操作系统实验报告3¶
一、实验目的¶
- 学习页表的实现机制
- 掌握用户拷贝数据到内核态的方法
二、实验内容¶
task1¶
实验要求:
一些操作系统(例如Linux)通过在用户空间和内核之间的只读区域共享数据来加速某些系统调用。这消除了在执行这些系统调用时需要跨内核的需求。为了帮助你了解如何将映射插入到页表中,你的第一个任务是为xv6中的getpid()系统调用实现这种优化。
实现过程:
显然这个实验的原理就是将一些数据存放在一个只读的共享空间中,这个空间位于内核和用户之间。这样做就可以使得在用户态需要一些简单的数据时,不需要再陷入内核(多次进行这种操作会带来非常庞大的上下文切换开销),而是直接从这个共享的只读空间中获得数据,加速了系统调用。
本次任务是要求改进getpid()。根据提示,我们需要在此页面的开头存储一个struct usyscall,并初始化它以存储当前页面的PID。
由于usyscall在memlayout.h中定义,转到memlayout中,可以发现这个页面中定义的usyscall非常简单:
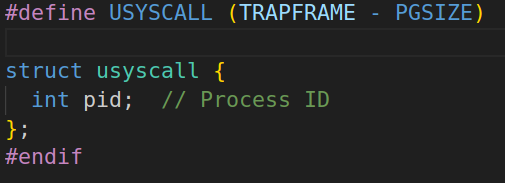
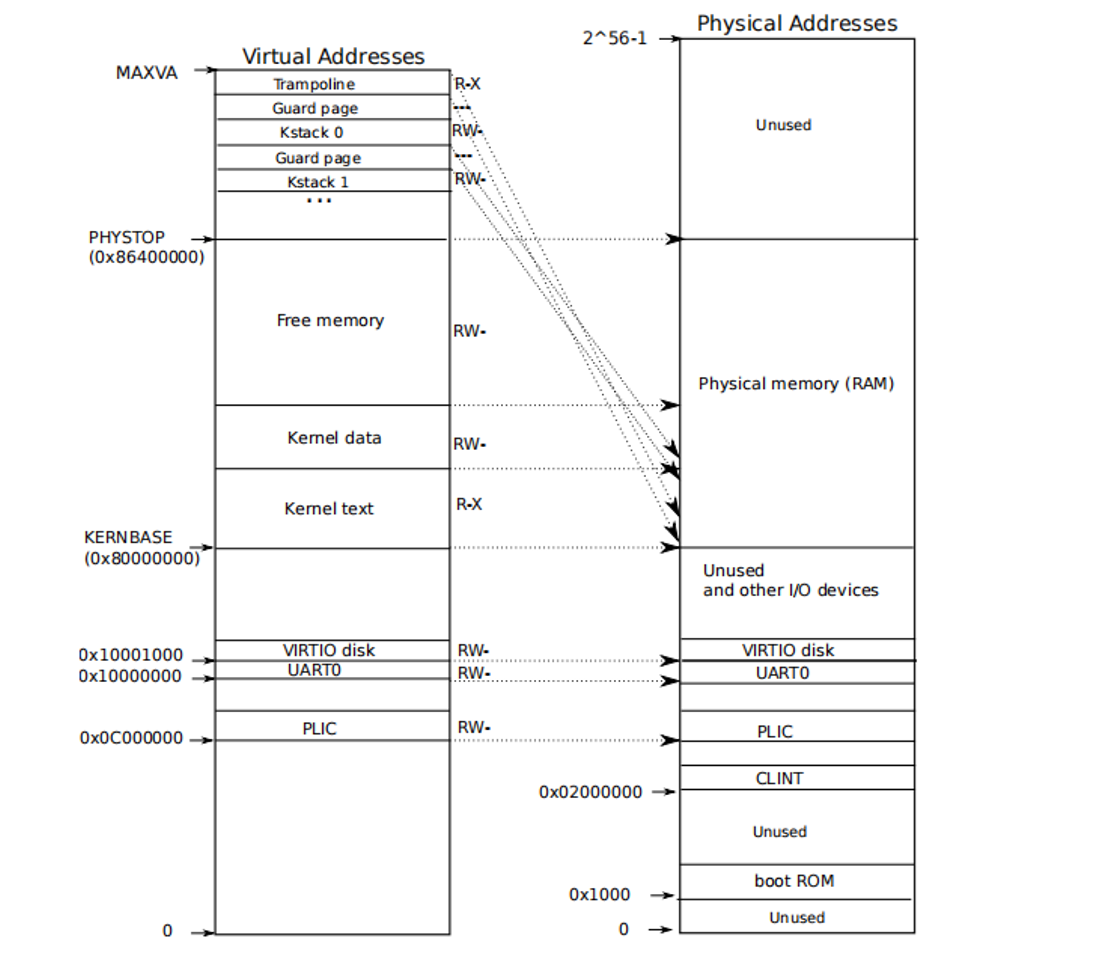
可以看到,USYSCALL是一个在TRAPFAME下方的一页,而内存空间的结构大致如图,可以发现这个空间大致是在内核和用户之间的:
 又由于在本次实验中,ugetpid已经在用户空间中给出,并且使用usyscall这个映射,因此不需要在重写getpid。
又由于在本次实验中,ugetpid已经在用户空间中给出,并且使用usyscall这个映射,因此不需要在重写getpid。
那么接下来,只需要在进程proc的结构体中添加一个usysycall类型的指针,保存共享页面的地址,并完善与之相关的功能即可。
首先,在kernel/proc.h中的proc结构体中添加地址:
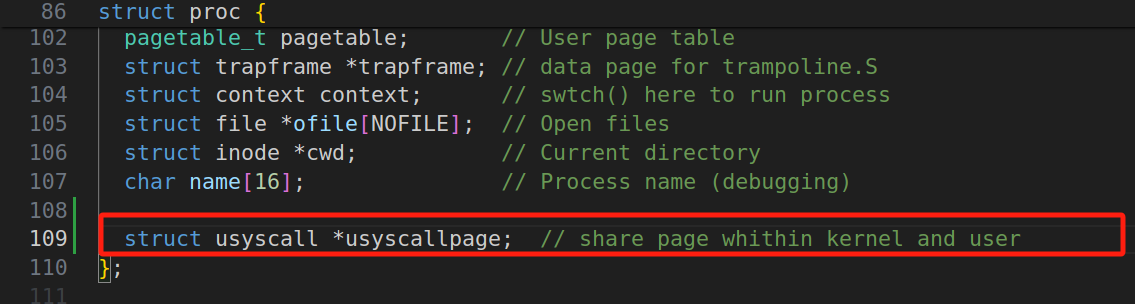
接下来,阅读proc.c,发现我们需要修改的功能大致分为两类:分配和释放。
分配初始空间¶
进入allocproc()函数,增加申请共享内存页。注意到必须满足allocproc()函数的实现逻辑,我们应该在获得锁之后的进程中实现申请共享页的功能,且最好是在found内实现。
allocproc(void)
{
struct proc *p;
for(p = proc; p < &proc[NPROC]; p++) {
acquire(&p->lock);
if(p->state == UNUSED) {
goto found;
} else {
release(&p->lock);
}
}
return 0;
found:
p->pid = allocpid();
p->state = USED;
// Allocate a trapframe page.
if((p->trapframe = (struct trapframe *)kalloc()) == 0){
