第1组-Hadoop¶
实验1¶
上机实践名称: 准备工作
上机实践日期:2024年3月6日
问题1:主机名修改后无论是什么命令都报错Name or service not known。
在配置多台主机之间的免密登录时,理论上来说,根据实验指导文档,修改完/etc/sudoers文件之后就可以通过sudo hostnamectl set-hostname ecnu01将主机名修改为ecnu01,这一步也没有问题,但是之后输入所有的命令都出现Name or service not known而无法进行了。这主要是因为我没有在修改好主机名之前便添加映射,只要先在/etc/hosts中添加映射再去利用hostnamectl修改主机名,这个问题便不会出现了。
问题2:不在 sudoers 文件中,此事将被报告。
我最开始创建dase-dis用户是在ubuntu用户下通过sudo useradd dase-dis创建的,但是转到dase-dis用户之后使用sudo赋权时就出现了这样的报错。结合水杉上实验的演示视频,我发现正常的创建用户步骤是这样的(假定当前的用户是ubuntu):
- sudo useradd -m dase-dis -d /home/dase-dis -s /bin/bash
- sudo passwd dase-dis(修改dase-dis密码)
- sudo passwd root(修改root密码)接下来su登录root
4.vim /etc/sudoers在#User privilege specification中加入:dase-dis ALL=(ALL) ALL 保存文件
