用法:在第一次遍历时寻找该缓冲区是否已经缓存,以及在后续的遍历中,将传入bget的dev赋值给缓冲区的dev。
为什么一定要使用固定数量的桶,就不能在双向链表的基础上进行修改,形成一个嵌套链表?
查阅网上相关资料,可以看到有人是这样完成了这个实验。但这样做并没有必要:如果我们能通过定长的桶数组完成任务,为什么还需要使用动态分配的桶呢?而且,动态分配实现的嵌套链表速度相比于可以使用索引直接查找的桶数组更慢,性能消耗更大,而且非常容易出bug——因为在移除节点的同时,还涉及多重锁的销毁,很容易造成死锁。
五、总结¶
通过本次锁的实验,我更加理解了锁的工作方式,以及将hash bucket应用于锁的方法:
- 将缓冲区分为多个桶,并在桶中存放多个块,这样就可以把一把大锁平摊在多个锁上,减少在多线程情况下对大锁的争用;
- 利用时间戳去实现LRU策略,相比于使用链表去实现LRU,更直接更快——链表需要进行两次地址调用,而时间戳只需要调用一次即可。
总而言之,本次实验使我收获颇丰,让我未来在操作系统和多线程编程中,更加注意锁的分配和释放,并且提高了避免死锁的意识。