freeproc(p);
release(&p->lock);
return 0;
}
// allocate a shared page.
if ((p->usyscallpage = (struct usyscall *)kalloc()) == 0) {
freeproc(p);
release(&p->lock);
return 0;
}
p->usyscallpage->pid = p->pid;
// Set up new context to start executing at forkret,
// which returns to user space.
memset(&p->context, 0, sizeof(p->context));
p->context.ra = (uint64)forkret; // 设置进程上下文的 ra (return address) 字段为 forkret 函数的地址。forkret 是一个返回到用户空间的函数
p->context.sp = p->kstack + PGSIZE; //设置进程上下文的 sp (stack pointer) 字段为内核栈的顶部地址,即 p->kstack + PGSIZE。这表示新进程的内核栈初始位置
解释一下该功能。我们添加的代码从allocate a shard page开始。首先调用kalloc为usyscallpage分配在内核中的空间,如果kalloc返回0(表示分配失败),则执行freeproc来释放进程控制块p,然后释放锁并返回0,表示进程分配失败。注意到kalloc是一个内核的内存分配器。
如果成功,那么就将当前进程的pid赋值到共享内存页中。
到这里pid相关的功能就完成得差不多了,但是为了实现共享内存页面的读取,我们还需要对进程的上下文进行操作,即进行进程管理。
接下来,使用memset函数将上下文(p->context)结构体全部初始化为0,确保进程的上下文是干净的,没有遗留数据。
再然后,将上下文中的return address(ra)初始化为forkret的地址,此时forkret是一个返回到用户空间的函数,它负责将进程切换回用户模式。也就是说,我们让进程在读取了共享页后,仍然能够切换回用户空间。
最后,我们把stack pointer(sp)指向p->kstack + PGSIZE,这是为了让新进程有一个干净的内核栈开始执行代码。至此,就完成了进程的所有初始化的补充内容。
构建PTE映射¶
接下来进入proc_pagetable函数。这个函数是用于建设虚拟空间到物理空间的映射的,由于我们新建立了一个共享内存页,因此我们需要让这个位于虚拟空间的内存页在物理空间页存在真实存储位置。
参照提示,使用mappages函数建立映射:
pagetable_t
proc_pagetable(struct proc *p)
{
pagetable_t pagetable;
// An empty page table.