5.之后su dase-dis之后sudo赋权就正常了。
问题3:wget报错:解析代理服务器 URL https://
在检查了一下自己wget的链接发现没有什么问题之后,我觉得出现这个问题的主要原因是没有给wget赋予相应的权限。在wget之前加入sudo之后下载任务便正常开始了。
问题4:在第二个终端中jps not found
出现这个问题时我考虑到了环境变量可能还没来得及重新加载,输入source /etc/profile之后jps命令便可以正常使用了。
问题5:IDEA中Build程序时出现错误
经过一段时间的排查,我才发现自己的language level和jdk版本不适配。由于我使用的是openjdk-21,所以需要修改project structure的language level,使得Modules和Project中language level版本一致。具体来说,我把SDK中jdk版本切换到了1.8,然后再改一下Modules和Project中的language level使之为8就行了。
问题6:su dase-dis时Password: su: Authentication failure
查阅网上的资料后,我发现这是因为useradd 创建一个新用户但没有设置密码时,该用户并无有效的密码,因此我不能用 su 切换到该用户。我在sudo passwd dase-dis修改dase-dis的密码之后,再su就不报错了。
实验2¶
上机实践名称: Hadoop 1.x部署
上机实践日期:2024年3月13日
问题1:在云主机上新建用户后终端只显示$
经过排查,我发现自己新建用户时输入的命令是sudo useradd -m dase-dis -d /home/dase-dis 没有添加-s /bin/bash,加上这个选项之后问题便解决了。
问题2:Hadoop启动时Error: JAVA_HOME is not set and could not be found
为了解决这个问题,我觉得JAVA_HOME环境变量可能还没有生效,就去source /etc/profile,但是依然没有解决。然后我修改/etc/hadoop/hadoop-env.sh中设JAVA_HOME为绝对路径,即export JAVA_HOME=/usr/local/jdk1.8,然后再运行Hadoop发现能正常运行了。
问题3:我在dase-dis用户运行wordcount时,另外一个终端如果是dase-dis用户jps什么都没有,但是如果是root用户就能看到RunJar进程。
经过漫长的检查,我终于发现自己的hadoop命令之前错误地添加了一个sudo,就比如原本应该是./bin/hadoop jar hadoop-examples-1.2.1.jar wordcount ~/input/pd.train ~/output/wordcount,这如果是dase-dis运行,另外一个终端如果再用dase-dis登录当然jps是能看到wordcount运行着的。但如果在此之前加一个sudo,运行命令的便是root了,所以另外一个终端用dase-dis再jps就什么也看不到了。
为什么我还要再加一个sudo呢?这主要是因为权限问题,不加sudo的话直接用dase-dis其实hadoop是跑不起来的。要想解决这个问题,我先在dase-dis的工作目录下sudo chmod -R 777 ~/hadoop-1.2.1修改权限,然后不带sudo运行hadoop即可。