pagetable = uvmcreate();
if(pagetable == 0)
return 0;
// map the trampoline code (for system call return)
// at the highest user virtual address.
// only the supervisor uses it, on the way
// to/from user space, so not PTE_U.
if(mappages(pagetable, TRAMPOLINE, PGSIZE,
(uint64)trampoline, PTE_R | PTE_X) < 0){
uvmfree(pagetable, 0);
return 0;
}
// map the trapframe just below TRAMPOLINE, for trampoline.S.
if(mappages(pagetable, TRAPFRAME, PGSIZE,
(uint64)(p->trapframe), PTE_R | PTE_W) < 0){
uvmunmap(pagetable, TRAMPOLINE, 1, 0);
uvmfree(pagetable, 0);
return 0;
}
if(mappages(pagetable, USYSCALL, PGSIZE, (uint64)(p->usyscallpage), PTE_R | PTE_U) < 0) {
uvmunmap(pagetable, TRAMPOLINE, 1, 0);
uvmfree(pagetable, 0);
return 0;
}
return pagetable;
}
解释mappages函数。pagetable是指要映射到的页表,ysyscall是指要映射到的虚拟地址,pgsize是指要映射的大小,这里是4KB,即一个页面的大小;(uint64)(p->usyscallpage)是指要映射的物理地址;最后的PTE_R|PTE_U是指页表的权限标志,这里设置为可读和用户可访问。
需要注意的是,如果我们执行到了这一步if,说明前文的trapframe创建成功。而若此时usyscallpage创建不成功,则需要在释放pagetable的同时,把上文的TRAMPOLINE页同时释放掉。
释放进程¶
static void
freeproc(struct proc *p) {
if(p->trapframe)
kfree((void*)p->trapframe);
p->trapframe = 0;
if(p->usyscallpage)
kfree((void *)p->usyscallpage);
p->usyscallpage = 0;
if(p->pagetable)
proc_freepagetable(p->pagetable, p->sz);
}
在释放进程时,直接调用kfree函数释放掉物理空间即可,并同时把该页初始化为0,便于下次使用。
取消PTE映射¶
非常关键的一点是,在我们释放进程时,没有取消之前的PTE映射。如果不进行任何操作的话,将会发生panic错误,即freewalk无法正确执行。因此,我们还需要在释放内存后解除PTE映射,具体操作为:
void
proc_freepagetable(pagetable_t pagetable, uint64 sz) {
uvmunmap(pagetable, TRAMPOLINE, 1, 0);
uvmunmap(pagetable, TRAPFRAME, 1, 0);
uvmunmap(pagetable, USYSCALL, 1, 0); // add
uvmfree(pagetable, sz);
}
即首先指出需要释放的页表,然后再给出USYSCALL取消映射的起始虚拟地址。参数里,其中的1是指需要取消映射的数量,而0是指是否要释放物理页面,为0则是不释放,1则是同时释放对应的物理页面。
至此,完成了对getpid()调用的优化。
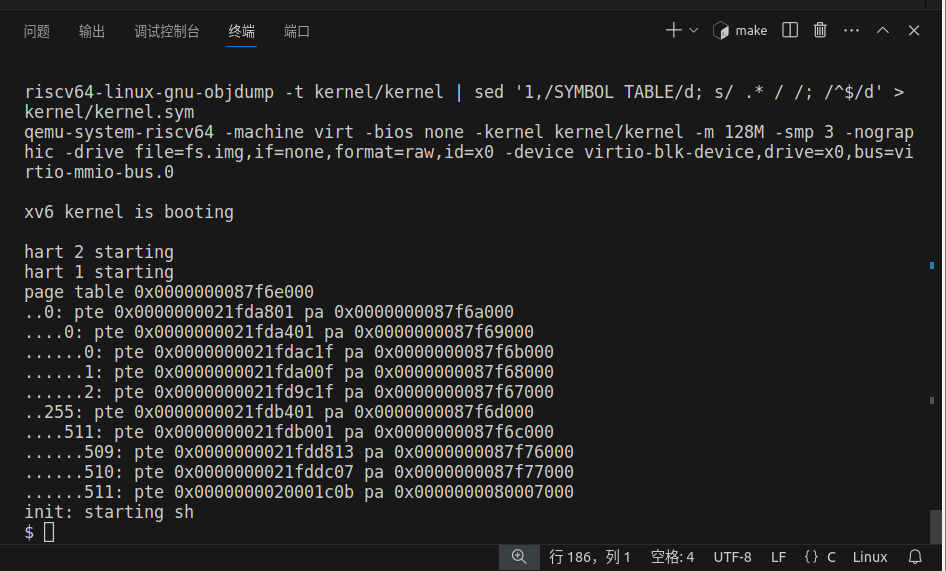
实验结果:
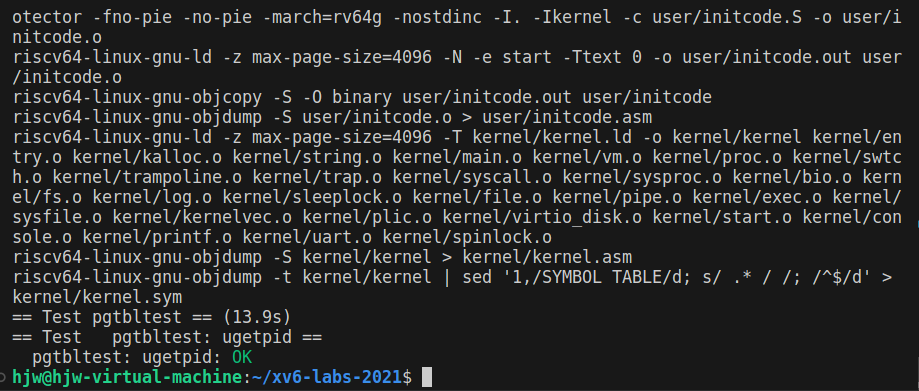
task2¶
实验要求:
为了帮助你可视化RISC-V页表,也许为了帮助将来的调试,你的第二个任务是写一个函数来输出页表的内容。
定义一个名为vmprint( )的函数。它有一个pagetable_t类型的参数,按下面描述的格式输出页表。在exec.c中的return argc;之前插入if(p->pid==1) vmprint(p->pagetable) 语句来输出第一个进程的页表。如果你通过了make grade的pte printout测试,这个实验你将获得满分。
page table 0x0000000087f6e000
..0: pte 0x0000000021fda801 pa 0x0000000087f6a000
.. ..0: pte 0x0000000021fda401 pa 0x0000000087f69000
.. .. ..0: pte 0x0000000021fdac1f pa 0x0000000087f6b000
.. .. ..1: pte 0x0000000021fda00f pa 0x0000000087f68000
.. .. ..2: pte 0x0000000021fd9c1f pa 0x0000000087f67000
..255: pte 0x0000000021fdb401 pa 0x0000000087f6d000
.. ..511: pte 0x0000000021fdb001 pa 0x0000000087f6c000
.. .. ..509: pte 0x0000000021fdd813 pa 0x0000000087f76000
.. .. ..510: pte 0x0000000021fddc07 pa 0x0000000087f77000
.. .. ..511: pte 0x0000000020001c0b pa 0x0000000080007000
提示:可以模仿freewalk()函数递归释放页表页的过程,去遍历页表。
实现过程:
首先根据提示,我们去观察一下freewalk函数。
void
freewalk(pagetable_t pagetable)
{
// there are 2^9 = 512 PTEs in a page table.
for(int i = 0; i < 512; i++){
pte_t pte = pagetable[i];
if((pte & PTE_V) && (pte & (PTE_R|PTE_W|PTE_X)) == 0){
// this PTE points to a lower-level page table.
uint64 child = PTE2PA(pte);
freewalk((pagetable_t)child);
pagetable[i] = 0;
} else if(pte & PTE_V){
panic("freewalk: leaf");
}
}
kfree((void*)pagetable);
首先,这里有512个页表项,我们通过for循环遍历所有PTE。接下来,获取当前PTE的值,并检查其有效位(PTE_V)是否置位,以及数据/指令位是否全部为0.如果是,就说明当前PTE指向一个子页表,需要递归地释放。在这种情况下,需要先使用PTE2PA( )从PTE中提取出子页表的地址,再递归调用freewalk释放该子页表。最后,将当前页PTE清零,以标记该项已被释放。
如果当前PTE的有效位为1,但是不满足递归释放条件,则需要panic()。
最后,再遍历完整个页表后,用kfree释放页表自身占用的内存空间。
了解完freewalk函数,很显然我们只需要在freewalk的基础上修改一些功能即可。先看完整的vmprint函数:
static int printdeep = 0;
void
vmprint(pagetable_t pagetable)
{
if (printdeep == 0)
printf("page table %p\n", (uint64)pagetable);
for (int i = 0; i < 512; i++) {
pte_t pte = pagetable[i];
if (pte & PTE_V) {
for (int j = 0; j <= printdeep; j++) {
printf("..");
}
printf("%d: pte %p pa %p\n", i, (uint64)pte, (uint64)PTE2PA(pte)); //PTE2PA() 宏用于从页表项中提取物理页面地址。
}
// pintes to lower-level page table
if((pte & PTE_V) && (pte & (PTE_R|PTE_W|PTE_X)) == 0){ //如果页表项有效(PTE_V)且没有设置读/写/执行权限位,则说明它指向一个下级页表
printdeep++;
uint64 child_pa = PTE2PA(pte);
vmprint((pagetable_t)child_pa);
printdeep--;
}
}
}
首先我们新增了一个printdeep的整型变量,这个静态变量用于指示当前打印页的深度信息,如果需要进入下一级页表就加一,在函数返回时就减一。
接下来,需要遍历512个页。参照freewalk的判定条件去递归遍历页表。由于我们需要格式化输出,因此在进入需要遍历的页后,首先要根据当前深度打印相应数量的". .",再进行格式化输出(%p是c语言中用于十六进制格式打印的符号)。
如果该页指向一个更低的子页,则先参见freewalk的判定条件先确认递归是合法的,再增加printdeep的层级,并获取子页的物理地址,然后再次递归调用vmprint。注意出函数时需要将递归层数减一,因为这相当于回到了当前层。
实验结果:
三、使用环境¶
ubuntu虚拟机中的xv6系统。
四、实验过程及结果¶
这里记录了一些在实验中遇到的问题。
最开始没有编译成功,怎么解决?¶
这是因为我最初的git操作没有执行完整。在开启本实验之前,需要先git fetch,再git checkout pgtbl。而想要完成git checkout,又需要先提交全部已修改文件。由于这个虚拟机上的邮箱、仓库等完全没有进行初始化,导致提交文件这一步就出现了bug。回头解决完这一切,又忘记第一步时git fetch,因此导致mamlayout.h中的usyscall没有正确连接。
解决方法是使用git branch -d xxxx(name),对该本地分支进行删除。当然,想要删除分支又需要提交文件,为了再造成未知错误,将命令行参数的-d修改为-D,对该分支进行强制删除。而后再重启一次计算机,就可以从头开始,正常完成实验流程了。
第一次实验failed,原因是什么?¶
因为我没有注意到alloc函数中,所有创建操作都是在锁中进行的。我把分配操作写到了锁外,造成了一些未知的错误。
五、总结¶
通过本次实验,我学到了以下知识:
- 共享页的使用。如果需要对getpid进行加速,也就是针对系统调用的性能瓶颈,设计了一种缓存优化方案,避免从内核态中读取pid信息,减少了昂贵的系统调用开销。
- 了解到页表的具体实现不仅仅是需要分配空间和释放空间,还需要建立PTE映射和解除PTE映射。同时也学习到对应函数的使用方法(即mappages和uvmunmap函数)。
- 理解了freewalk函数的逻辑,并且掌握了递归遍历页表的方式,这种思想还可以运用到更多算法层面的内容,丰富了我的思维库。
- 了解到页表权限的设置方式,懂得利用布尔运算符更简洁地进行操作。