问题4:jps能看到secondarynamenode但是竟然看不到namenode
我不小心多次格式化了namenode,然后我在启动hdfs后,进程列表中只有secondarynamenode但却没namenode进程,之后的各项操作也都是报错。经过查阅namenode.log日志,我发现自己的tmp文件夹已经损坏,需要杀死所有进程,把tmp文件全部删除并重新格式化namenode。我这样做并重启了hdfs服务之后,进程列表里又可以看见namenode了
问题5:运行时出现Java Heap Space异常
经过助教学长的提醒,我知道了这个问题是因为进程的堆内存不足所导致的。我调大了虚拟机的内存,从原来的1G调整到了16G,这个问题还是没有解决。后来经过沟通,我才知道如果在云主机上做这个实验不能修改hostname,保持它不变的情况下我再以一个较大的内存来做,就正常了。
问题6:即便镜像中的云主机已经配置了免密登录,但是从之新建的云主机验证时还是出错了。
具体来说,我觉得每次从镜像中创建的云主机存在一些差异,彼此之间是不太一样的,所以镜像中那个.ssh文件中记录的密钥信息并不匹配。因此,我就把.ssh文件重置了一下,然后按照免密登录的配置流程操作了一下,问题就解决了。
实验3¶
上机实践名称: Hadoop 2部署
上机实践日期:2024年3月27日
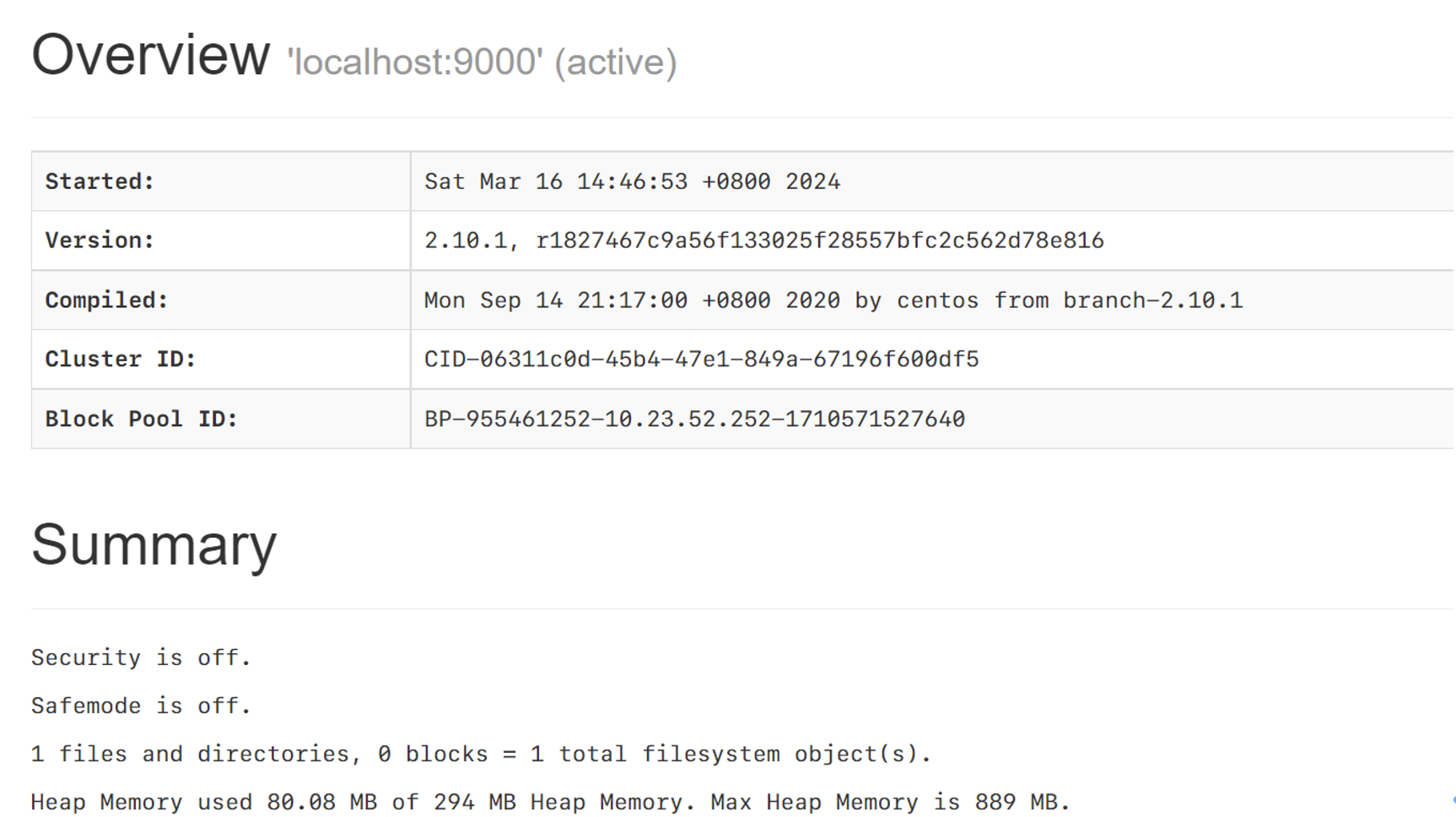
问题1:在浏览器中输入localhost:50070查看结点内部情况时发现无法访问
这主要是因为自己的浏览器是本地浏览器,而不是运行HDFS的云主机。输入xxx:50070问题便解决了(xxx为云主机的外网ip,要现在防火墙中把所有的端口打开)。
问题2:分布式实验时,四台主机单机和它们互相之间的免密钥登录设置后还是需要输入密码
经过一段时间的排查,我发现自己错误的原因是authorized被错打成authorised了,然后就一错再错导致免密登录并没有真的设置成功。
问题3:多次格式化namenode导致启动HDFS后ecnu01中没有namenode进程
在详细查看了namenode.log日志后,我发现tmp文件夹已经损坏。我应该杀死所有进程之后,把四台主机上的tmp文件全部删除并重新格式化。我在这样做并重启了HDFS服务,发现ecnu01的进程列表里又有namenode了。
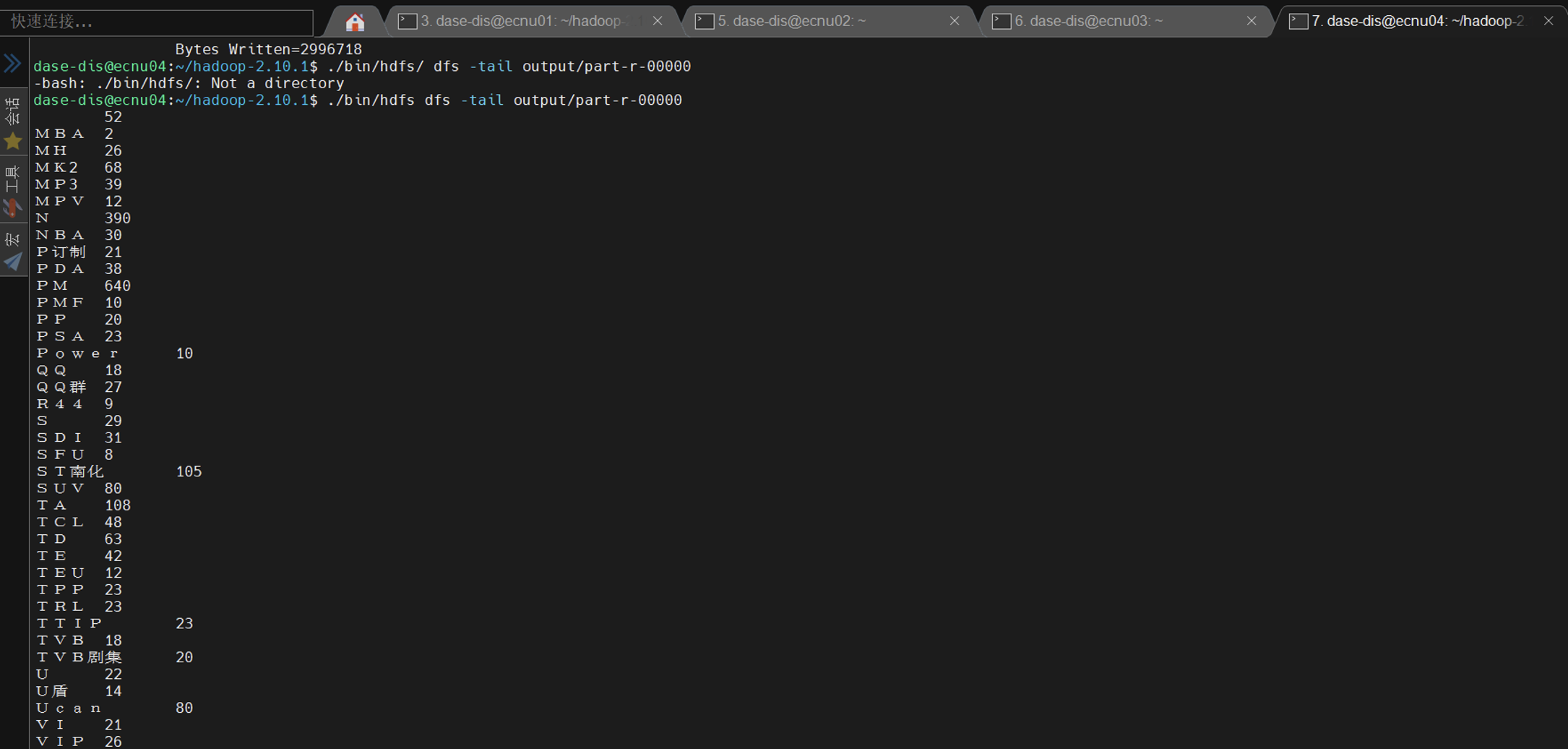
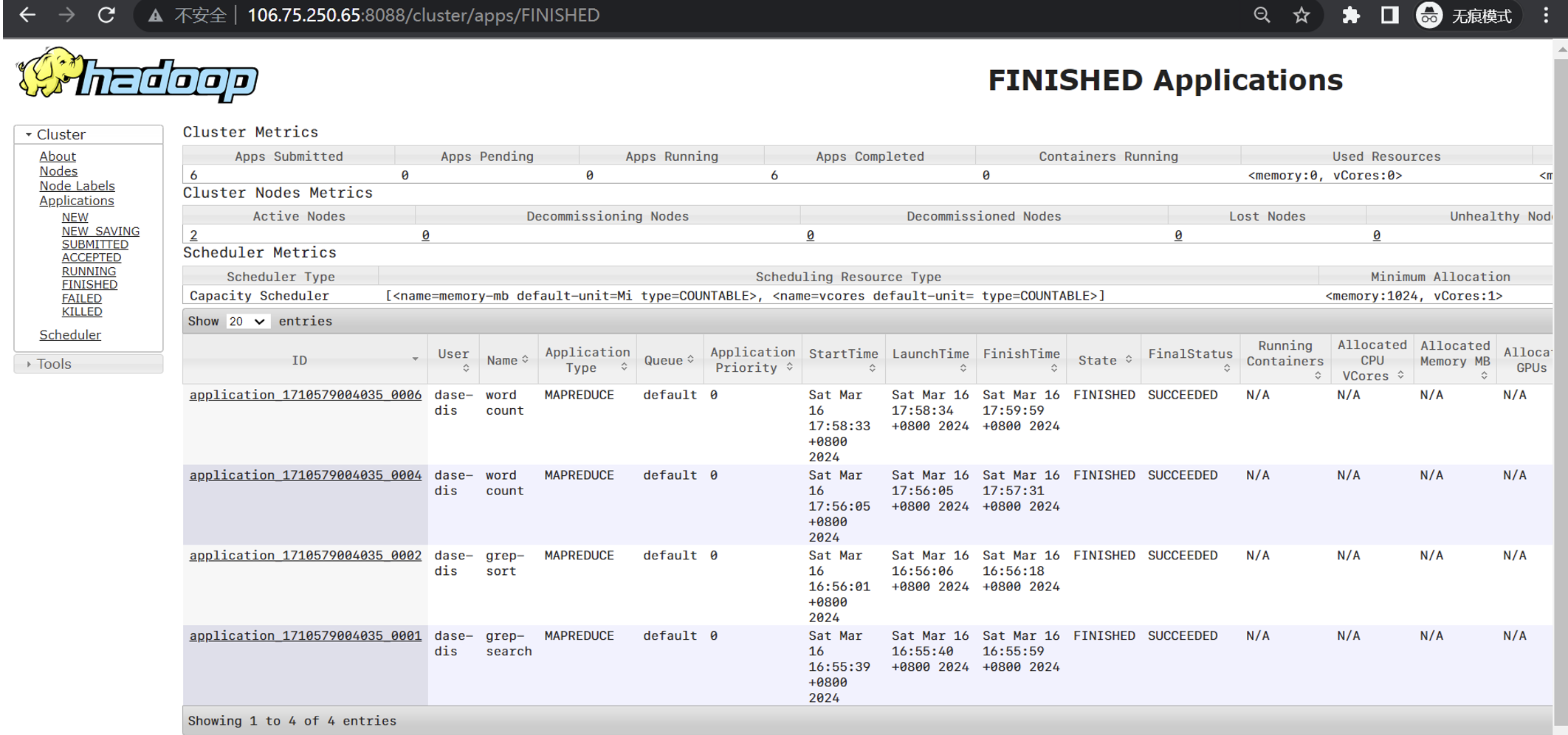
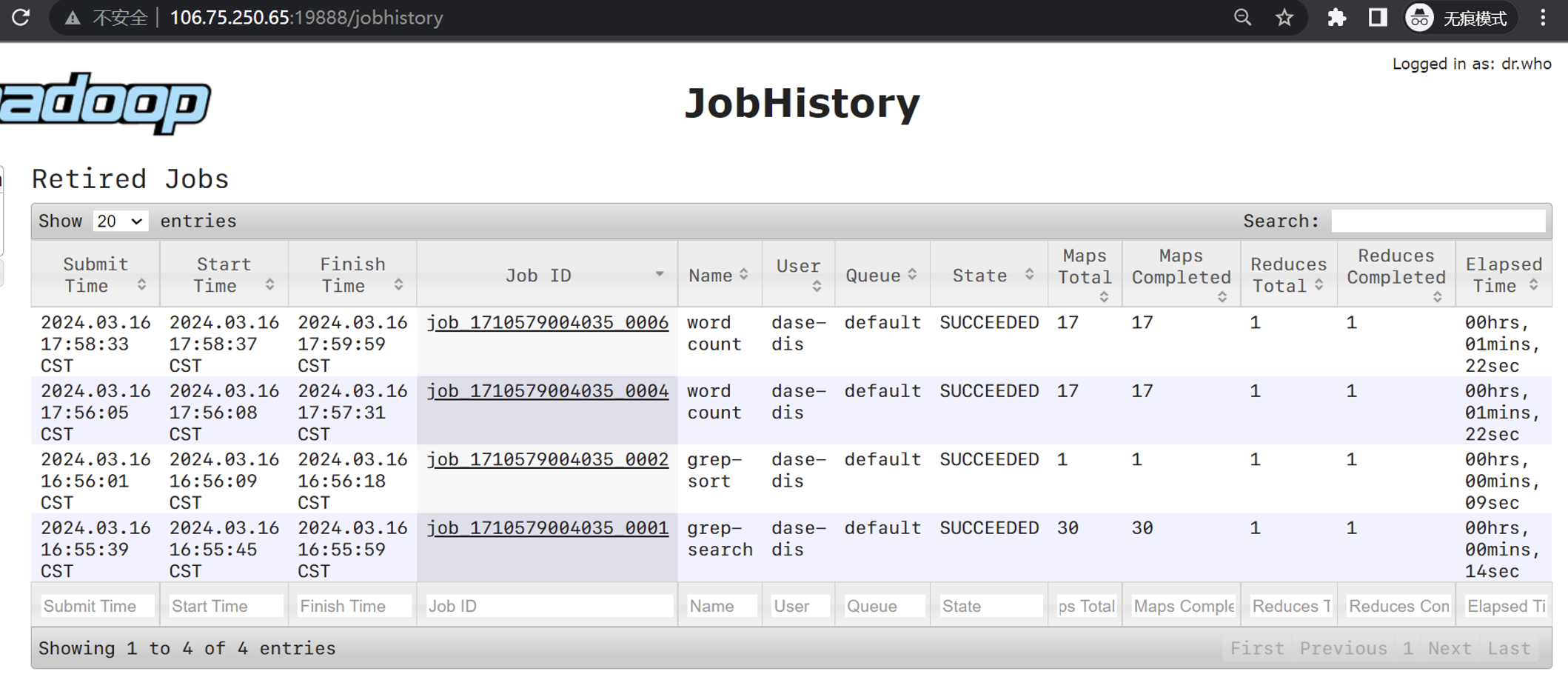
其实这个实验我严格按照实验操作文档一步一步去做,并没有出现很多不好解决的问题。在分布式实验时,grep从客户端提交之后运行:
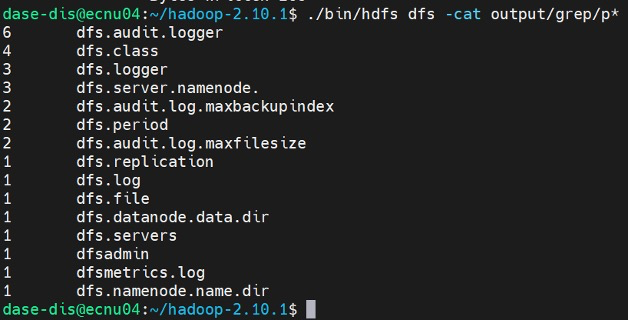
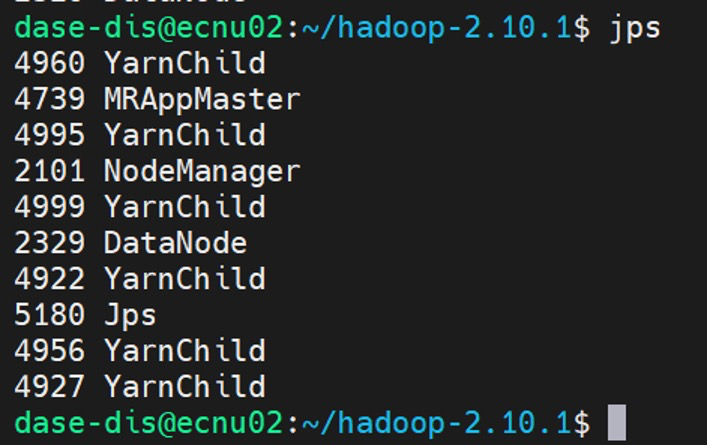
在运行wordcount时从节点的进程信息:
实验4¶
上机实践名称: MapReduce 2编程
上机实践日期:2024年4月17日
问题1:org.apache.hadoop.io.nativeio.NativeIO$Windows.access0
由于 Windows 不支持 HDFS,因此我们在 Windows 本地运行 MapReduce 程序时需要使用 winutils.exe 文件(winutils.exe 提供了一个包装器)
1.如果本地没有安装 winutils.exe,那首先就需要我们下载 winutils.exe 和 hadoop.dll 这两个文件(https://github.com/steveloughran/winutils,选择对应的hadoop版本)。
- 然后,将上面提到的两个文件拷贝到本地 $HADOOP_HOME/bin 目录下(需要先安装 Hadoop 并配置好 HADOOP_HOME 环境变量),通常到这里就可以解决上述问题,如果仍然报错,可以尝试重启系统,让环境变量生效。
- 如果通过步骤2仍然解决不了问题,那么可能是系统问题,可以将 hadoop.dll 拷贝到 C:/Windows/System32 目录下。
问题2:Exception in thread "main" java.lang.UnsupportedClassVersionError: cn/edu/ecnu/mapreduce/example/java/wordcount/WordCount has been compiled by a more recent version of the Java Runtime (class file version 61.0), this version of the Java Runtime only recognizes class file versions up to 52.0
我查了一下Java的版本对应情况,是这样的——Java 8 (52)、Java 17 (61)。看来这个问题的原因是因为自己的JDK版本无法匹配到程序的版本。所以我在IDEA中下载了版本为jdk1.8的SDK,尝试了几次之后发现只有Azul Zulu version1.8.0_402是可以下载的。安装之后再配置好对应的SDK,该问题就解决了。
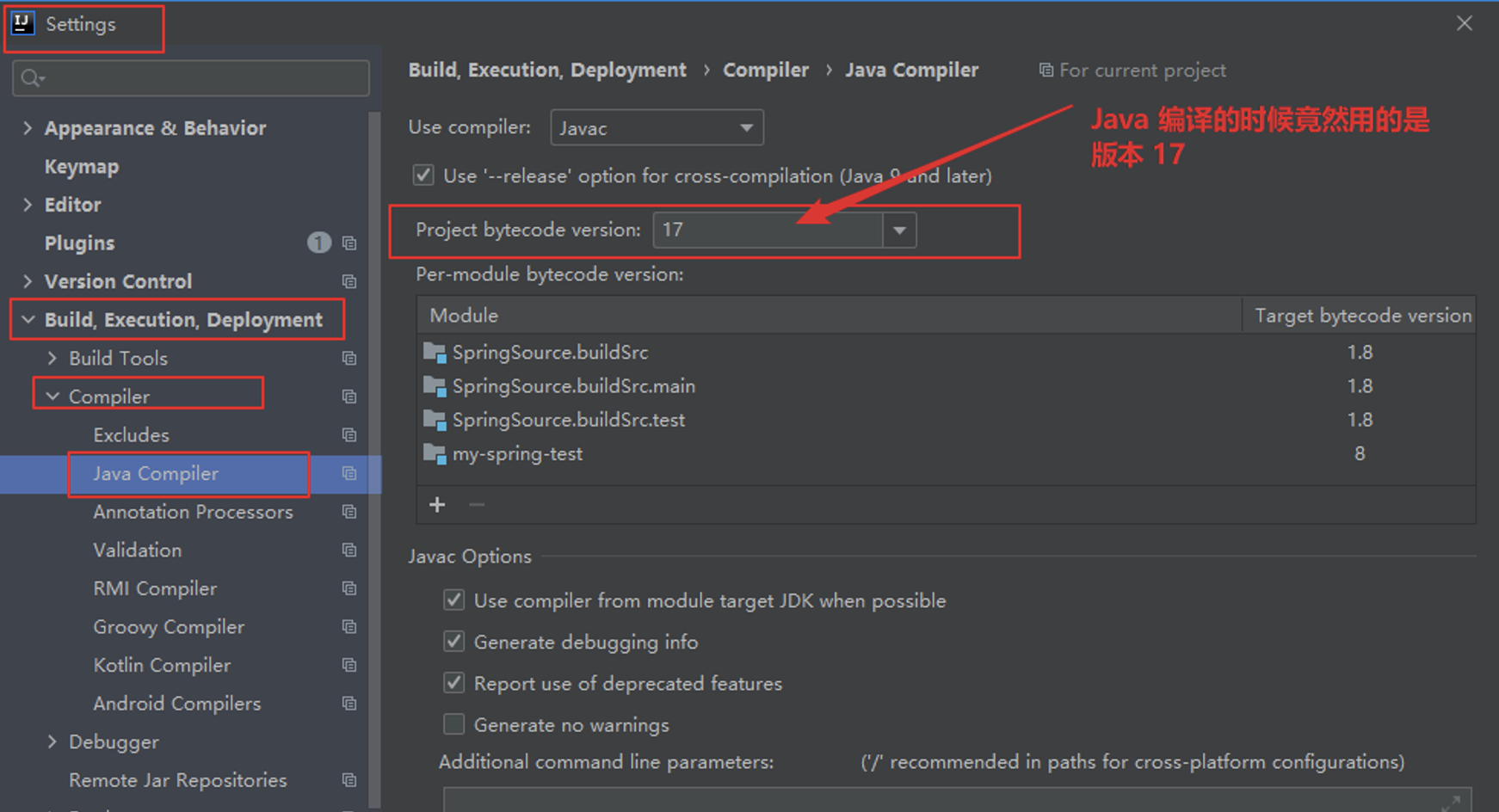
问题3:idea 报错:无效的目标发行版:17 的解决办法
原因就是 JDK 版本不对。从 IDEA 编辑器中可以找到问题的原因所在,如下图是编辑器里的配置. 将 Settings --> Build, Execution, Deployment --> Complier --> Java Complier 配置下的 Project bytecode version: 17 改为 与 项目使用的 JDK 版本一样即可。
问题4:jar包里没有WordCount类
这是因为自己没有把类的名称写全,我应该把package的名称放在类的前面。于是,我把类的名称从WordCount改成了cn.edu.ecnu.mapreduce.example.java.wordcount.WordCount,本地调试好的程序就能顺利地在云主机上运行了。
感觉这个实验和实验3还是挺相近的,我在实验过程中也是严格按照文档去做,并没有遇到什么太大的问题。单机伪分布式运行结束之后的结果和分布式运行结束之后的结果是一样的: